 Zhen Wang
Zhen Wang Xiangnan He
Xiangnan He Xian Li
Xian Li- Agricultural Information Institute, Chinese Academy of Agricultural Sciences, Beijing, China
Introduction: Leaf phenotypes are key indicators of plant growth status. Existing deep learning–based leaf skeletonization typically requires extensive manual labeling, long training, and predefined keypoints, which limits scalability. We developed a training-free and label-free approach that connects spontaneously detected keypoints to generate leaf skeletons for leafy plants.
Methods: The method comprises random seed-point generation and adaptive keypoint connection. For plants with random leaf morphology, we determine a threshold for the angle difference among any three consecutive adjacent points and iteratively identify keypoints within circular search neighborhoods to trace leaf skeletons. For plants with regular leaf morphology, we fit the skeleton trajectory by minimizing curvature. We validated the approach on vertical and front-view images of orchids (covering random and regular morphological cases) and extracted five phenotypic parameters from the resulting skeletons. Generalization was further assessed on a maize image dataset.
Results: On orchid images, the proposed approach achieved an average curvature fitting error of 0.12 and an average leaf recall of 92%. Five orchid phenotypic parameters were accurately derived from the skeletons. The method also showed effective skeletonization on maize, indicating cross-species applicability.
Discussion: By eliminating manual labels and training, this approach reduces annotation effort and computational overhead while enabling precise geometric phenotype calculation from skeleton-based keypoints. Its effectiveness on both randomly distributed and regularly shaped leafy plants suggests suitability for high-throughput plant phenotyping workflows.
1 Introduction
Leaf physiological and morphological phenotypes are associated with plant growth status (Kolhar and Jagtap, 2023; Li et al., 2020), such as plant height (Liu et al., 2023; Zhang et al., 2024), leaf shape (Li et al., 2020), leaves consistency and color (Nyonje et al., 2021). Phenotypic information can be extracted manually or through computer-based automated methods. Manual phenotype measurement based on rulers is time-consuming and difficult to accurately capture complex phenotypes (Cembrowska-Lech et al., 2023). The consistency of leaf morphology can only be perceived subjectively. Computer-based phenotyping generally involves skeletonization and phenotype extraction. Skeletonization refers to simplifying each leaf region into a centerline polyline for geometric property calculations. In this study, skeletonization simplifies leaves into keypoints and skeleton, enabling efficient and precise geometric calculations of phenotypes without considering complex leaf details. Automated keypoint detection and skeletonization using intelligent algorithms can quantify leaf phenotypes and reflect the growth status, providing more efficient and intelligent decision support for precision agriculture (Jiang and Li, 2020). Deep learning has therefore become a mainstay in image-based phenotyping, in part because transfer learning, domain adaptation, and self-/few-shot strategies can support generalization across datasets and conditions while reducing annotation needs (Li et al., 2023; Ogidi et al., 2023; Sheikh et al., 2024).
Deep learning‐based methods for keypoints detection and skeletonization have been widely applied to crop phenotyping, providing valuable insights into plant morphology. For instance, point cloud based phenotyping approaches—using data acquired via LiDAR (Zhang et al., 2024), Visual Structure From Motion (VisualSFM) (Zhang et al., 2024), or Multi-View Stereo (MVS) (Murata and Noshita, 2024)—offer detailed 3D reconstructions, although they often require specialized equipment and involve higher technical and economic costs. For image data, methods such as YOLOv7-pose have been employed to extract keypoints from individual rice plants to facilitate stem-leaf angle measurements (Seng et al., 2024). In addition, lightweight variants like YOLOv7-SlimPose—enhanced with modules such as GSConv and GSIN and utilizing modified loss functions like MPDIoU—have been applied to detect multiple keypoints on maize leaves and stems, enabling the extraction of phenotypes including plant height, leaf-stem angle, leaf length, and ear position (Gao et al., 2024). Similarly, AngleNet has been used to extract keypoints on maize leaves (targeting the midrib, stem, and near the leaf neck) to quantify leaf angles (Xiang et al., 2023), and a stacked hourglass network (SHN) has been applied for locating keypoints on soybean leaves to automatically compute distances and angles between them (Zhu et al., 2020). While predefined keypoint sets can be effective, they may be less flexible for multi-leaf species with variable leaf counts or heavy occlusion. Recent structure-aware pose and dense-keypoint models partially mitigate this but challenges remain in complex canopies. Notably, several recent pose frameworks in crops can infer flexible landmark sets or even recover skeletal topology under occlusion. For example, PFLO reconstructs field maize poses with a YOLO-based head, and the bottom-up DEKR-SPrior leverages structural priors to detect variable keypoints in dense organs, mitigating the limitations of strictly pre-annotated keypoint templates (Pan et al., 2025).
While these approaches have significantly advanced plant phenotyping, many pipelines still supervise a fixed set of landmarks—particularly in multi-leaf canopies, although topology-flexible models partly alleviate this constraint. This design can sometimes limit flexibility when dealing with multi-leaf plants that exhibit considerable variability, such as differences in leaf count or challenges arising from occlusion. To address more complex plant structures, alternative strategies have been explored. For example, CenterNet has been applied to leaf counting in beet plants with an arbitrary number of leaves (Weyler et al., 2021), although overlapping leaves occasionally lead to false positives or missed detections. Similarly, SDNet, which employs an encoder-decoder architecture combined with a structural reconstruction algorithm (SRA), has been used for multi-instance detection, leaf counting, and phenotyping in maize and soybean (Lac et al., 2021), yet its ability to extract detailed keypoint information might be constrained under highly complex scenarios. More recently, the DEKR-SPrior model has been proposed to enhance keypoint detection by increasing the number of detected points and integrating prior structural knowledge through cosine similarity, thereby improving discrimination in dense leaf regions (He et al., 2024). Additionally, a Point-Line Net based on the Mask R-CNN framework has been developed to recognize maize field RGB images and determine both the number and growth trajectories of leaves and stalks, achieving promising performance (81.5% mAP50) (Liu et al., 2024). It should be noted that cross-species deployment of deep networks often benefits from fine-tuning or domain adaptation rather than always requiring full retraining. Recent work shows that synthetic-to-real adaptation, contrastive/self-supervised pretraining, and few-shot transfer can substantially reduce labeling demands and improve robustness across domains (Lagergren et al., 2023; Shi et al., 2022; Zhang et al., 2021).
Classical skeletonization techniques have also been applied to plant leaves. Medial-axis based skeletons are attractive for their geometric interpretability but are notoriously sensitive to small boundary perturbations (each local change on the silhouette can spawn spurious branches), requiring aggressive denoising and topology repairs under occlusion or gaps in the mask (Bucksch, 2014). Morphology-based thinning pipelines, widely available in plant phenotyping toolkits, routinely produce barbs/spurs whose prevalence strongly depends on mask quality and must be pruned with heuristic rules, which propagates instability to downstream trait calculations (PlantCV Morphology Tutorial). Active-contour (snake) models have been used to segment and track leaves in time-lapse data. However, they demand careful initialization and shape priors and may converge to local minima in scenes with weak edges or strong overlap, which limits their ability to deliver midrib-aligned skeletons and a variable number of keypoints needed for phenotyping (De Vylder et al., 2011; Scharr et al., 2016).
In this study, a training-free, spontaneous keypoint-connection algorithm is proposed to overcome the limitations of boundary-driven or annotation-dependent skeletonization. “Training-free” means that no model parameters are learned and no annotated data are required. “Spontaneous” refers to the fact that keypoints are not predefined. Instead, candidate interior points are sampled at runtime and connected according to curvature, angle-difference, and convexity rules to yield a single polyline per leaf without using templates or skeleton priors. Leaf regions are first isolated by color thresholding and morphological operations. Instead of predefined keypoints, randomly sampled interior points are linked through a set of connection rules. For irregular morphologies, an orientation-guided local search with an adaptive angle-difference threshold incrementally traces keypoints while halving the search space at every step, whereas for regular morphologies a convexity-constrained curvature-minimization scheme yields smooth, midrib-consistent polylines. This algorithm is positioned as complementary to learning-based pipelines—particularly useful in annotation-scarce settings, for rapid cross-species deployment, or when the keypoint graph is unknown or variable—rather than as a universal replacement. By dispensing with fixed keypoint counts, skeleton templates, and lengthy training, the method remains robust to edge defects, partial occlusions, and variable leaf numbers, thereby generalizing across species and enabling direct, geometry-accurate phenotype extraction for leafy plants with complex architectures.
2 Materials and methods
2.1 Image dataset acquisition
The vertical (top view) and front views of leafy orchids effectively capture the randomness and regularity of leaf morphology, respectively (Guan et al., 2011; Rodrigues et al., 2013). To obtain these complementary perspectives, a multi-view automatic acquisition device was designed for capturing images of Cymbidium goeringii (Rchb. f.) (Figure 1A). While the front view provides more detailed phenotypic information and thus requires a higher resolution, the proposed algorithm is capable of processing images with varying resolutions.
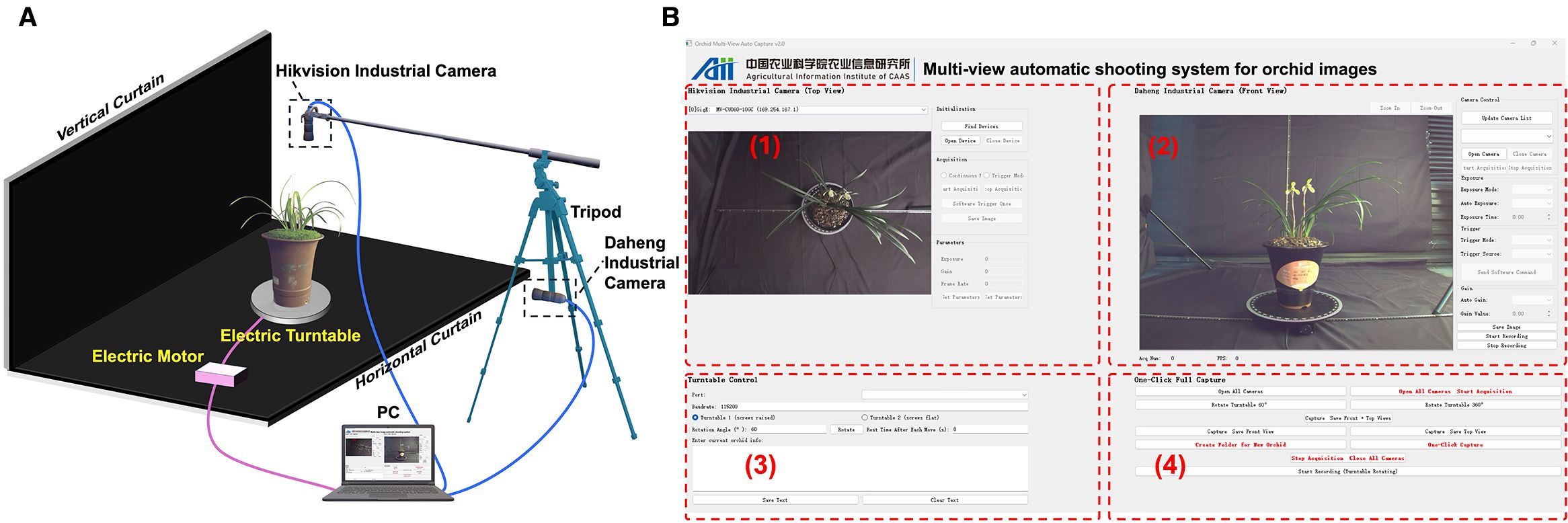
Figure 1. (A) Orchid image acquisition device. (B) Multi-view image automatic acquisition system interface with vertical view capture, front view capture, turntable control and auto-mated image acquisition.
Two industrial cameras were employed: a Daheng industrial camera (MER2-1220-32U3C, resolution: 4024×3036) for capturing front view images, and a Hikvision industrial camera (MV-CU060-10GC, resolution: 3072×2048) for capturing top view images. To verify the generalization ability of the proposed algorithm, a publicly available dataset of individual maize plants was used, which was captured using a Grasshopper 3 camera. The parameters of the three types of cameras are shown in Table 1. Notably, the distances between the cameras and the orchids were not fixed during data collection. Instead, these distances were dynamically adjusted based on the height and crown width of each orchid, ensuring that the entire plant was fully captured in both the top-view and front-view images.

Table 1. Key optical and sensor specifications of the imaging systems used for the orchid and maize datasets.
The potted orchids were positioned at the center of a motorized turntable, which was controlled via serial communication with a multi-view image acquisition software (Figure 1B). The motorized turntable is controlled via RS-485 using the Modbus-RTU protocol through a USB-to-RS485 converter. Commands for absolute angle setting, step execution, and start–stop were issued from a Python 3.10 client using the pySerial library, with standard Modbus frames and a 9,600-baud 8-N-1 configuration. Module 1 captures the top view, Module 2 captures the front view, Module 3 controls the rotation angle of the motorized turntable for view selection, and Module 4 performs automated batch acquisition. This automated system enabled the turntable to adjust the viewing angle, capture images, and store data without manual intervention, thereby ensuring consistency and standardization throughout the data collection process. In total, 367 orchids with both vertical and front view images were collected during the Third China Spring Orchid Festival (Shaoxing, Zhejiang, February 22–25, 2024).
2.2 Image binarization and random point generation
The hue channel in HSV (Hue, Saturation and Lightness) color space directly determines the color type (Hu et al., 2023; Shi et al., 2020), which facilitates accurate identification of regions of orchid leaves. The lower and upper thresholds for the green hues were established as the initial mask (), where the leaf regions were highlighted in white while the rest of the background was set to black (Figure 2A). However, due to the presence of background elements with colors similar to the leaves and the impact of lighting variation on leaves, the binarized image displayed noticeable gaps within the leaf regions and speckled noise in the background.
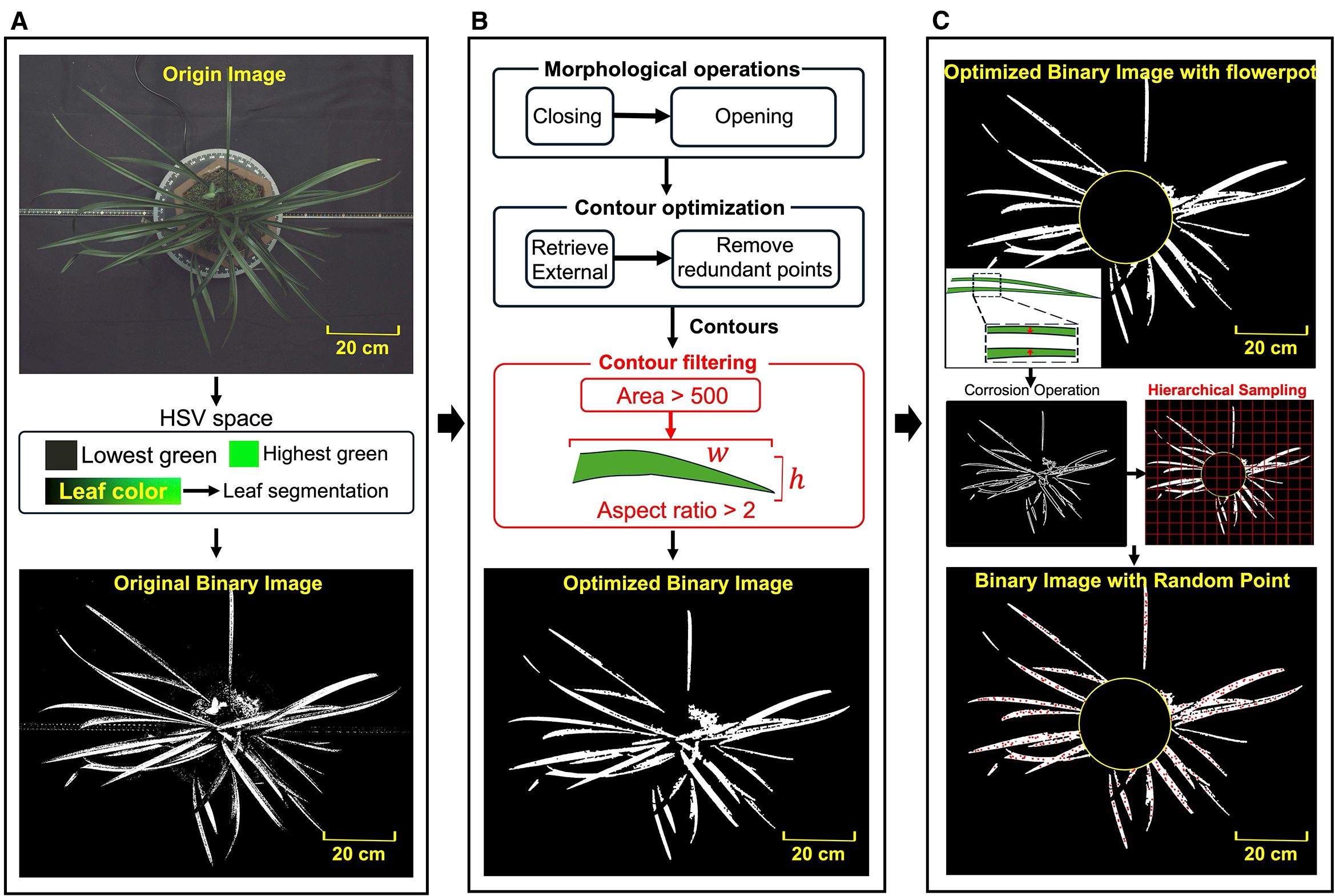
Figure 2. (A) Image binarization based on color threshold. (B) Binary images optimization based on morphological operations and contour features. (C) Random point generation based on corrosion operation and hierarchical sampling.
To eliminate the noise and accurately extract the contours of the leaves, a series of morphological operations were applied to the . Firstly, a morphological closing operation was used, followed by an opening operation, resulting in an improved mask . The opening and closing operation were expressed as
where and represents erosion and dilation operation respectively. is the binary image, is a 5×5 ones matrix kernel that is used to probe and interact with . The closing operation helped bridge small gaps and holes within the leaves (Le et al., 2020), while the opening operation effectively removed speckled noice within the background (Lei et al., 2019). Next, the binarized image is further refined based on the area and shape of the leaf contours. The contours of all connected regions within the white mask were traced pixel by pixel. Due to the presence of nested contours caused by noise, only the external contours were retained. To eliminate small contours unlikely to represent leaves, contours with an area smaller than 500 pixels were filtered out. The minimum bounding rectangle was then extracted for each contour, with its aspect ratio (the length ratio of longer side to shorter side) effectively distinguishing the elongated leaves from other objects. As the length of leaves are significantly longer than the width, contours with an aspect ratio greater than 2 were preserved. These contours, forming the set , formulating a separate mask . The intersection of and produced the final leaf mask , which highlighted the leaves in white against a black background, as shown in Figure 2B.
The keypoints on the orchid leaves were derived from randomly sampled points, with even distribution across the extracted leaf areas. Taking the vertical view image as an example, to simplify the computation, a circle was drawn with the centroid of as the center and half the length of the shortest contour in the set as the radius. This circle, , generally covered the central part of the flowerpot in vertical view and served as a white mask representing the pot. As illustrated in Figure 2C, to ensure an even distribution of random points across the white regions of the leaf image, hierarchical sampling was employed to divide the segmented leaf area into 40×40 patches. A random point is sampled from each subregion, excluding those within . Subsequently, morphological erosion algorithm is applied to reduce the boundary regions of the leaves (Yin et al., 2023), preventing points near the edges of the white areas from being selected as keypoints and ensuring that the generated random points were located close to the central skeleton of the leaves.
2.3 Initial keypoints recognition and search direction determination
For both random and regular morphological leaves, the outermost keypoints were firstly identified, then the search direction for subsequent keypoints was determined to reduce spatial complexity. The traversal of keypoints for the next leaf begins only after all keypoints of the current leaf have been identified. For each leaf, represents the -th keypoints of the -th leaf. was designated as the first keypoints of the first leaf (marked as visited), which has the maximum Euclidean distance from point (closest to leaf tip), as illustrated in Figure 3A. was identified as the closest unvisited point to . To locate , a circular search area is iteratively expanded around until one or more unvisited points were found. If a single unvisited point is identified within the search area, it is designated as . If multiple unvisited points were found, the point closest to is selected as , which is then marked as visited, forming the vector .
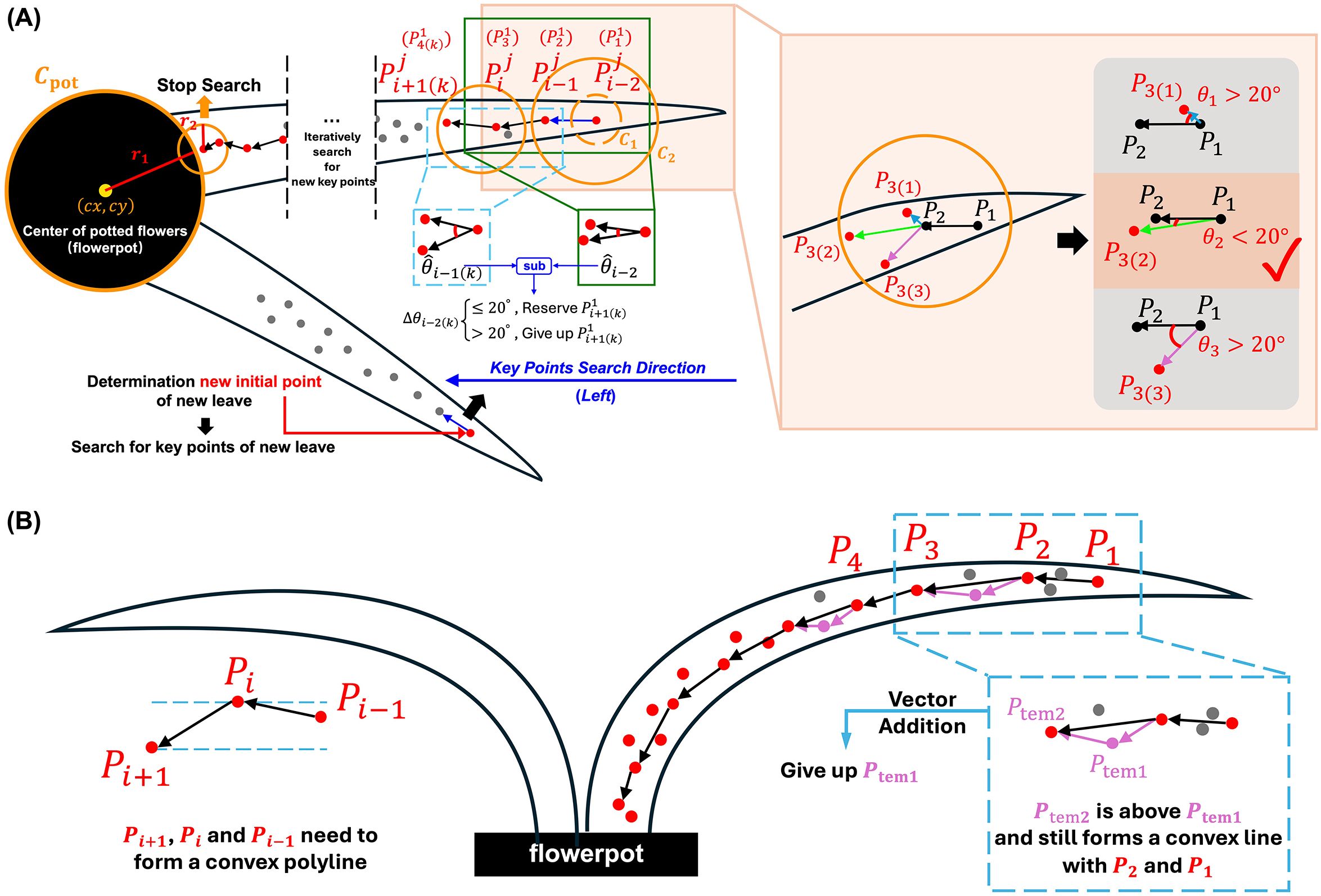
Figure 3. Keypoints determination method for vertical (A) vertical view and (B) front view.
The search for is also based on extending the circular search area centered on . However, given that the orientation of the leaf skeleton is determined, half of the random points within the circular search area are not candidate points for . The direction of the skeleton informs the search direction for subsequent keypoints, thereby reducing the search space for the next keypoint. The skeletal direction is determined by the relative positions of points and , specifically by comparing the absolute differences between the horizontal coordinates ( and ) and the vertical coordinates ( and ). This will result in more efficient search. The rules for determining the search direction for keypoints were shown in Table 2.
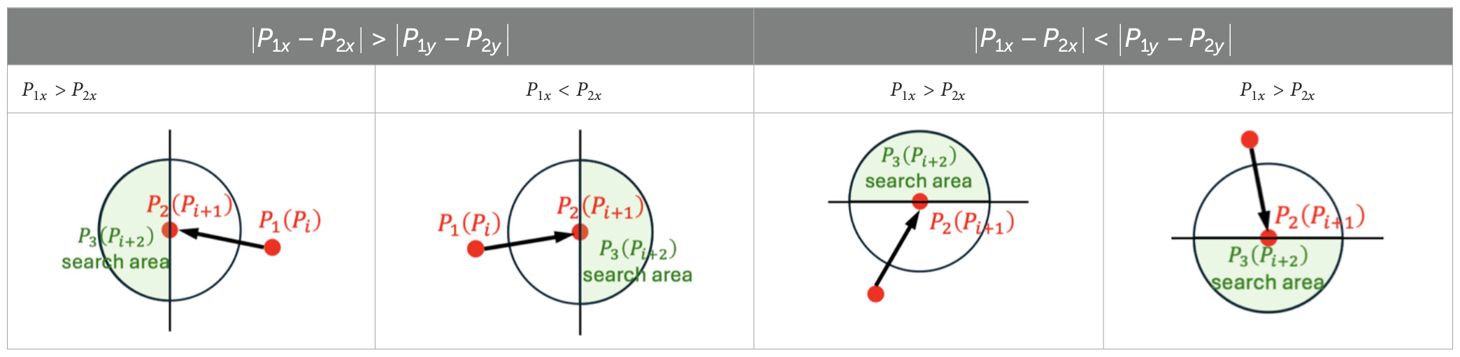
Table 2. The positional relationship between and determined the search direction for subsequent keypoints.
2.4 Remaining keypoints recognition for leaves with random and regular morphology
In vertical view of orchids, the uncertain growth trajectory of each leaf results in a random morphology. Therefore, based on the predetermined keypoint search direction, the optimal keypoints closest to the central skeleton must be adaptively identified. The determination of is based on the angle formed between vectors and , formulated as
where is the -th candidate point of in circular search area. is the angle between and . Within the left semicircle of the circular search area, there are three candidate keypoints, resulting in three angles. In order to effectively capture the natural curvature characteristics of orchid leaves along their main skeleton, we set a fixed threshold for the angular difference of candidate keypoints in our algorithm. Through statistical analysis and experimental validation on multiple orchid samples, we found that the local curvature variations of most leaves are confined within a narrow range. When the angular difference between a candidate keypoint and the current skeleton direction is less than 20°, the true turning points can be effectively identified while avoiding interference from noise and local anomalies. If the minimum angle in is less than 20°, the corresponding candidate point is selected as . Otherwise, the circular search area is further expanded. This 20° threshold was chosen based on the observed morphological properties of orchid leaves and extensive empirical testing, which demonstrated that it provides a robust balance between sensitivity (capturing genuine turning points) and specificity (avoiding spurious points due to noise). Fixing this threshold not only reflects the inherent geometric properties of orchid leaves but also simplifies the algorithm structure, thereby enhancing computational efficiency and consistency.
Once the first three keypoints have been identified, the subsequent keypoints were determined by iteratively running the same search algorithm. For example, to determine , the circular search area is iteratively expanded with as the center. The unvisited points within the left semicircle of this area form a set . The algorithm then calculates the angle set and . It compares the differences between and each . Similar to the selection of , if the smallest angle difference exceeds the threshold of 20°, the circular search area is further expanded. Otherwise, the point with the smallest angle difference was selected as , as follows
Then, the same method was iteratively applied to locate subsequent keypoints . The loop terminates under the following condition
where represents the last identified keypoints of the leaf, is the radius of , is the radius of the circular search area corresponding to , and is the Euclidean distance between the centers of and . When the circular search area of contains no unvisited points and intersects with , is designated as , and the iteration stops. At this time, all keypoints for the single leaf have been determined.
The algorithm is then repeated on other leaves. The point , which has the greatest Euclidean distance from , is identified as the first keypoints of the second leaf. The same algorithm was then applied to determine all keypoints of this leaf, continuing until the keypoints for all leaves were found.
In front view of orchids, due to the influence of gravity, all orchid leaves form a completely regular convex polyline (Figure 3B). Therefore, the trajectory pattern was fitted by minimizing curvature based on the consistent leaves trend. Let any three continuous keypoints along the leaf (from the root to the tip) be denoted as , , and . These points must satisfy the following condition
where represents the number of keypoints on the -th leaf. This ensures that any adjacent three keypoints form a convex sub-polyline, and the collection of these sub-polylines constitutes the fully convex skeleton of the leaf.
The keypoints identification process for the front view image of the orchid leaf begins by selecting the initial point as the farthest point from the leaf base. To determine the subsequent point , a circular search area centered on is iteratively expanded until more than two unvisited points were found. The point with the closest -coordinate to is then selected as . The next keypoint, , is identified by expanding the search area centered on . If more than 2 unvisited points were found within this area, the point that forms a convex curve with and and results in minimal curvature is chosen as .
The search then continues by expanding the area around . If there were at least two points in this area, they were evaluated. If a point forms a convex polyline with and and lies above , this indicates that the polyline has a lower curvature than . In this case, the following vector addition is performed as
Thus, is set as the final , and is discarded. Conversely, if is located below , then is confirmed as , and becomes . This iterative traversal, combined with vector addition, allows for a more precise fitting of the leaf structure in front view.
All experiments—orchid (two industrial cameras) and maize (PHENOARCH platform)—were run with a single, immutable parameter set. Values were selected once on an orchid batch and were not tuned thereafter, thereby demonstrating cross-species generalizability. Table 3 lists the constants, and no entry changes across datasets, resolutions or cameras.
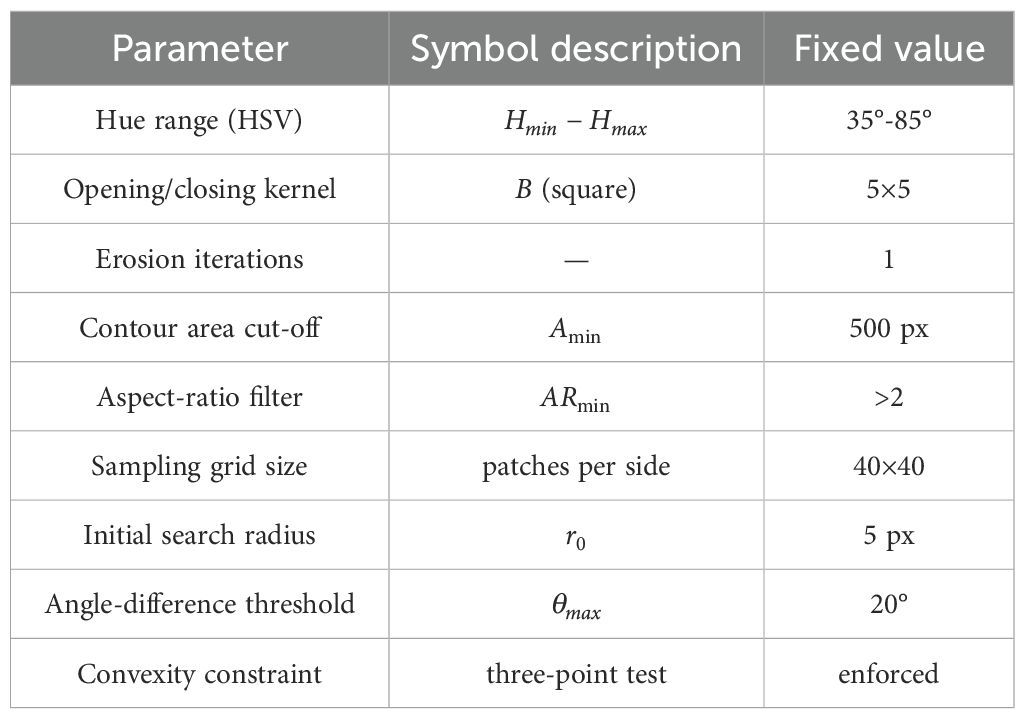
Table 3. Global implementation parameters used for all images.
2.5 Evaluated indicators for skeletonization algorithms
The accuracy of the predicted skeletons was evaluated using curvature error (Figure 4). Let represent the true skeleton curve of the leaf, with curvature at point given by (Schamberger et al., 2023)
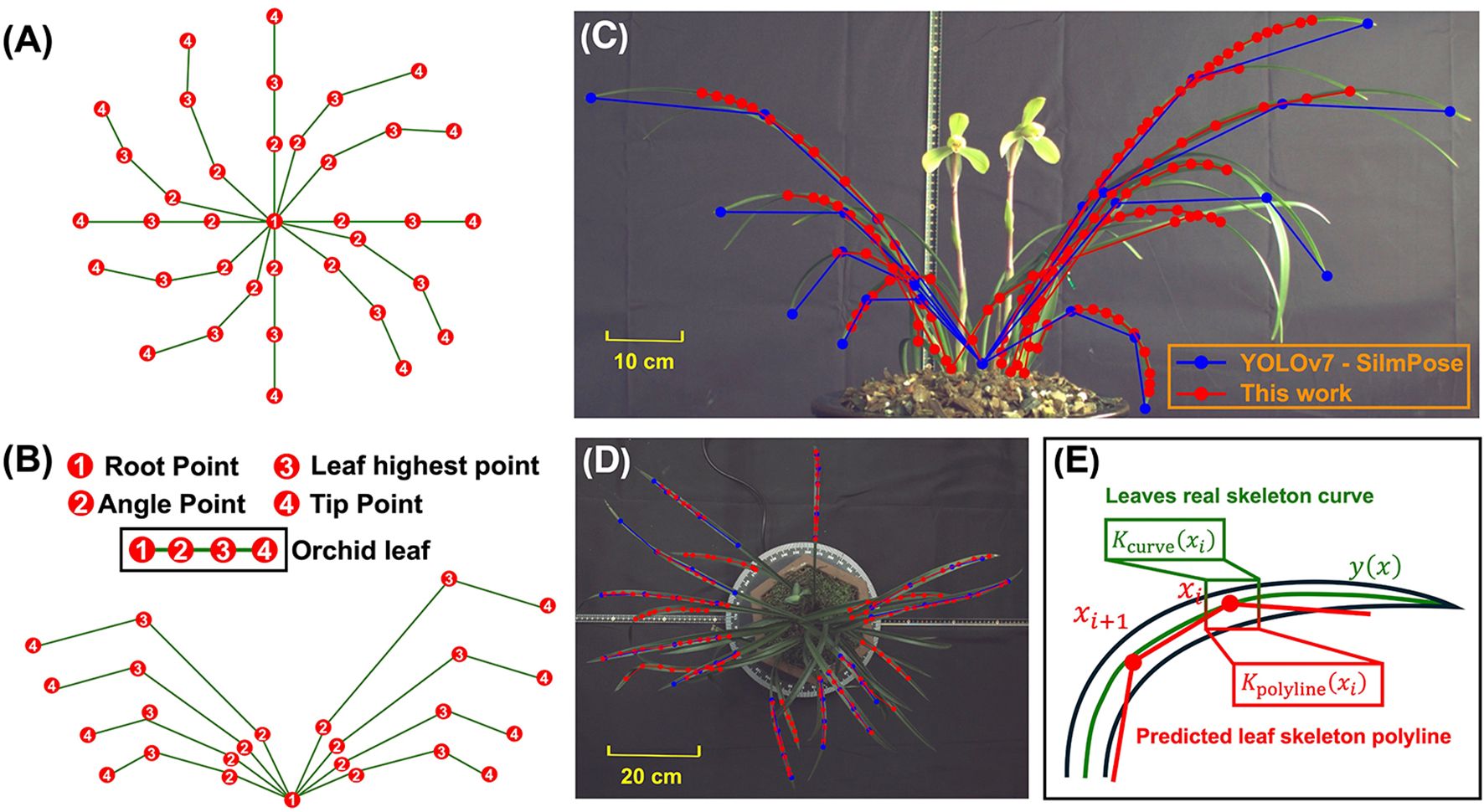
Figure 4. Predefined keypoints for YOLOv7-SlimPose in (A) vertical view and (B) front view. Identified keypoints and skeletons in (C) front view and (D) vertical view. (E) Curvature of real leaf skeleton curve and predicted leaf skeleton polyline at point xi.
and the curvature at point of the predicted leaf skeleton polyline is given by (Chuon et al., 2011)
where represents the angle at the -th vertex of the polyline, and is the Euclidean distance between the -th and -th points on the polyline. The curvature error between the predicted and true skeletons is defined as
A smaller curvature error indicates a higher shape conformity between predicted polyline skeleton and the true curve skeleton. The leaf recall rate was used to measure the proportion of leaves correctly identified and successfully skeletonized out of the total number of leaves, defined as
2.6 Leaves phenotypes
For vertical view, the number of algorithm’s outermost loop (which traverses each leaf) corresponds to the leaves’ number. As shown in Figure 5A, since the initial point for each leaf is closest to the leaf tip, the total number of represents the leaf count. The maximum distance between any two represents the crown width of the orchid (Ebrahimi et al., 2020), measured in pixels. Because pixel measurements cannot accurately reflect the true crown width, the relative crown width was used as a key feature for evaluating the orchid, formulated as
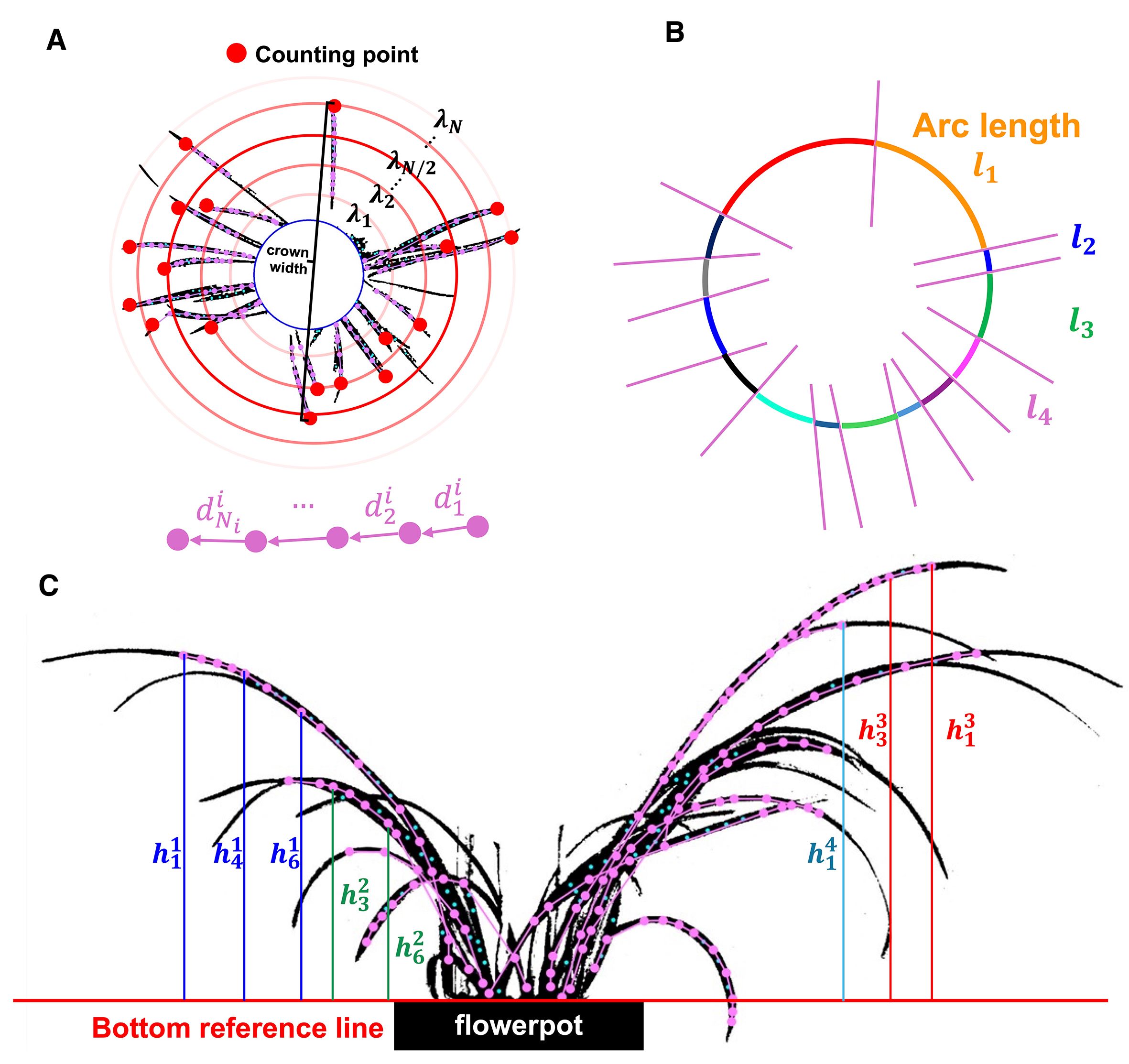
Figure 5. (A) The initial point located at the leave tip, and the crown width obtained from the two farthest initial points. (B) Arcs obtained by intersecting concentric circles with leaf skeleton. (C) The height of each keypoints relative to the bottom reference line in front view.
Let represent the number of keypoints in the leaf. Since the skeleton formed by connecting these keypoints accurately represents the shape of the leaf, the total length of the skeleton corresponds to the length of the leaf. Leaf height consistency is the variance of each leaf’s mean vertical distance from keypoints to the pot’s top reference line in the front view, reflecting canopy regularity that growers use to judge form. Relative crown width is scale robust by construction. Leaf height consistency is expressed as
A concentric circle is drawn with the crown width as its diameter, centered on the flowerpot (Figures 5A, B). Between and , additional concentric circles were generated with equal radial increments, where the radius of each is denoted as . The boundaries of each concentric circle may intersect the skeleton of the leaves at different points. Each intersection divides into several arcs, with representing the arc length of the -th segment of the -th concentric circle, corresponding to the distance between adjacent leaves under the condition of . Thus, represents the leaf distribution consistency at .
However, in vertical view, the leaves radiate outward from the center, causing the distance between adjacent leaves to vary under different conditions. Generally, is positively correlated with , and leaf distribution consistency at an intermediate better reflects the overall leaf uniformity of the orchid. Therefore, leaf distribution consistency for the orchid (the weighted average of ) quantified how uniformly leaves occupy space around the pot by partitioning the annulus between the pot circle and the crown circle into concentric rings. Leaf distribution consistency is defined as
where is a Gaussian function satisfying and , expressed as
For front view, the top edge of the flowerpot’s rectangular boundary serves as the bottom reference line of leaves (). The distance from the -th key point of leaf to is denoted as , and the average distance of all keypoints in leaf to is represented by . The variance of across all leaves reflects the variation in the average height of each leaf within the orchid, which is defined as leaf height consistency (Figure 5C), indicating whether the architecture is harmonized rather than a mix of very long and very short leaves. Leaf height consistency is formulated as
where represents the number of keypoints on leaf in front view.
3 Results and discussion
3.1 Keypoints connection results and phenotypic extraction
The keypoints connection method was applied to both front view and vertical view images of the orchid. The keypoints connection result was shown in Figures 6A, B, respectively It can be seen that the leaves were accurately extracted without any background noise. Due to the application of morphological erosion to reduce the leaf boundary regions, random points were uniformly generated in areas close to the central skeleton. Since the leaf tip width is narrow, the diameter of the random points exceeded the eroded width of leaf tip, resulting in incomplete point generation at the outermost tip. After executing the keypoints algorithm, nearly all leaf skeletons were accurately extracted under complex conditions involving dense leaves, leaf intersection and leaf occlusion. Motivated by this observation, a quantitative analysis was conducted to explicitly characterize when tip detection fails and how this affects downstream phenotypes.
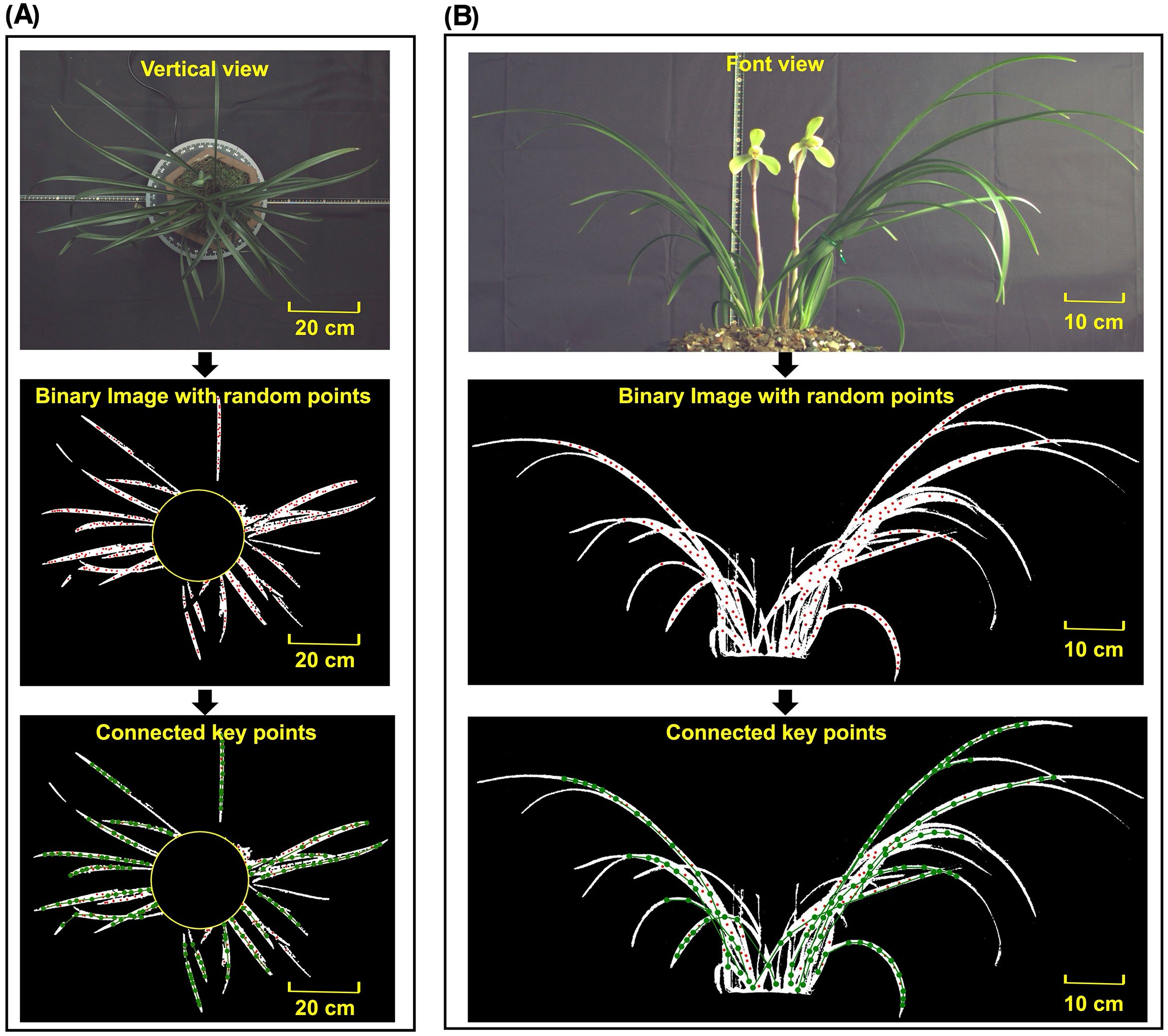
Figure 6. Original image, binary image with random points and binary image with connected keypoints in (A) vertical view and (B) front view.
To make failure modes explicit, a leaf-level criterion was adopted whereby a tip is counted as missed if the outermost 20% sector of that leaf contains no sampled points. Using this definition and expressing the random-point marker diameter as a percentage of the shortest contour length in , the tip-miss frequency over the entire orchid dataset (front and top views combined) was 19.24% at the default setting of 1.5%. An ablation varying the marker diameter showed a monotonic decrease in misses—from 32.34% (6%) to 0% (0.1%)—indicating that erosion-induced narrowing at very thin tips is the primary cause and can be mitigated by smaller markers. Phenotype level effects were limited at the default: leaf count was essentially unchanged. Relative crown width exhibited a mild negative bias (−2.4%). Leaf-length consistency showed a small positive bias (+2.6%). Leaf distribution consistency changed negligibly due to Gaussian mid-radius weighting. And in front views, leaf-height consistency showed a minor negative bias (−1.1%). These results indicate that, under default settings, tip misses occur in a fraction of leaves but have minor impact on the five target phenotypes. If complete tip recovery is required, reducing the marker diameter (≤0.3%) eliminates the effect without altering the rest of the pipeline.
YOLOv7-SlimPose (Gao et al., 2024) was utilized based on the same dataset. For each leaf, four keypoints were predefined and annotated (Figures 4A, B): (1) Root point, which is the point where the base of the plant connects to the pot; (2) Angle point, located at the midpoint between the Root point and the Tip point; (3) Angle point 2, positioned at three-quarters of the distance from the Root point to the Tip point; and (4) Tip point, representing the apex of the leaf. Keypoints point (1) through (4) were sequentially connected to form the leaf skeleton. 10 leaves and 8 leaves were annotated in vertical view images and font view images respectively. The annotated leaf skeletons in each image were evenly distributed. A total of 561 images were selected for the training set, 126 images for the validation set, and the remaining 15 images were used as the test set. The ratio of vertical view to front view images was maintained at 1:1 across the training, validation, and test sets. Due to the distinct distribution of leaves in the vertical and front view, the images from these two perspectives were separated and used to train two models: one for vertical view and another for front view (Total training time is 7.3 hours). After training, the test set images were input into YOLOv7-SlimPose, which output the leaf keypoints and skeletons for front view (blue output in Figure 4C) and vertical view (blue output in Figure 4D).
The test set images (Figure 7A) were processed by both algorithms. Based on the identified keypoints and the leaf skeleton, 5 key features were further extracted, and the curvature error and leaf recall rate were calculated for each, as shown in (Figure 7B).
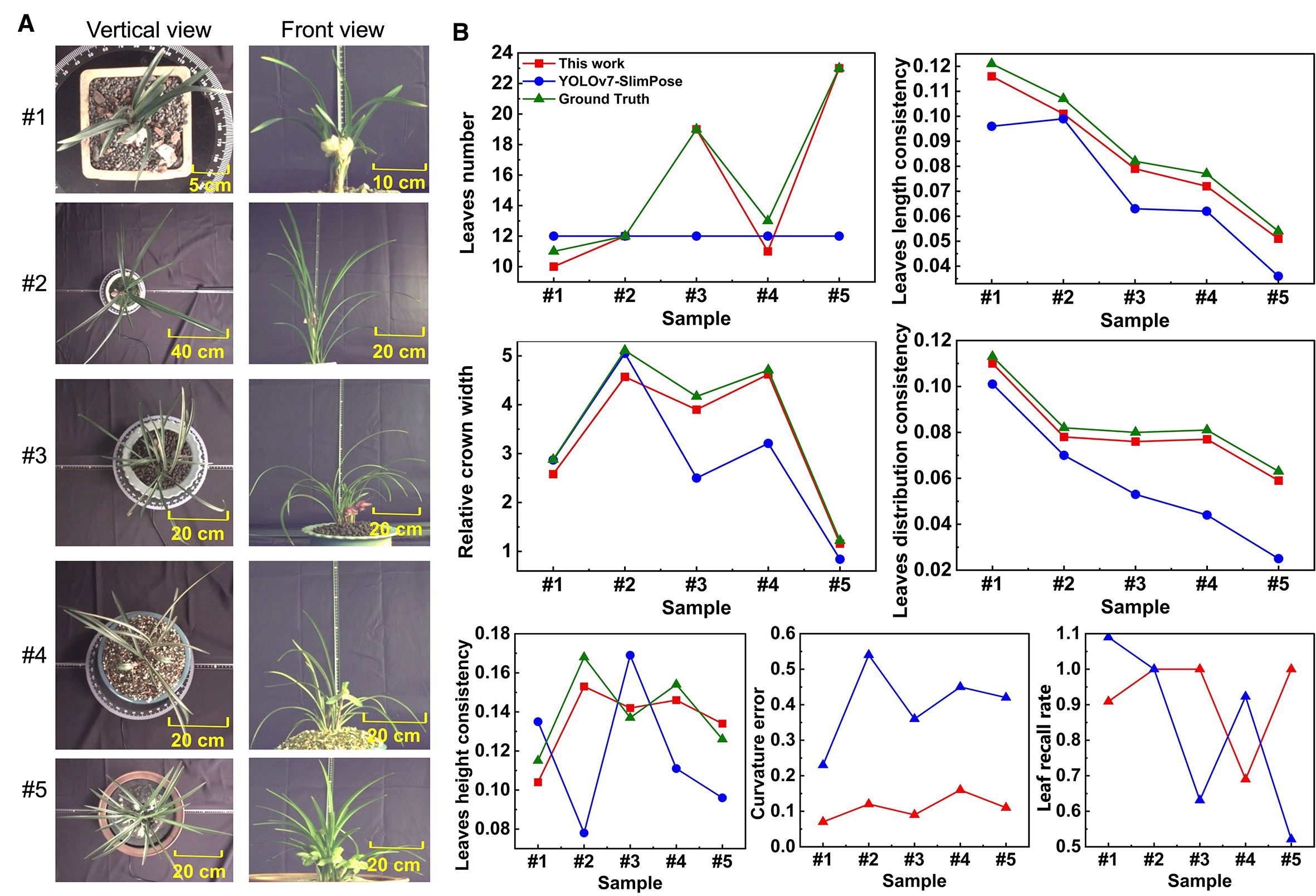
Figure 7. (A) Vertical view and front view in test set (5 samples as example). (B) 5 phenotypes, curvature error and leaf recall rate obtained by YOLOv7-SlimPose and this work.
YOLOv7-SlimPose has a fixed output layer structure and relies on an anchor-based object detection mechanism, which restricts the size and position of the output targets within a predefined range (Liu et al., 2022). The model generates a fixed number of keypoints for each anchor position during forward propagation. This design limits the model to outputting only a predetermined number of keypoints and predefined skeleton connections (He et al., 2022; Tan et al., 2024). Consequently, skeletons’ number and keypoints detected by YOLOv7-SlimPose model are entirely dependent on the annotations in the training data, which often require expert knowledge in botany, especially when dealing with complex plant structures.
For front view, orchid leaf root points were distributed across various positions within the pot. However, due to annotation constraints, YOLOv7-SlimPose identifies all root points as being concentrated in a single location, failing to represent the true morphology of leaves. Orchids exhibit varying numbers of leaves, leaf lengths, and leaf distributions, but YOLOv7-SlimPose lacks the flexibility to dynamically adjust the output structure based on the input, making it inadequate for handling uncertain keypoints numbers and connection patterns. Therefore, deep learning models like YOLOv7-SlimPose are more suitable for applications involving fixed keypoints numbers and skeleton structures, such as human or animal pose estimation, rather than for complex plants like orchids, which have dense and variable leaf pattern.
Based on the skeletons generated by YOLOv7-SlimPose, five orchid phenotypes were extracted from the test set, with the results shown in Figure 7. For the vertical view, as the annotated number of leaves was fixed at 12, the model consistently detected 12 leaf skeletons (with the leaf count remaining constant at 12) and 37 keypoints across all images. In contrast, the method proposed in this work accurately detected varying numbers of leaves, achieving a leaf recall rate of 1 in three out of five samples. In the first two samples, where the leaves were relatively sparse, YOLOv7-SlimPose was able to detect most of the leaf tips, resulting in a relative crown width close to the ground truth. However, as the number of leaves increased in the remaining samples, the accuracy of the crown width predictions by YOLOv7-SlimPose dropped significantly compared to this work. The fixed number of keypoints output by YOLOv7-SlimPose resulted in poor fitting of the true leaf skeleton curve, limiting the model’s ability to accurately reflect leaf consistency. The average curvature error and leaf recall on test set were only 59% and 63%, respectively. In contrast, this work successfully detected enough leaves and keypoints, and accurately fitted the real leaf skeleton, resulting in more precise extraction of leaf length consistency, distribution consistency, and height consistency. Without manual labeling and long-term training, the average curvature error and blade recall of the test set reached 0.12 and 92%, respectively.
To demonstrate how the proposed spontaneous key-points connection differs from traditional non-learning approaches, the same binary masks were processed with the medial-axis transform (MAT) and with Zhang–Suen thinning (Figure 8). Both classical algorithms inherit every imperfection present in the thresholded image: darker leaf segments translate into complete breaks, while small contour irregularities give rise to dense clusters of spurs and lateral branches. The resulting skeletons are fragmented and highly branched, preventing the continuous center-line that downstream phenotype measurements require. By contrast, the proposed strategy links interior sample points under geometric constraints that actively suppress burr formation and bridge minor gaps, yielding a single, smooth curve for each leaf and enabling reliable extraction of length, curvature and spatial-distribution traits. The qualitative comparison therefore reinforces the practical advantage and uniqueness of the present method for complex leafy plants.
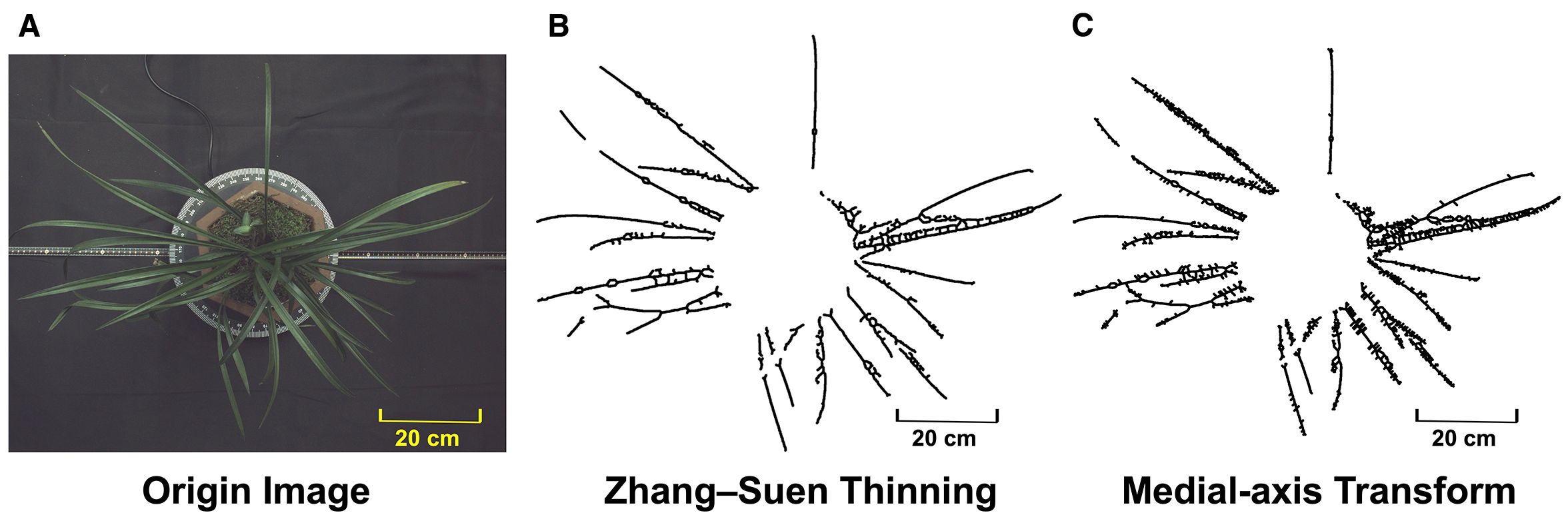
Figure 8. (A) Original image; (B) skeletonization result of Zhang–Suen thinning; (C) skeletonization result of MAT.
3.2 Computational efficiency or practicality
Experiments were conducted on a CPU-only workstation equipped with 32 GB DDR4–2666 system memory. For images of 4024 × 3036 and 3072 × 2048 pixels, the algorithm required on average 3.556 s and 2.247 s per image, respectively, with peak resident memory of approximately 190.50 MB and 150.37 MB. No GPU acceleration was used.
Compared with the classical methods that have been publicly disclosed, iterative refinement in the i5-4670K and 4 GB memory virtual machine environment, most algorithms are completed within the range of 0.58-0.96 s for a single image, while Stentiford and an improved method take about 1.21-1.43 s (Gramblicka and Vasky, 2016). The total runtime given in the example script, represented by the central axis transformation, is about 1.34 s/image. The total runtime of the activity outline in similar official examples is about 2.03 seconds per image. The Hessian Frangi ridge filter shows an average of 1.187 s/graph in the i7 3.0 GHz, 64 GB, RTX 2060 environment, and hardware configuration is provided to ensure comparability (Hachaj and Piekarczyk, 2023).
Although the single frame time is slightly higher than several classic skeleton pipelines, this method does not require labeling and training, and can adaptively generate a variable number of keypoints and skeletons after one preprocessing. It directly supports phenotype calculations such as leaf number, crown width, length consistency, distribution consistency, and height consistency, and has been validated for stable leaf recall rate and cross species generalization in orchid and maize morphologies. The practicality of this type of “training species independent” is supported by the cost of running a CPU in seconds and a hundred megabits of memory, avoiding the time and economic expenses of retraining and manual annotation. Regarding scalability, when the number of pixels increases from 6.29 million to 12.22 million (1.94 ×), the average time takes from 2.247 s to 3.556 s (1.58 ×), showing a nearly linear or even better scaling. The algorithm mainly relies on local search and angle/convexity constraints on the mask, and the computational complexity mainly increases linearly with the number of pixels and candidate points, so it will only be faster at lower resolutions. 4024 × 3036 has significantly exceeded the imaging requirements of most production processes, and high-resolution is chosen to cover the most demanding resolution scenes. In terms of density, the high leaf density, occlusion, and overlap of orchids have constituted strict stress tests, while the full growth period samples of corn gradually increase leaf density, all of which can maintain stable skeleton extraction and high leaf recall rate, indicating that the scalability in leaf quantity and density has practical significance.
3.3 Generalization ability verification
To verify the generalization ability of the proposed algorithm, it was applied to maize. Similar to orchid leaves, maize leaves are soft, numerous, densely packed, and exhibit significant overlap. Using the publicly available single-plant maize dataset (Dataset URL: https://datasetninja.com/maize-whole-plant-image-dataset), which captured images of a single maize plant over 113 days—with 1 vertical view and 12 front view images taken each day—the spontaneous keypoints connection algorithm was applied to both a front view (Figure 9) and a vertical view image (Figure 9) from 10 different days, spanning pre-, mid-, and post-growth stages (Figure 10). Due to the relatively wide leaves of maize, random points could still be generated at the eroded leaf tips, and in some cases, a single maize leaf may be mistakenly identified as two separate leaves in the vertical view.
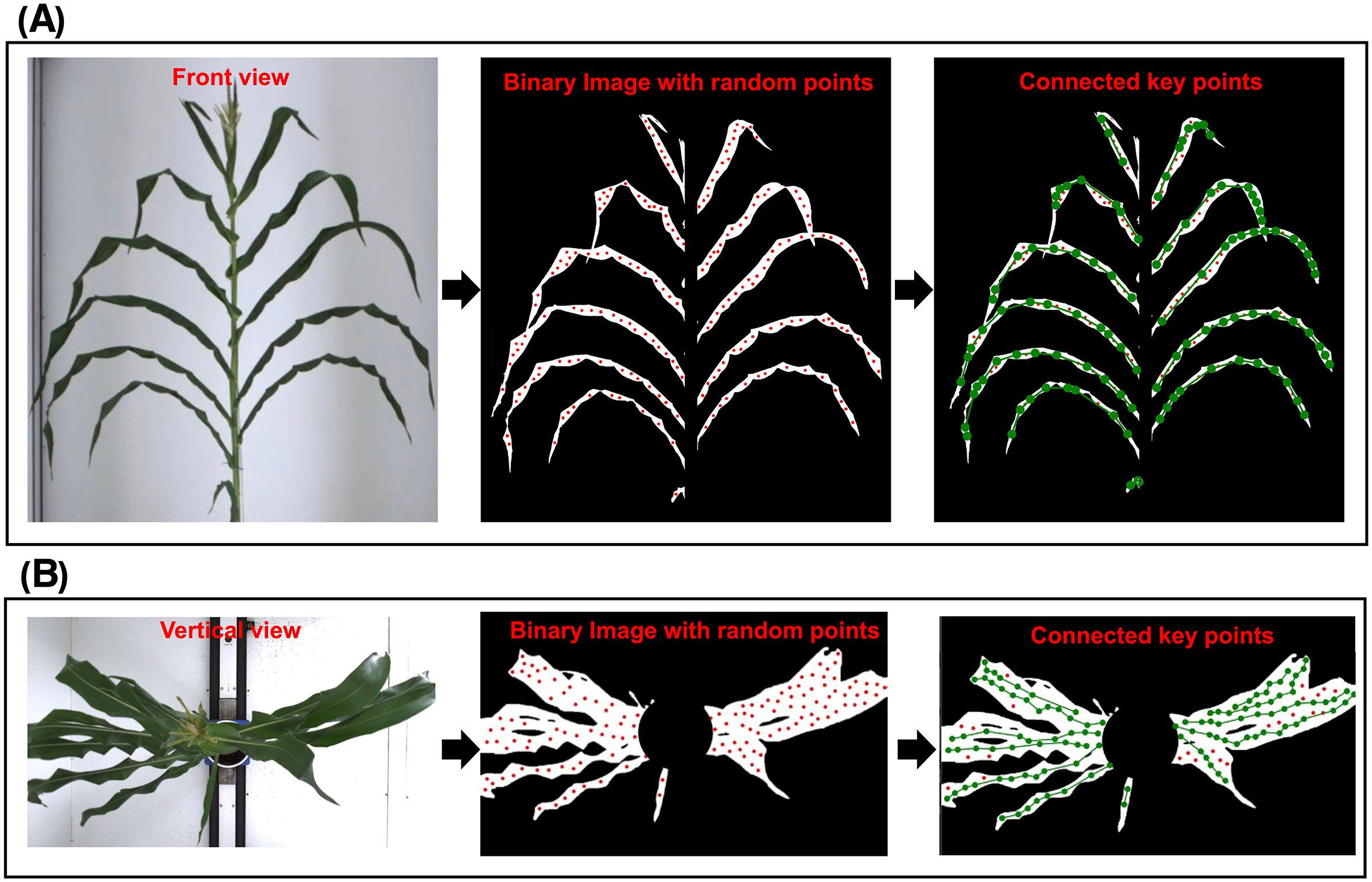
Figure 9. Original image, binary image with random points and binary image with connected keypoints of a single maize in (A) vertical view and (B) front view.
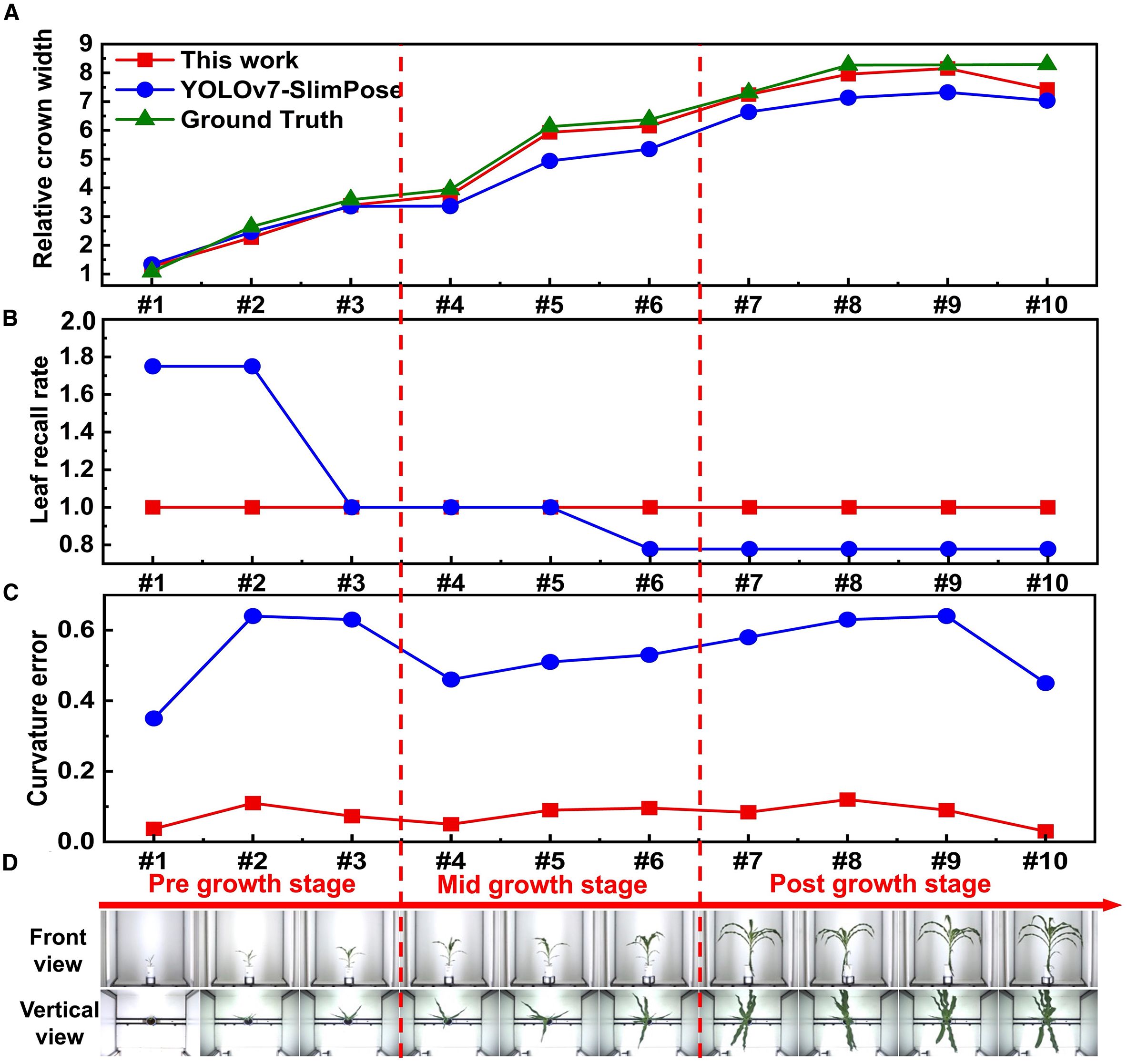
Figure 10. (A) Relative crown width, (B) curvature error and (C) leaf recall rate of a single maize plant throughout entire growth stage obtained by YOLOv7-SlimPose and this work. (D) Vertical view and front view images of a single maize plant throughout entire growth stage.
It is important to note that the extraction of maize leaf count is based on the front view images, while the vertical view is primarily used to extract features such as crown width, leaf distribution consistency, and overall plant structure. Therefore, any misidentification of leaf number in the vertical view does not affect the final feature extraction or the evaluation of the algorithm’s generalization ability on maize leaves.
Samples #4 and #5 were annotated for YOLOv7-SlimPose training, with 6 skeletons annotated per front view image and 4 skeletons per vertical view image. The relative crown width was extracted from 10 samples (Figure 10). During the early growth stage, when maize leaves are smaller and fewer in number, YOLOv7-SlimPose predicted more skeletons than the actual leaf count, allowing it to accurately estimate the crown width in this stage. However, as the plant continued to grow, both the size and number of leaves increased. The number of leaves exceeded the prediction range of YOLOv7-SlimPose in mid-to-late growth stages, resulting in greater prediction error for the relative crown width.
In contrast, the proposed method accurately predicted the relative crown width across all growth stages (Figure 10) and consistently detected all leaves from the front view, maintaining a leaf recall rate of 100% throughout (Figure 10). Additionally, compared to YOLOv7-SlimPose, the proposed method maintained a lower curvature error (Figure 10) for front view images across all growth stages. These results confirm that the proposed method accurately extracts all keypoints and skeletons of maize leaves, demonstrating its effectiveness in keypoint detection, skeleton recognition, and feature extraction in crops with complex morphologies.
In summary, this work identifies keypoints and skeletons based solely on the connection of randomly generated points in the leaf region. This approach eliminates the need for predefined keypoints and training based on plant structure, making it adaptable for a broader range of plant phenotypic extraction tasks.
4 Conclusion
A spontaneous keypoints connection skeletonization algorithm based on random points was firstly developed for leafy plants phenotypic extraction. HSV color thresholding separated orchid leaves into binarized images. Morphological opening and closing operations, along with area and leaf shape filters, effectively removed noise. After leaf boundary erosion, random points were sampled near the central skeleton within each generated patch. The skeletonization approach was applied to plants with random leaf morphology and regular leaf morphology. For random leaf morphology, the point furthest from the center was identified as the first keypoint. A circular search was then iteratively expanded from this keypoint to find the next point. The subsequent keypoints search direction was determined based on the relative position of these two keypoints, thereby reducing the spatial complexity by half. Remaining keypoints were identified using angle difference thresholds. For regular leaf morphology, the algorithm ensured the accuracy of leaf skeleton fitting by enforcing that any three consecutive points formed a convex polyline while minimizing curvature. By iteratively applying this approach, nearly all leaves’ skeletons were detected, achieving an average curvature error of 0.12 and a leaf recall rate of 92%. In addition, a qualitative comparison with classical non-learning baselines showed that both inherit binarization discontinuities and produce fragmented, highly branched center-lines, whereas the proposed strategy yields smooth and continuous skeletons that enable downstream phenotypic measurements. Finally, five phenotypes of orchids were accurately extracted based on the identified skeletons. Moreover, this algorithm effectively predicted maize’s relative crown width throughout all growth stages and consistently detected 100% of the leaves, highlighting its generalization capability on wide leaf plants. Compared to existing literature reports, this approach accurately skeletonized leafy plants with random and regular morphological leaves, eliminating manual keypoints design and training based on plants’ structure. It can spontaneously detect keypoints and extract skeletons according to plant morphology, offering an effective solution for accurate phenotypic extraction of more plants with complex morphologies.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding author.
Author contributions
ZW: Conceptualization, Software, Writing – original draft, Methodology. XH: Data curation, Writing – review & editing, Software. YW: Writing – review & editing, Investigation. CY: Writing – review & editing. BF: Project administration, Funding acquisition, Writing – review & editing. QZ: Supervision, Project administration, Funding acquisition, Writing – review & editing. XL: Project administration, Writing – review & editing.
Funding
The author(s) declare financial support was received for the research and/or publication of this article. This work was supported by the Innovation Program of the Chinese Academy of Agricultural Sciences [CAAS-CAE-202302, CAAS-ASTIP-2024-AII] and the Central Public-interest Scientific Institution Basal Research Fund (No. JBYW-AII-2025-01).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Bucksch, A. (2014). A practical introduction to skeletons for the plant sciences. Appl. Plant Sci. 2, 1400005. doi: 10.3732/apps.1400005
Cembrowska-Lech, D., Krzemińska, A., Miller, T., Nowakowska, A., Adamski, C., Radaczyńska, M., et al. (2023). An integrated multi-omics and artificial intelligence framework for advance plant phenotyping in horticulture. Biology 12, 1298. doi: 10.3390/biology12101298
Chuon, C., Guha, S., Janecek, P., and Song, N. D. C. (2011). Simplipoly: Curvature-based polygonal curve simplification. Int. J. Comput. Geometry Appl. 21, 417–429. doi: 10.1142/S0218195911003743
De Vylder, J., Ochoa, D., Philips, W., Chaerle, L., and van der Straeten, D. (2011). “Leaf segmentation and tracking using probabilistic parametric active contours,” in International Conference on Computer Vision/Computer Graphics Collaboration Techniques and Applications (Berlin, Heidelberg: Springer). doi: 10.1007/978-3-642-24136-9_7
Ebrahimi, A., Asadi, A., Monfared, S. R., Sahebi, M., Rezaee, S., and Khaledian, Y. (2020). Evaluation of phenotypic diversity of the endangered orchid (orchis mascula): Emphasizing on breeding, conservation and development. South Afr. J. Bot. 132, 304–315. doi: 10.1016/j.sajb.2020.05.013
Gao, Y., Li, Z., Li, B., and Zhang, L. (2024). Extraction of corn plant phenotypic parameters with keypoint detection and stereo images. Agronomy 14, 1110. doi: 10.3390/agronomy14061110
Gramblicka, M. and Vasky, J. (2016). Comparison of thinning algorithms for vectorization of engineering drawings. J. Theor. Appl. Inf. Technol. 94, 265.
Guan, Z.-J., Zhang, S.-B., Guan, K.-Y., Li, S.-Y., and Hu, H. (2011). Leaf anatomical structures of paphiopedilum and cypripedium and their adaptive significance. J. Plant Res. 124, 289–298. doi: 10.1007/s10265-010-0372-z
Hachaj, T. and Piekarczyk, M. (2023). High-level hessian-based image processing with the frangi neuron. Electronics 12, 4159. doi: 10.3390/electronics12194159
He, J., Weng, L., Xu, X., Chen, R., Peng, B., Li, N., et al. (2024). Dekr-sprior: An efficient bottom-up keypoint detection model for accurate pod phenotyping in soybean. Plant Phenomics 6, 198. doi: 10.34133/plantphenomics.0198
He, X., Wandt, B., and Rhodin, H. (2022). Autolink: Self-supervised learning of human skeletons and object outlines by linking keypoints. Adv. Neural Inf. Process. Syst. 35, 36123–36141. doi: 10.48550/arXiv.2205.10636
Hu, T., Zhou, Q., Nan, X., and Lin, R. (2023). A color image decomposition model for image enhancement. Neurocomputing 558, 126772. doi: 10.1016/j.neucom.2023.126772
Jiang, Y. and Li, C. (2020). Convolutional neural networks for image-based high-throughput plant phenotyping: A review. Plant Phenomics. 2020, 4152816. doi: 10.34133/2020/4152816
Kolhar, S. and Jagtap, J. (2023). Plant trait estimation and classification studies in plant phenotyping using machine vision–a review. Inf. Process. Agric. 10, 114–135. doi: 10.1016/j.inpa.2021.02.006
Lac, L., Da Costa, J.-P., Donias, M., Keresztes, B., Louargant, M., and Prigonrieux, F. (2021). SDNet: Unconstrained object structure detector network for in-field real-time crop part location and phenotyping. BMVC. 35, 1–13. doi: 10.5244/C.35
Lagergren, J., Pavicic, M., Chhetri, H. B., York, L. M., Hyatt, D., Kainer, D., et al. (2023). Few-shot learning enables population-scale analysis of leaf traits in populus trichocarpa. Plant Phenomics 5, 72. doi: 10.34133/plantphenomics.0072
Le, V. N. T., Ahderom, S., Apopei, B., and Alameh, K. (2020). A novel method for detecting morphologically similar crops and weeds based on the combination of contour masks and filtered local binary pattern operators. GigaScience 9, giaa017. doi: 10.1093/gigascience/giaa017
Lei, W., Hou, F., Xi, J., Tan, Q., Xu, M., Jiang, X., et al. (2019). Automatic hyperbola detection and fitting in gpr b-scan image. Automation Construction 106, 102839. doi: 10.1016/j.autcon.2019.102839
Li, Y., Zhan, X., Liu, S., Lu, H., Jiang, R., Guo, W., et al. (2023). Self-supervised plant phenotyping by combining domain adaptation with 3d plant model simulations: Application to wheat leaf counting at seedling stage. Plant Phenomics 5, 41. doi: 10.34133/plantphenomics.0041
Li, Z., Guo, R., Li, M., Chen, Y., and Li, G. (2020). A review of computer vision technologies for plant phenotyping. Comput. Electron. Agric. 176, 105672. doi: 10.1016/j.compag.2020.105672
Liu, B., Chang, J., Hou, D., Pan, Y., Li, D., and Ruan, J. (2024). Recognition and localization of maize leaf and stalk trajectories in rgb images based on point-line net. Plant Phenomics 6, 199. doi: 10.34133/plantphenomics.0199
Liu, X., Chen, H.-X., and Liu, B.-Y. (2022). Dynamic anchor: A feature-guided anchor strategy for object detection. Appl. Sci. 12, 4897. doi: 10.3390/app12104897
Liu, Y., Liu, Y., He, Y., Yan, Y., Yu, X., Ali, M., et al. (2023). Cytokinin-inducible response regulator slrr6 controls plant height through gibberellin and auxin pathways in tomato. J. Exp. Bot. 74, 4471–4488. doi: 10.1093/jxb/erad159
Murata, H. and Noshita, K. (2024). Three-dimensional leaf edge reconstruction combining two-and three-dimensional approaches. Plant Phenomics 6, 181. doi: 10.34133/plantphenomics.0181
Nyonje, W. A., Schafleitner, R., Abukutsa-Onyango, M., Yang, R.-Y., Makokha, A., and Owino, W. (2021). Precision phenotyping and association between morphological traits and nutritional content in vegetable amaranth (amaranthus spp.). J. Agric. Food Res. 5, 100165. doi: 10.1016/j.jafr.2021.100165
Ogidi, F. C., Eramian, M. G., and Stavness, I. (2023). Benchmarking self-supervised contrastive learning methods for image-based plant phenotyping. Plant Phenomics 5, 37. doi: 10.34133/plantphenomics.0037
Pan, Y., Chang, J., Dong, Z., Liu, B., Wang, L., Liu, H., et al. (2025). Pflo: A high-throughput pose estimation model for field maize based on yolo architecture. Plant Methods 21, 51. doi: 10.1186/s13007-025-01369-6
Rodrigues, M. A., Matiz, A., Cruz, A. B., Matsumura, A. T., Takahashi, C. A., Hamachi, L., et al. (2013). Spatial patterns of photosynthesis in thin-and thick-leaved epiphytic orchids: Unravelling c3–cam plasticity in an organ-compartmented way. Ann. Bot. 112, 17–29. doi: 10.1093/aob/mct090
Schamberger, B., Ziege, R., Anselme, K., Ben Amar, M., Bykowski, M., Castro, A. P., et al. (2023). Curvature in biological systems: Its quantification, emergence, and implications across the scales. Advanced materials 35, 2206110. doi: 10.1002/adma.202206110
Scharr, H., Minervini, M., French, A. P., Klukas, C., Kramer, D. M., Liu, X., et al. (2016). Leaf segmentation in plant phenotyping: A collation study. Mach. Vision Appl. 27, 585–606. doi: 10.1007/s00138-015-0737-3
Seng, X., Liu, T., Yang, X., Zhang, R., Yuan, C., Guo, T., et al. (2024). Measurement of the angle between stems and leaves of rice based on key point detection. J. Computing Electronic Inf. Manage. 13, 2413–1660. doi: 10.54097/bev3vbbn
Sheikh, M., Iqra, F., Ambreen, H., Pravin, K. A., Ikra, M., and Chung, Y. S. (2024). Integrating artificial intelligence and high-throughput phenotyping for crop improvement. J. Integr. Agric. 23, 1787–1802. doi: 10.1016/j.jia.2023.10.019
Shi, M., Li, X.-Y., Lu, H., and Cao, Z.-G. (2022). Background-aware domain adaptation for plant counting. Front. Plant Sci. 13. doi: 10.3389/fpls.2022.731816
Shi, W., Koo, D., Kitano, M., Chiang, H., Trinh, L., Turcatel, G., et al. (2020). Pre-processing visualization of hyperspectral fluorescent data with spectrally encoded enhanced representations. Nat. Commun. 11, 726. doi: 10.1038/s41467-020-14486-8
Tan, G. D., Chaudhuri, U., Varela, S., Ahuja, N., and Leakey, A. D. (2024). Machine learning-enabled computer vision for plant phenotyping: A primer on ai/ml and a case study on stomatal patterning. J. Exp. Bot. 75, 6683–6703. doi: 10.1093/jxb/erae395
Weyler, J., Milioto, A., Falck, T., Behley, J., and Stachniss, C. (2021). Joint plant instance detection and leaf count estimation for in-field plant phenotyping. IEEE Robotics Automation Lett. 6, 3599–3606. doi: 10.1109/LRA.2021.3060712
Xiang, L., Gai, J., Bao, Y., Yu, J., Schnable, P. S., and Tang, L. (2023). Field-based robotic leaf angle detection and characterization of maize plants using stereo vision and deep convolutional neural networks. J. Field Robotics 40, 1034–1053. doi: 10.1002/rob.22166
Yin, L., Wang, L., Li, T., Lu, S., Yin, Z., Liu, X., et al. (2023). A novel end-to-end lake boundary prediction model. Land 12, 1602. doi: 10.3390/land12081602
Zhang, S., Song, Y., Ou, R., Liu, Y., Li, S., Lu, X., et al. (2024). Scag: A stratified, clustered, and growing-based algorithm for soybean branch angle extraction and ideal plant architecture evaluation. Plant Phenomics 6, 190. doi: 10.34133/plantphenomics.0190
Zhang, W., Chen, K., Wang, J., Shi, Y., and Guo, W. (2021). Easy domain adaptation method for filling the species gap in deep learning-based fruit detection. Horticulture Res. 8, 119. doi: 10.1038/s41438-021-00553-8
Zhang, Y., Xie, Y., Zhou, J., Xu, X., and Miao, M. (2024). Cucumber seedling segmentation network based on a multiview geometric graph encoder from 3d point clouds. Plant Phenomics 6, 254. doi: 10.34133/plantphenomics.0254
Keywords: leaves skeletonization, angle difference threshold, curvature minimization, keypoints connection, phenotype extraction
Citation: Wang Z, He X, Wang Y, Yang C, Fan B, Zhou Q and Li X (2025) A spontaneous keypoints connection algorithm for leafy plants skeletonization and phenotypes extraction. Front. Plant Sci. 16:1641255. doi: 10.3389/fpls.2025.1641255
Received: 04 June 2025; Accepted: 22 September 2025;
Published: 24 October 2025.
Edited by:
Bijayalaxmi Mohanty, National University of Singapore, SingaporeReviewed by:
Taras P. Pasternak, Miguel Hernández University of Elche, SpainElizabeth Berrigan, Salk Institute for Biological Studies, United States
Copyright © 2025 Wang, He, Wang, Yang, Fan, Zhou and Li. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Xian Li, bGl4aWFuQGNhYXMuY24=