 Yakun Zhang1*
Yakun Zhang1* Ruofei Bao1
Ruofei Bao1 Mengxin Guan1
Mengxin Guan1 Zixuan Wang1Libo Wang2Xiahua Cui3
Zixuan Wang1Libo Wang2Xiahua Cui3 Xiaoli Niu1Yan Wang1Shaukat Ali4
Xiaoli Niu1Yan Wang1Shaukat Ali4 Yafei Wang5*
Yafei Wang5*- 1Department College of Agricultural Equipment Engineering, Organization Henan University of Science and Technology, Luoyang, China
- 2Department College of Food Bioengineering, Organization Henan University of Science and Technology, Luoyang, China
- 3Department College of Biological and Agricultural Engineering, Organization Jilin University, Changchun, China
- 4Department Wah Engineering College, Organization University of Wah, Wah Cantt, Pakistan
- 5Department School of Agricultural Engineering, Organization Jiangsu University, Zhenjiang, China
Soybean is one of the world’s major oil-bearing crops and occupies an important role in the daily diet of human beings. However, the frequent occurrence of soybean leaf diseases caused serious threats to its yield and quality during soybean cultivation. Rapid identification of soybean leaf diseases could provide a better solution for efficient control and subsequent precision application. In this study, a lightweight deep convolutional neural network (CNN) based on multiscale feature extraction fusion (MFEF) and combined with a dense connectivity (DC) network (MFEF-DCNet) was proposed for soybean leaf disease identification. In MFEF-DCNet, a multiscale feature extraction fusion (MFEF) module for soybean leaves was constructed by utilizing a convolutional attention module and depth-separable convolution to improve the model feature extraction capability. Multiscale features are fused by using dense connections (DC) in the backbone network to improve the model generalization capability. Experiments were implemented on eight distinct disease and deficiency classes of soybean images (including bacterial blight, cercospora leaf blight, downy mildew, frogeye leaf spot, healthy, potassium deficiency, soybean rust, and target spot) using the proposed network. The results showed that the MFEF-DCNet had an accuracy of 0.9470, an average precision of 0.9510, an average recall of 0.9480, and an F1-score of 0.9490 for soybean leaf disease identification. And MFEF-DCNet had certain performance advantages in terms of classification accuracy, convergence speed and other effects compared with VGG16, ResNet50, DenseNet201, EfficientNetB0, Xception and MobileNetV3_small models. In addition, the accuracy of the MFEF-DCNet model in recognizing soybean diseases in local data was 0.9024, which indicated that the MFEF-DCNet model had favorable application in practical applications. The proposed model and experience in this study could provide useful inspiration for automated disease identification in soybean and other crops.
1 Introduction
Soybeans are one of the important crops with high protein, high oil, and high nutrition characteristics, widely used in food, feed, industry and other fields (Sun et al., 2018) (Zhu et al., 2019), (Huang et al., 2019). Soybeans are usually processed into protein rich foods or edible oils, which is rich in proteins. In addition, soybean protein isolate hydrogel extracted from soybean contains nearly 20 kinds of essential amino acids for human body (Wang et al., 2023; Ding et al., 2021; Han et al., 2016). Soybean oil can be used as bio-petroleum after chemical conversion, which generates more energy than fossil energy sources (Pradhan et al., 2010). However, in the process of soybean cultivation, the frequent occurrence of soybean leaf diseases has caused huge economic losses, as well as posing a great threat to human health and food security. Soybean yield losses due to disease account for about 8-25% of total soybean production average annual (Savary et al., 2019). In addition to these direct losses, problems caused by the extensive use of pesticides for diseases, such as environmental pollution, soil fertility degradation and increased resistance, have become important obstacles to the sustainable cultivation of soybeans. During the soybean growing process, the types of soybean diseases could be accurately recognized in time and agricultural chemicals could be applied accordingly. Then soybean cultivation will develop in a sustainable direction to better meet the world’s demand for soybeans. The kinds of soybean diseases can be manifested on the leaves, such as discoloration, spots, holes, etc. These diseases can be identified by experienced farmers or experts based on disease characteristics. However, in general, it is difficult to achieve rapid and accurate diagnosis of soybean diseases due to the lack of relevant professional experience and disease identification knowledge among soybean farmers, which has become a bottleneck restricting the development of the soybean industry.
With the advancements in computer vision and deep learning techniques, automated recognition of images has made significant progress in terms of accuracy, recognition efficiency and economic utility. In recent years, various methods had been attempted to be applied to automated crop disease diagnosis, including K-nearest neighbor classifier (Chen et al., 2025), color transformation and histogram methods (Rachmad et al., 2023), support vector machine (SVM) (Chen et al., 2024; Sun et al., 2016; Wang et al., 2022), convolutional neural network (CNN) (Mahmood ur Rehman et al., 2024; Qiu et al., 2024; Sun et al., 2018). In terms of disease recognition performance, CNN was currently the most effective.
CNN (Zhang and Dai, 2025) is a special class of artificial neural networks with the main characteristics of convolutional operation compared with other neural network models (Zhiming et al. 2024; Weidong et al. 2022). CNN combines the advantages of convolutional kernel local feature extraction and BP neural network back propagation. Through local feature extraction and backward weight sharing operation, CNN achieves the reduction of the number of parameters and the improvement of network generalization ability (Shengyi et al. 2021). Currently, convolutional neural networks have great potential in agriculture, especially in agricultural image processing (Archana and Jeevaraj, 2024; El Sakka et al., 2025; Jiehong et al. 2023). In response to the difficulty of effectively extracting soybean diseased leaves from complex backgrounds, Aditya et al. proposed a SoyNet model based on computer vision and convolutional neural network, which realized the effective separation of soybean diseased leaves from complex backgrounds, with a model classification accuracy of 98.14% (Karlekar and Seal, 2020). Wu et al. developed an enhanced deep learning network model for predictive classification of soybean leaf diseases with an average recognition accuracy of 85.42% through feature extraction, attention computation and classification (Wu et al., 2023). Sandeep et al. developed a novel deep learning model based on convolutional neural networks for classification of soybean leaf pests and diseases, which is also capable of disease level prediction (Goshika et al., 2023). Vivek et al. designed the SoyaTrans model by combining the CNN architecture with a swin-transformer, which improves the classification performance and reduces the complexity of the model by introducing a new random shift mechanism (Sharma et al., 2025).
However, most of the existing soybean leaf disease identification methods suffer from complex models, time-consuming, and computational resource-consuming problems, which made these methods difficult to satisfy the production demands for rapid disease detection, especially when deployed and implemented on mobile devices. Therefore, the focus of this study was to improve the convergence speed and model lightweight of convolutional neural networks while ensuring the recognition accuracy. The goal of this study was to develop a lightweight automatic classifier for digital images of soybean diseases based on CNN. By using multi-scale feature extraction and fusion modules, the classifier can better extract feature information from images. And data expansion method was used to balance the data samples between each category to prevent model overfitting. An image enhancement algorithm was also used to enhance the input soybean disease images to improve the applicability of the classifier. The soybean disease identification network designed in the study can accurately identify common soybean leaf disease categories for efficient and accurate classification and decision making.
2 Materials and methods
2.1 Database set
The dataset used for the study was the Auburn Soybean Disease Image Dataset (ASDID), which is publicly available and has been extensively studied and validated (Bevers et al., 2022). The dataset contains 9648 soybean leaf images, of which 4,181 were taken in 2020 and 5,467 in 2021. The dataset contains eight main categories: bacterial blight (Figure 1A), cercospora leaf blight (Figure 1B), downey mildew (Figure 1C), frogeye leaf spot (Figure 1D), healthy (Figure 1E), potassium deficiency (Figure 1F), soybean rust (Figure 1G), target spot (Figure 1H). The ASDID dataset were used to construct soybean disease identification model.

Figure 1. Example images of eight soybean leaf diseases: (A) Example image of soybean leaf with bacterial blight; (B) Example image of soybean leaf with cercospora leaf blight; (C) Example image of soybean leaf with downey mildew; (D) Example image of soybean leaf with frogeye leaf spot; (E) Example image of soybean healthy leaf; (F) Example image of soybean leaf with potassium deficiency; (G) Example image of soybean leaf with rust; (H) Example image of soybean leaf with target spot.
The original 9648 images were randomly divided in the ratio of 9:1, of which 8686 were used for model training and validation, and 962 were used for model testing. Table 1 showed the division of the data according to the 9:1 ratio. Figure 1 showed examples of soybean leaves photographed for all eight disease categories.
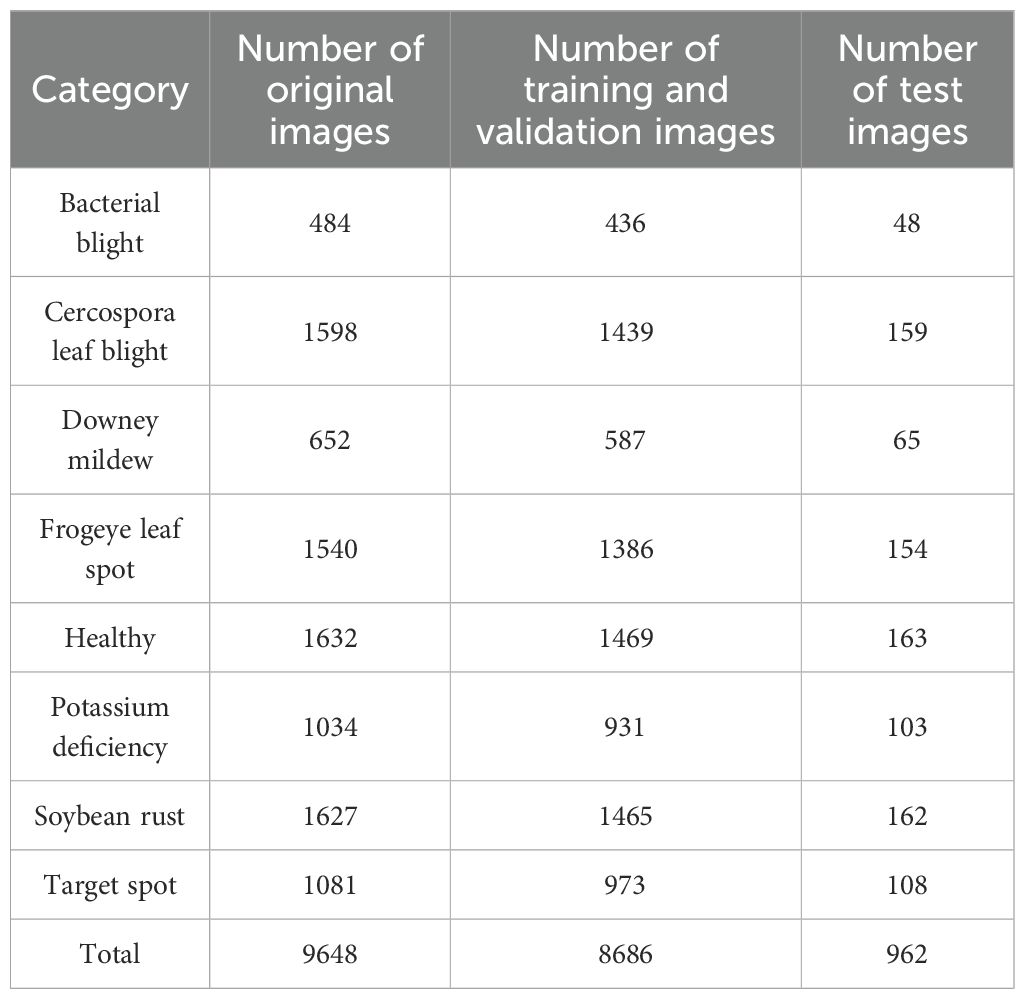
Table 1. Division of original data.
In addition, in order to verify the adaptability and local application effect of the constructed model, 164 images of four categories of soybean leaves were collected at Dayuzhuang, Lanqing Township, Zhengyang County, Zhumadian City, Henan Province (32027’ 37’’N, 11420’ 11’’E). There were 48 images of bacterial blight, 52 images of frogeye leaf spot disease, 35 images of healthy leaves and 29 images of soybean rust. Soybean leaf images were collected on August 22, 2020. After completing the construction and training of the MFEF-DCNet model, the collected images of soybean leaves were input into the trained MFEF-DCNet model to test the application effect of the model in practice.
2.2 Data balance
As shown in Table 1, the number of healthy samples used for training and validation was 1469, while the number of bacterial blight was 436. The ratio of the number of healthy samples to the number of bacterial blight samples was greater than 3:1, indicating that the distribution of samples shown a serious imbalance. In CNN, imbalance in sample distribution may lead to overfitting problems in network models. In addition, sample data with differences between different categories could severely affect the accuracy of network training and limit network performance (Buda et al., 2018). Therefore, a data balancing algorithm was introduced before using the data for training (Gao et al., 2021).
The above sampling method was used to balance the sample data, which enhanced the generalization ability of the network. The method was as follows:
(1) Index building: Firstly, the expression of the datasets was defined as , in which represented the type of soybean leaf disease, and was the number of samples which corresponded to . Then the maximum number of samples in the datasets and its corresponding were counted. Finally, the maximum value was expressed by , while marked the type which corresponded to , in which i expressed the label serial number (Label 0 indicated bacterial blight, Label 1 indicated cercospora leaf blight, Label 2 indicated downey mildew, Label 3 indicated frogeye leaf spot, Label 4 indicated healthy, Label 5 indicated potassium deficient, Label 6 indicated soybean rust, Label 7 indicated target spot).
(2) Calculation of the proportionality constant C: was chosen as the numerator and was selected as the denominator. The constant C was calculated according to Equation 1.
(3) Up-sampling: the proportionality factor was obtained from Equation 1. Smaller numbers of samples were up-sampled using different methods based on the proportionality constant. Data balancing was achieved by complex up-sampling, which is implemented by taking different up-sampling measures according to the size of the proportionality factor , as shown in Equation 2:
(4) Exportation: was the balanced output, where was calculated from Equation 3.
In the calculated datasets, D={[M0 indicated bacterial spot, M1 indicated caecilian leaf blight, M2 indicated downy mildew, M3 indicated frogeye leaf spot, M4 indicated healthy, M5 indicated potassium deficiency, M6 indicated rust, M7 indicated target spot][N0 = 436, Nl = 1439, N2 = 587, N3 = 1386, N4 = 1469, N5 = 931, N6 = 1465, N7 = 973]T}, the sample number of bacterial blight was the lowest while healthy sample number leaf sample was the highest.
Since was 1469, was equal to 3 according to Equation 1, 2. That means 3 was calculated by dividing 1469 by 436 using the floor principle. The bacterial blight dataset was balanced by an increase of 200% in the number of bacterial blight samples through rotation and contrast adjustments.
According to the above method, the proportionality constants for each disease type sample were calculated based on the data in Table 2. On the basis of Equation 3, , , , , , , , were obtained as follows:
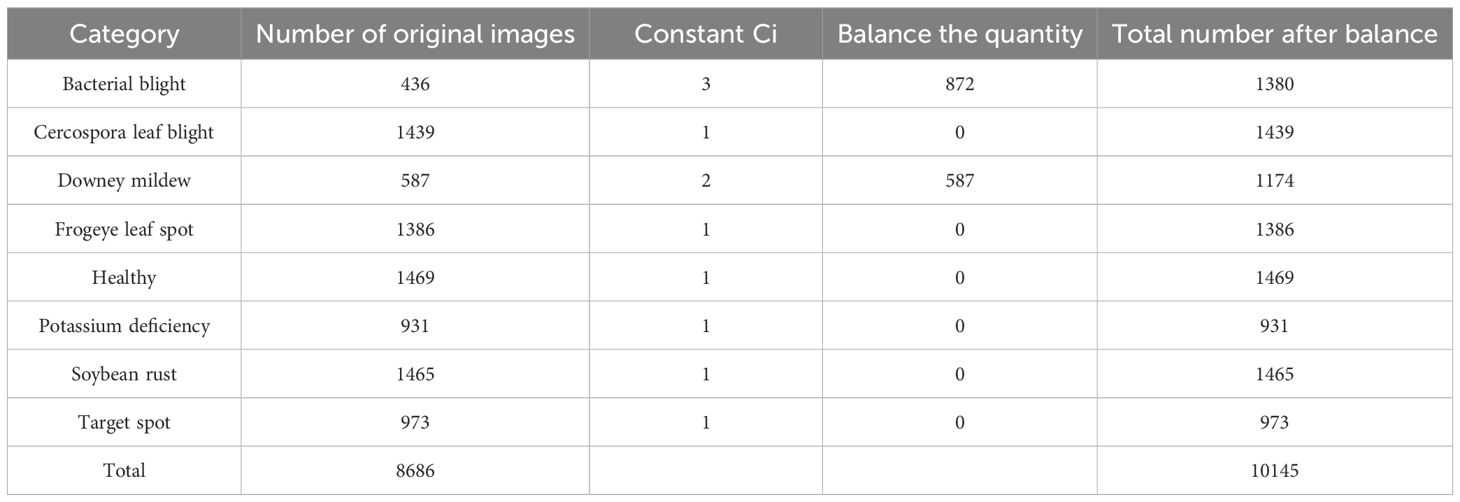
Table 2. Number of categories before and after data balance.
Table 2 displayed the sample distribution of each dataset type after data balancing. As shown in Table 2, the maximum number of healthy leaves after data balancing was 1469 and the minimum number of potassium deficient leaves after data balancing was 931. The ratio of the two sample datasets was approximately 1:1.57, which indicated a more balanced distribution of sample data.
When the number of images in each category was roughly the equal, the model could better learn the features of each category and avoid overfitting or underfitting of some categories.
2.3 Data enhancement
Image enhancement was a conventional data preprocessing method used to improve inter-class parity and increase the size of training samples. This method was accomplished by employing various transformations such as rotating, scaling, reflecting, adjusting brightness, and adding noise to the original image. ImageDataGenerator in Keras was able to enhance the data in a fast way (Abadi et al., 2016). Therefore, in the study, ImageDataGenerator was used to perform shift, brightness change, flip, rotate, and normalization operations on the data in the training set and normalization operations on the data in the validation set. Figure 2 showed the effect comparison before and after image enhancement of soybean leaves. Figure 2A showed the original image of soybean leaf with bacterial blight; Figure 2B showed the original image of soybean leaf with cercospora leaf blight; Figure 2C showed the original image of soybean leaf with downey mildew; Figure 2D showed the original image of soybean healthy leaf; Figure 2E showed the image obtained after flip for original image of soybean leaf with bacterial blight; Figure 2F showed the image obtained after rotation for original image of soybean leaf with cercospora leaf blight; Figure 2G showed the image obtained after moving vertically for original image of soybean leaf with downey mildew; Figure 2H showed the image obtained after moving horizontally for original image of soybean healthy leaf.

Figure 2. Comparison before and after image enhancement: (A) Origional image of soybean leaf with bacterial blight; (B) Origional image of soybean leaf with cercospora leaf blight; (C) Origional image of soybean leaf with downey mildew; (D) Origional image of soybean healthy leaf; (E) Image obtained after flip for original image of soybean leaf with bacterial blight; (F) Image obtained after rotation for original image of soybean leaf with cercospora leaf blight; (G) Image obtained after moving vertically for original image of soybean leaf with downey mildew; (H) Image obtained after moving horizontally for original image of soybean healthy leaf.
2.4 Model design
2.4.1 Block construction
The attention mechanism was a technology inspired by the human visual and cognitive system, which allowed CNN to focus on processing the relevant parts of the input data. By using the attention mechanism, CNN could automatically learn and focus on the important information in the input, thus improving the generalization ability of the model. Convolutional Block Attention Module (CBAM) was a simple and effective lightweight attention module for feed-forward CNN, which consisted of a channel attention module (CAM) and a spatial attention module (SAM) (Woo et al., 2018).
CAM was used to learn the channel weights using a shared fully connected layer and activation functions. SAM was used to compute the spatial weights of the feature maps using the maximum pool and the average pool. Thus, the CBAM module was able extract the feature information in the feature map more efficiently when training the neural network. CBAM could be used in various CNN architectures, and has been widely applied with remarkable performance to tasks such as image classification (Guo et al., 2025), target detection (Pei, 2022), instance segmentation (Ma et al., 2024).
The multiscale feature extraction and fusion for soybean leaves (MFEF-SL) module was constructed in this research. On the one hand, the input feature layer was extracted by two depthwise separable convolutions and batch normalization, and then the feature layer was reduced by maximum pooling. On the other hand, the feature filtering and size adjustment of the feature map were realized by convolution attention module, ordinary convolution and batch normalization. In the network structure, the module original input feature layer was spliced in the channel direction after maximum pooling and batch normalization. The merging of the above two aspects was realized through the summation of the corresponding elements, and the output was finally obtained. The specific network structure connection was shown in Figure 3.
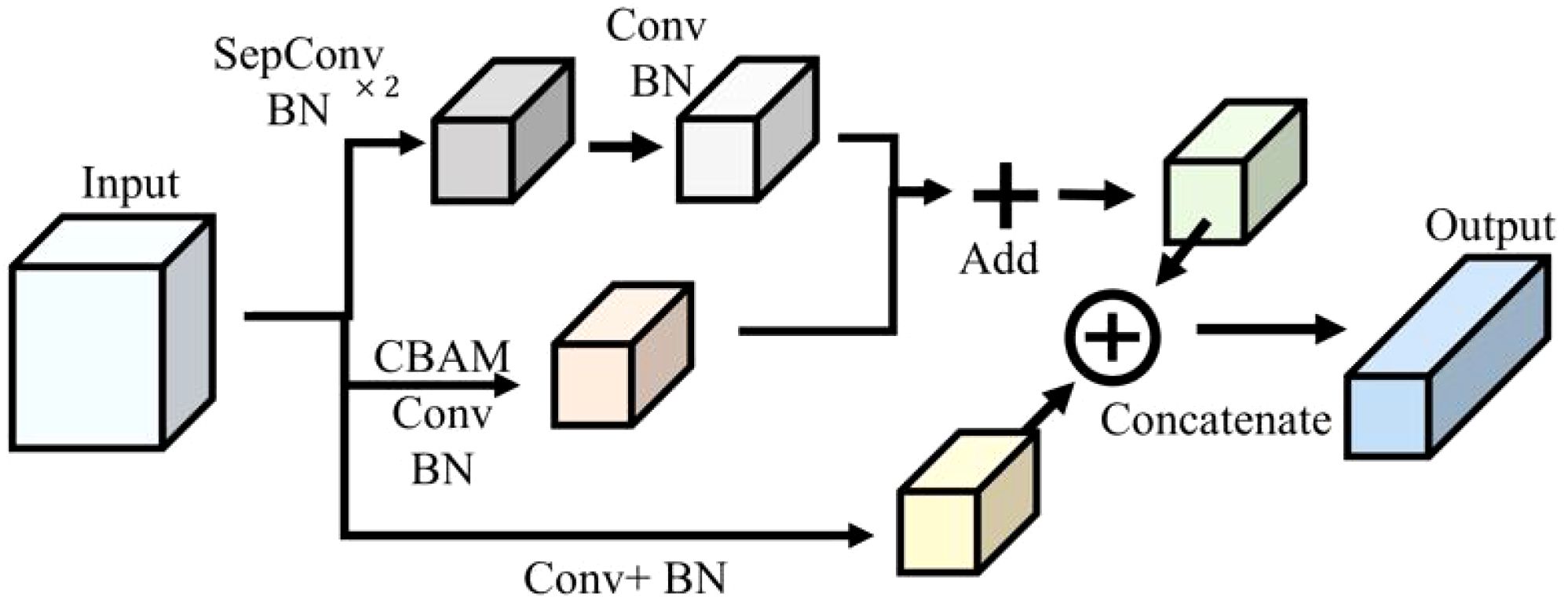
Figure 3. Multiscale feature extraction and fusion for soybean leaves.
2.4.2 MFEF-DCNet
DenseNet was a densely connected neural network architecture (Huang et al., 2017). This network architecture was realized by establishing direct connections between the outputs of each layer and the inputs of all subsequent layers, whereby the outputs of each layer were directly connected to all previous layers. The dense connection allowed the output of each layer to be used directly by the subsequent layers. This approach improved the efficiency of feature transfer, which in turn enhanced the convergence speed and accuracy of the model (Zhang et al., 2024). DenseNet has achieved outstanding performance in various image classification and target detection tasks (Zhang et al., 2025). Meanwhile, the idea of dense connection was also used in the architecture of model design (Xu et al., 2024). It exhibited strong feature extraction and usage capabilities while maintaining computational efficiency.
The multiscale feature extraction fusion dense connected network (MFEF-DCNet) for soybean leaves proposed in this study was mainly constructed by the modules of convolutional layer, MFEF-SL, global average pooling and fully connected layer. The network structure was shown in Figure 4.

Figure 4. MFEF-DCNet.
Firstly, the input image was subjected to initial feature extraction by two convolutions. Secondly, higher latitude feature extraction was performed by four MFEF-SL module operations. For high-latitude feature extraction, dense connection was used between MFEF-SL Blocks. Namely, the input of each block was the splicing result after pooling the output of the previous block. In addition, due to the fact that the size of the feature map was halved after the operation of the MFEF-SL modules, the same image size was ensured by a maximum pooling operation before performing a dense join, as shown by the dotted line join in Figure 4. Thirdly, a global average pooling and a fully connected layer of eight neurons were performed. Finally, the probabilities of the eight categories are output after passing the Softmax activation function.
2.4.3 Training
During model training, a stochastic gradient descent optimizer was used to reduce the loss values. The learning rate set was 1e-4, momentum was 0.9, loss function was categorical cross entropy, batch size was 32, and the initial training epoch was 100. All the models were trained from the scratch.
2.4.4 Evaluation
The performance of a model was usually evaluated using test set data. Therefore 962 images from the original dataset were used to exam the performance of the model. Model evaluation indexes, such as accuracy, precision, Recall, F1-Score, and the corresponding macro average and weighted average, were used for model evaluation. Accuracy is usually considered as the overall performance of the model and is used to calculate the correctly recognized labels.
Precision (P) is used to assess the accuracy of the recognitions by comparing the number of correctly recognized images for a disease category to the total number of images recognized by the model for that category.
Recall (R) is used to measure the ability of the model to cover positive class samples, and is defined as the number of correctly recognized positive samples divided by the total number of positive samples.
F1-Score (F) is the weighted harmonic mean of precision and recall. When the F1-Score is closer to 100% it indicates that the recognition performance of the model is better.
In the above equation, TP represents True Positive, FP represents False Positive, TN represents True Negative, and FN represents False Negative.
Macro average is calculated by averaging the precision, recall and F1 score for each category. Thus, macro precision, macro recall and macro F1 score are calculated. However, when there is a serious category imbalance in the dataset, it is not appropriate to use macro average as an evaluation index, instead weighted average is used as the evaluation index. Weighted average assigns different weights to each class based on the ratio of the sample size of each class to the total sample size. The corresponding weighted precision, weighted recall, and weighted F1-Score are then calculated based on the weights.
3 Results
3.1 Model performance comparison
Table 3 displayed the training results and model parameter information based on the MFEF-DCNet, MobileNetV3_small, EfficientNetB0, VGG16, DenseNet201, Xception, and ResNet50 models. The training of all these models was trained from the scratch. In the table, the total parameters were the sum of trainable and non-trainable parameters, which was a reference indicator of the model capacity. The non-trainable parameters were usually set when the model was built and remained constant throughout the training process. During the training process, the trainable parameters were adjusted according to the training data to enable the model to fit the data better. It could be seen from the table that MobileNetV3_small had the lowest single epoch training time among all models. However, the final performance of MobileNetV3_small was poor with an accuracy of 0.9013. Therefore, MobileNetV3_small was not able to meet the practical requirements. Although MFEF-DCNet was longer than MobileNetV3_small in terms of training time for a single epoch, the model achieves a test precision of 0.947 due to the well-designed and optimized structure of MFEF-DCNet. In addition, although the MFEF-DCNet model was the most lightweight with a minimum total parameter of 1,200,104, the values of precision, recall and F1 score in MFEF-DCNet were exceed 0.95. Therefore, the comprehensive performance of MFEF-DCNet was the best among the all mentioned models.
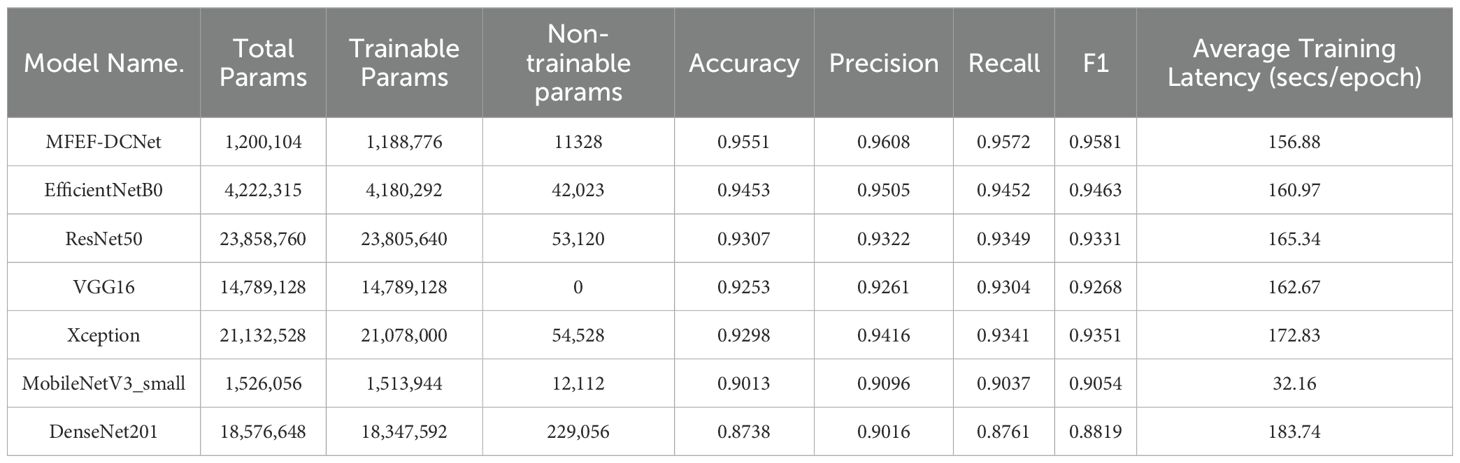
Table 3. Number of categories before and after data balance.
The accuracy curves comparison for the training process of all models were depicted in Figure 5. By analyzing the accuracy curve of MobileNetV3_small, it can be found that the training accuracy was increasing at the beginning. After 30 epochs, the training accuracy tended to stabilize. However, the final accuracy of MobileNetV3_small was low, which cannot satisfy the requirements of real production environment. In addition, it can be observed that MFEF-DCNet shown the fastest convergence rate in the first 10 epochs from Figure 5. Meanwhile, the MFEF-DCNet model also achieved excellent results in the later stages of training with the accuracy around 0.9551. The loss value curves for different models were shown in Figure 6. The loss values shown in the vertical coordinates in Figure 6 indicated the difference between the model recognized outputs and the actual labels. A smaller loss value means a better performance of the model, while a larger loss value means a larger difference between the model recognized results and the real results. As can be seen from the training loss curve, MFEF-DCNet decreased the fastest in the first 5 epochs, and the loss value reached its minimum in the final stage of model training. After 100 Epochs of training, MFEF-DCNet had an accuracy of 0.9551 on the training set.
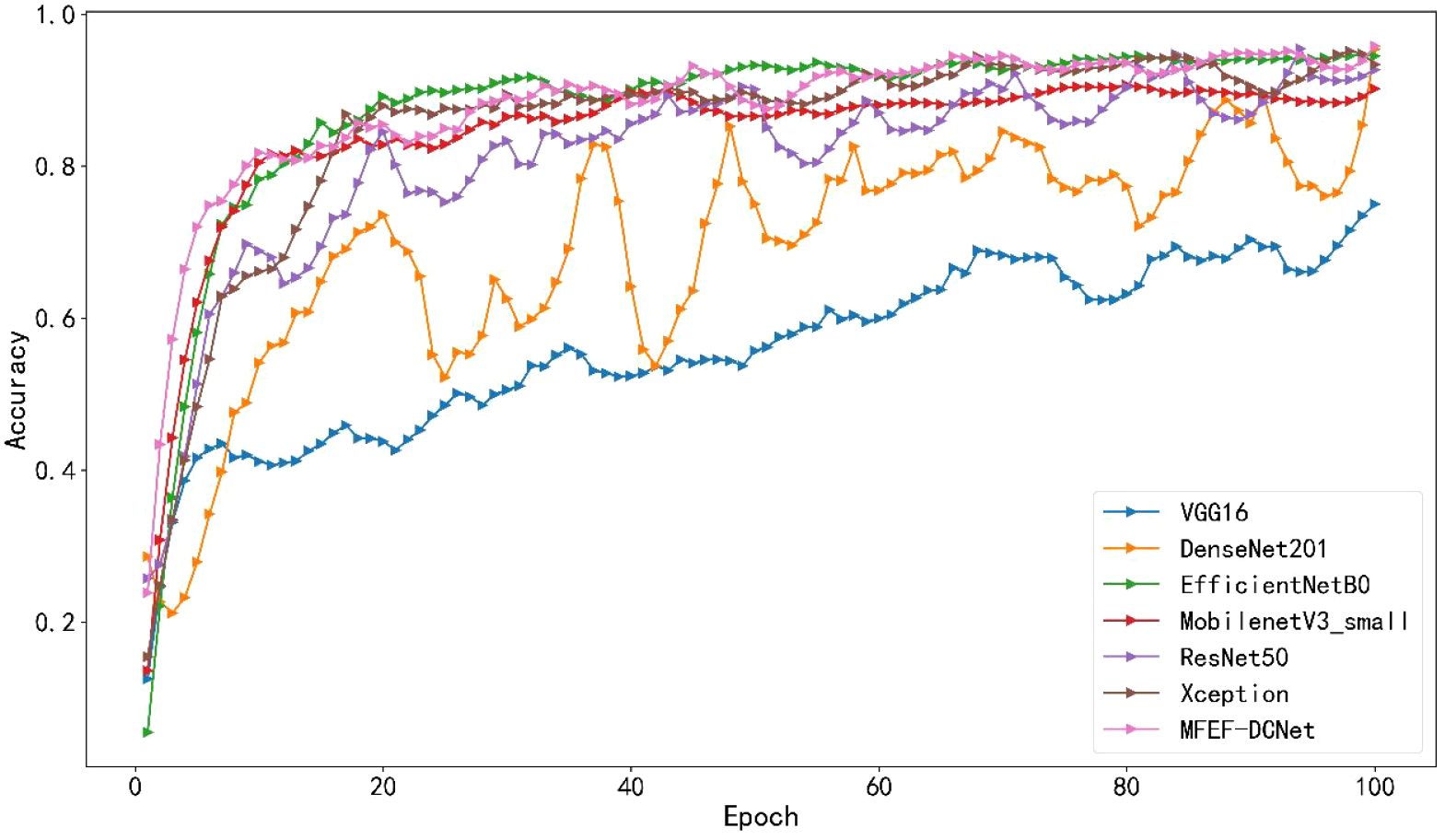
Figure 5. Accuracy curves of different models.
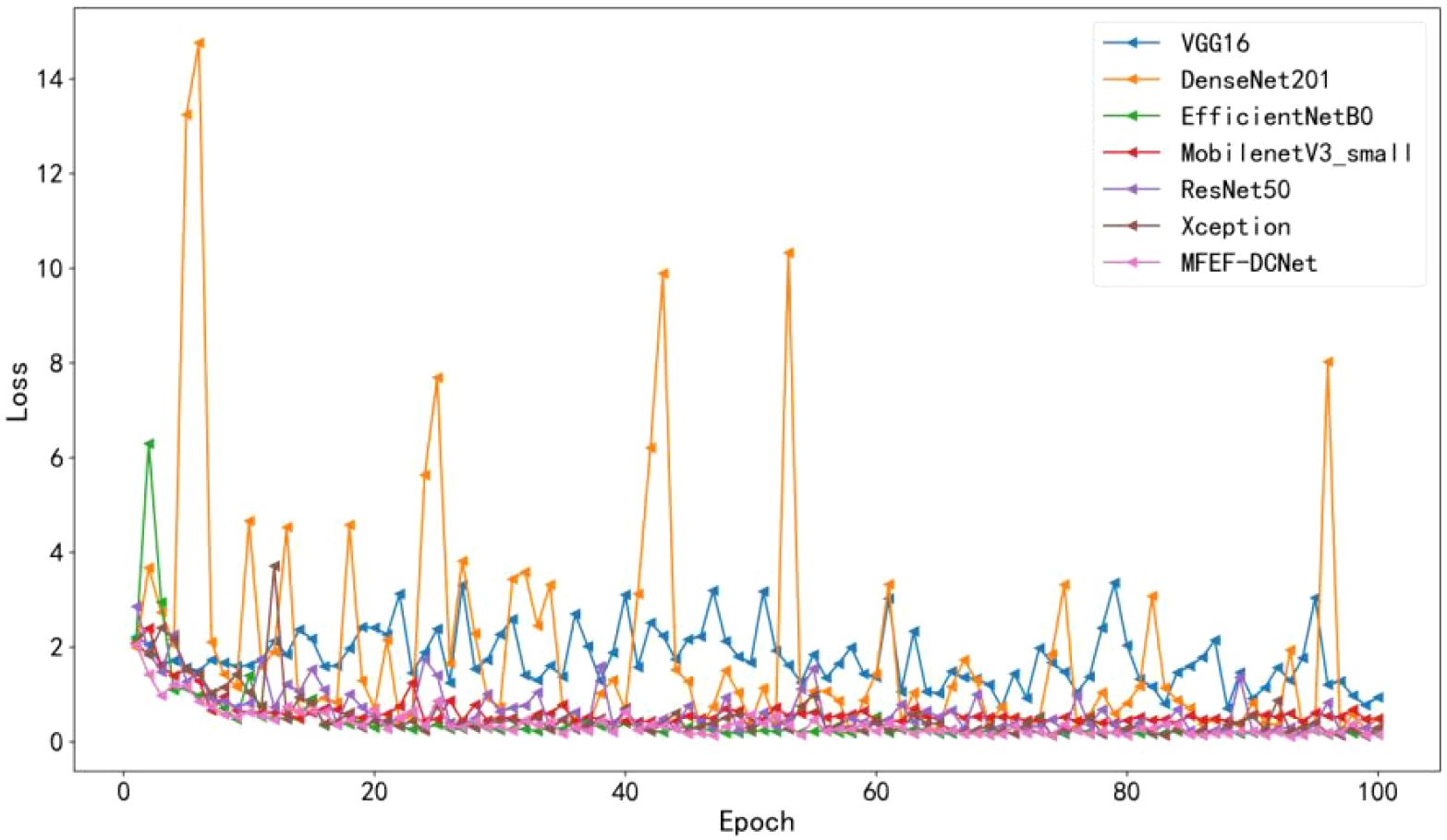
Figure 6. Loss value curves of different models.
After 100 epochs of training from scratch, the best trained weights were selected for all models and these weight coefficients were tested on a total of 962 test images that the models had never trained before. The test results of different models for different soybean leaf disease categories were shown in Table 4. It was evident from the table that the proposed MFEF-DCNet performs better than other models in the vast majority of recognition results. And the accuracy, macro accuracy, and weighted accuracy of the MFEF-DCNet model all greater than 0.94. In terms of the recognition results for the different soybean leaf disease categories, the MFEF-DCNet model had relatively poor recognition precision for the health category. In terms of recall, the MFEF-DCNet model had relatively poor recognition accuracy for frogeye leaf spot, and the model was able to correctly recognize 139 out of 154 disease images with a recognition recall of 0.9026. While the MFEF-DCNet model performed the best for downey mildew and potassium deficiency. All images of the two categories for soybean leaf diseases were correctly recognized with a recognition precision of 1.0000. In addition, the MFEF-DCNet model showed a small difference in recognition results between the different disease categories of soybean leaves. This indicated that the model achieved good performance for each category without overfitting or underfitting. Among the 962 test images, the MFEF-DCNet model correctly recognized a total of 911 images eight categories with an accuracy of 0.947. This result was the best among the all models used in this study. Figure 7 showed the confusion matrix drawn by the MFEF-DCNet model after testing on 962 images. The numbers on the diagonal of the confusion matrix represented the counts that the recognitions of the model matched the true labels. From the confusion matrix, it was evident that the proposed MFEF-DCNet model achieved satisfactory results in all categories of test images.
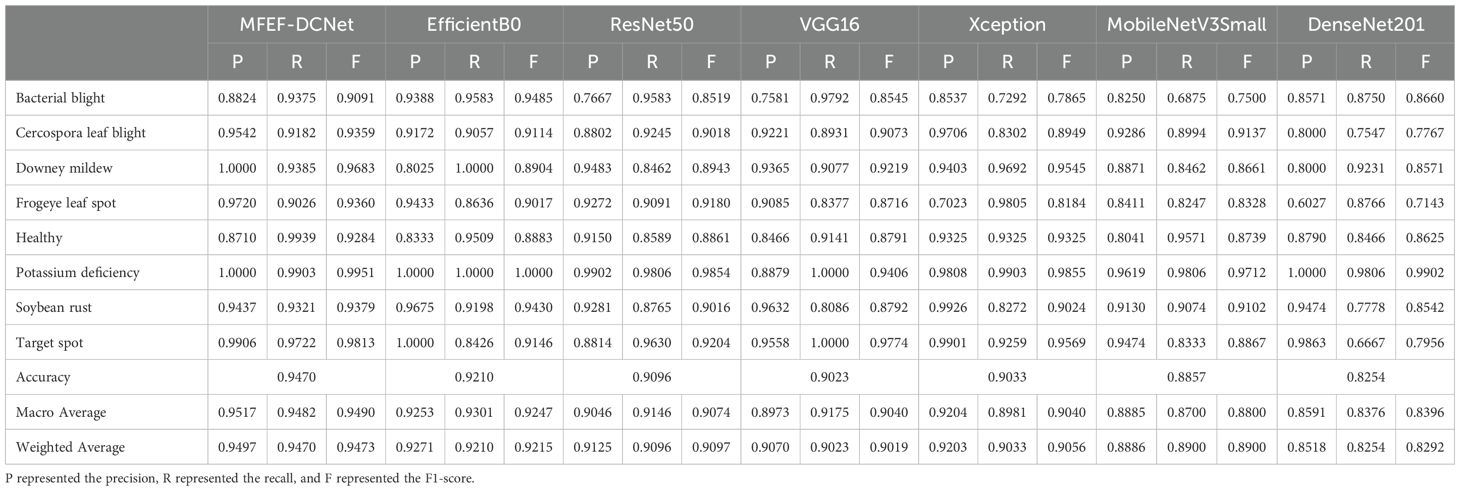
Table 4. Classification training results of different network models.
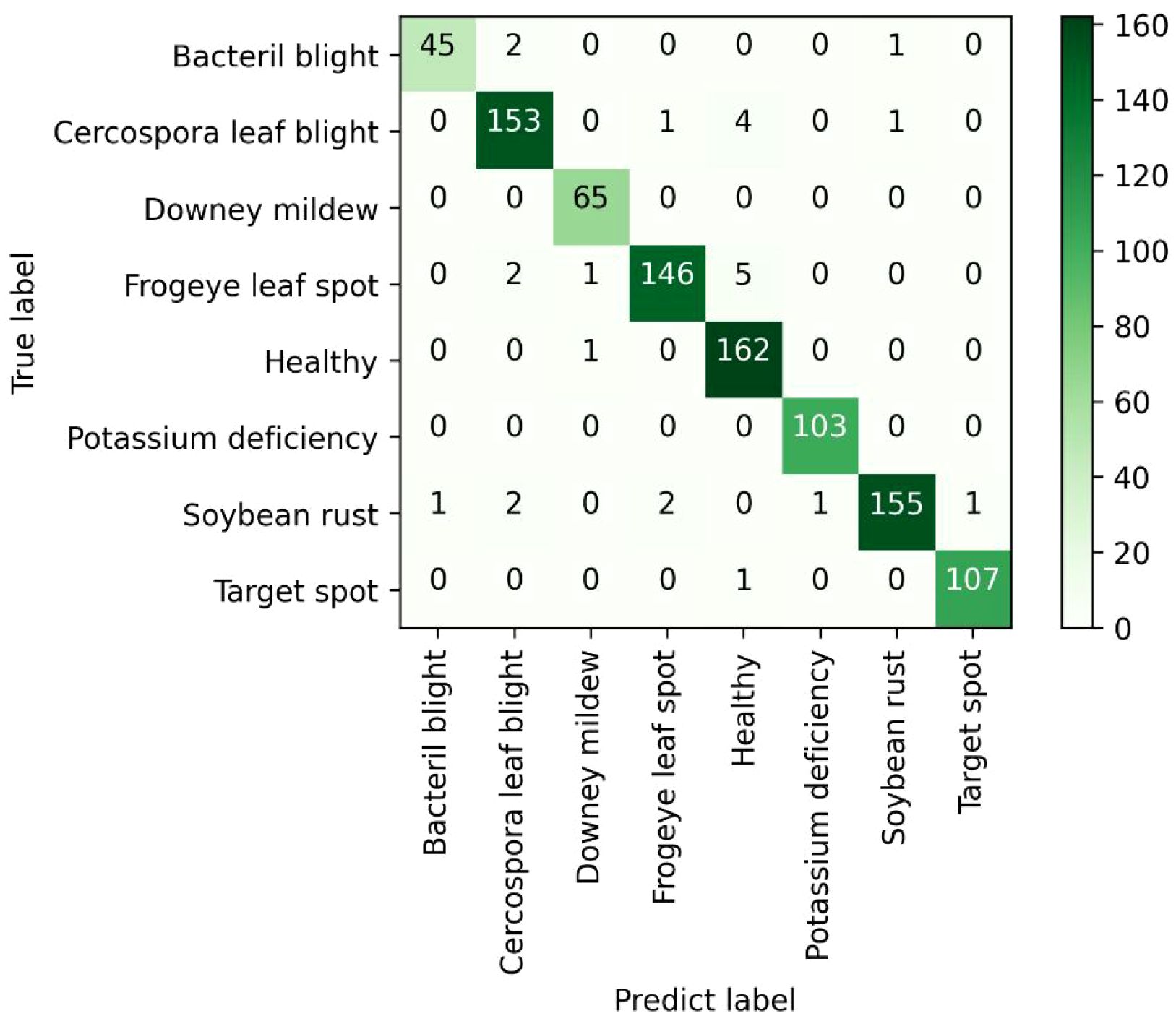
Figure 7. Confusion matrix.
3.2 Ablation study and local data testing
The ablation experiments were conducted as shown in Table 5. As can be seen from the table, the standard convolutional model had 6.66 million parameters, with an accuracy rate of 91.79% and an F1-score of 91.97%. Using the standard convolutional model as a baseline, when the CBAM module was introduced separately, the number of model parameters increased by 0.09M, yet the accuracy and F1-score improved by 0.52% and 0.55%, respectively. When replacing the standard convolution module with a separable convolution module, the number of model parameters was significantly reduced by 83.4%, with the parameters of 1.11 million. Meanwhile, model accuracy and F1-score improved by 2.08% and 1.92%, respectively. When the separable convolution and CBAM modules were introduced simultaneously, the model parameters reduced by 82.0%, while the model performance was the best, with an accuracy and F1-score of 94.70% and 94.73%, respectively. The accuracy and F1-score were improved by 2.91% and 2.76%, respectively. The above results indicated that separable convolutions had a good effect on model parameter compression, while the CBAM module can further enhance the model’s recognition capabilities through feature enhancement. Therefore, the MFEF module constructed by combining separable convolution and CBAM could significantly improve the recognition performance of the model, which provided technical support for the deployment of lightweight disease recognition models in practical scenarios.

Table 5. Comparison of ablation study results.
In order to further verify the adaptability and actual application effect of the MFEF-DCNet model, the 164 local images of soybean leaves, which were collected in Dayuzhuang, Lanqing Township, Zhengyang County, Zhumadian City, Henan Province, were input into the MFEF-DCNet model. The recognition results of the model were shown in Table 6. As shown in the table, the average accuracy of the MFEF-DCNet model for four categories of soybean leaves was 0.9024, and the macro-mean and weighted mean of the model were around 0.9. The results indicated that the MFEF-DCNet model had a satisfactory recognition effect for the local soybean leaves. At the same time, it was shown that MFEF-DCNet had better application effect in practical applications. It also showed that the MFEF-DCNet model had a favorable application effect in practical applications.
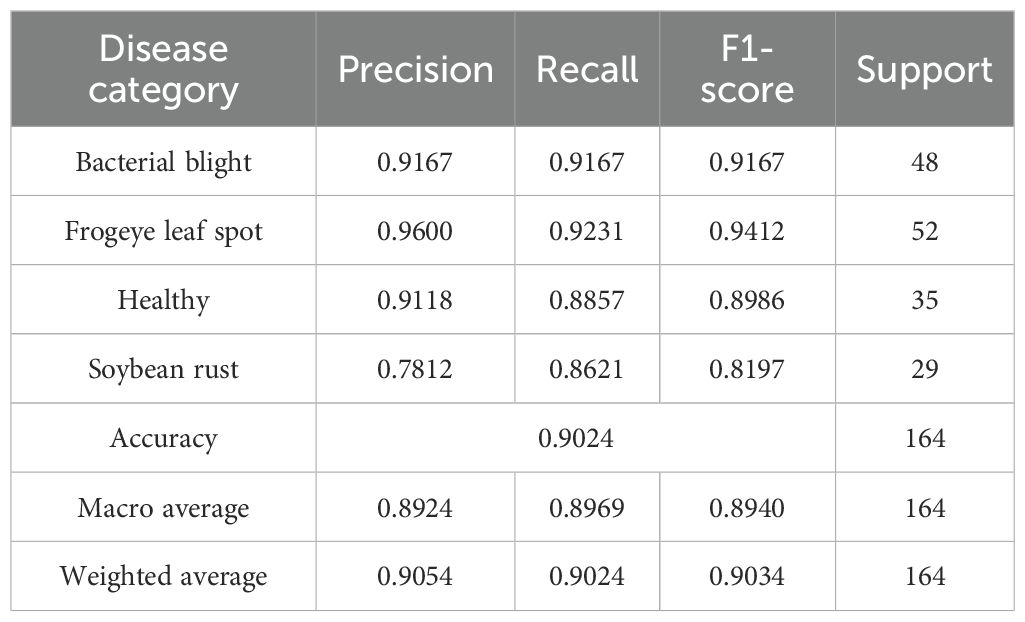
Table 6. Evaluation results of MFEF-DCNet model on different categories of local soybean images.
3.3 Visualization
Feature map visualization was a technique for understanding deep learning models, which is useful for observing the intermediate results produced by the model while processing the input data. By visualizing the feature map, the model’s ability to interpret the input data and extract features could be quantified and demonstrated, which in turn contributed to optimizing the performance of the model. Figures 8 and 9 illustrate the process of visualizing the feature map of downy mildew using MFEF-DCNet. Figure 8 showed the image of downy mildew as input to the neural network, and Figure 9A, Figure 9B and Figure 9C showed the feature maps of downy mildew at different depths of the model during the forward process [Early stage (Figure 9A), Mid stage(Figure 9B), Last stage (Figure 9C)]. According to the feature maps of different periods, it can be seen that the shallow information extracted by the model is mostly edges and textures. With the depth of the network, what MFEF-DCNet learns became more and more abstract, and the extracted features became richer and richer. However, the visual interpretability of these features was also getting decreasing.

Figure 8. Soybean downy mildew leaves.

Figure 9. Characteristic map of soybean downy mildew in different periods: (A) Feature map (Early stage); (B) Feature map (Mid stage); (C) Feature map (Last stage).
By mapping the visualized feature map to the original image, the change of the network focus during the network training process could be observed. Figures 10A–C were the heat maps of different stages of the model by mapping the feature maps after visualization to the original image [Early stage (Figure 10A), Mid stage (Figure 10B), Last stage (Figure 10C)]. From the figures, we can see that the attention of the network gradually approaches towards the direction of the disease features during the learning process of the neural network.

Figure 10. Heat map of soybean downy mildew in different periods: (A) Heat map (Early stage); (B) Heat map (Mid stage); (C) Heat map (Last stage).
According to the heat maps of different periods, it can be seen that the focus of the model was gradually approaching towards the direction of downy mildew disease characteristics in the process of neural network learning.
4 Discussion
The goal of this study was to develop an efficient, lightweight, and highly accurate network model for soybean leaf diseases identification. Based on the open-source dataset, operations such as rotating, cropping, and flipping the original images of soybean diseases were implemented by data balancing algorithms and image enhancement technology. These operations improved the balance of sample data while expanding the sample size. After that, the study constructed a multiscale feature extraction module for soybean leaves using CBAM and depthwise separable convolution, which was used to improve the feature extraction capability of the model. Meanwhile, the fusion among multi-scale feature layers was achieved by using dense connections in the model backbone network to improve the generalization ability. Existing soybean leaf pest and disease identification methods cannot simultaneously meet requirements in terms of identification accuracy (Kang et al., 2025) and model size (Miao et al., 2023). In comparison, several aspects such as model lightweighting, pest types, and accuracy were comprehensively considered in this study. After training and optimization, the MFEF-DCNet constructed in this study had the best results in terms of accuracy, model convergence speed, and precision, with the highest accuracy rate of 0.947, and is friendly for deployment on edge devices. The results of tests on multiple data sets indicate that MFEF-DCNet has good effectiveness and superiority in soybean leaf disease identification.
A lot of attempts were made during the construction and testing of the model. For example, several auxiliary classifiers were added to the model during the training process in order for the model to converge faster during the training process. However, the presence of the auxiliary classifiers had not enhanced the accuracy of the model from the training results obtained. Conversely, this operation consumed more arithmetic power. Therefore, no auxiliary classifiers were added to the final model construction. In addition, the residual structure was not used in the module when using the convolutional attention module. This is because the use of the residual structure was verified to have no significant improvement on the final model performance.
The MFEF-DCNet model proposed in this study achieved effective identification of eight diseases of soybean and achieved good results. However, the study in this paper still has some shortcomings and needs to be further improved in the future. The MFEF-DCNet model was able to classify each disease category in soybean leaf disease identification, but it was unable to realize the judgment of disease degree at the same time of disease identification. The essence of neural network classification is to assign pre-trained disease category probabilities to the image data of each input network. The disease category with the highest probability was ultimately selected as the disease category for the input image. Therefore, the model was only able to identify one of the diseases when multiple diseases are present in a leaf and is unable to accurately identify the other disease categories at the same time. Simultaneous identification of multiple diseases in a picture and the degree of disease was a direction for further research.
5 Conclusions
In this study, MFEF-DCNet, a lightweight deep convolutional neural network, was constructed for soybean leaf disease identification based on the open-source soybean leaf disease dataset. The training inference efficiency and identification accuracy of the model were improved by employing the soybean leaf multi-scale feature extraction fusion module, namely the dense connectivity and CBAM module. In comparison with other common identification models, MFEF-DCNet achieved a maximum accuracy of 0.947 while being lightweight. And its recognition accuracy for local soybean leaf diseases was 0.9024. Meanwhile, the heat map analysis showed that the leaf disease region features were correctly learned by MFEF-DCNet. Overall, future research would continue to deepen the problem of soybean disease recognition. More advanced deep learning techniques and methods would be attempted to contribute to the development and security of the soybean industry.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding authors.
Author contributions
YZ: Conceptualization, Data curation, Formal analysis, Funding acquisition, Methodology, Project administration, Resources, Validation, Writing – original draft, Writing – review & editing. RB: Data curation, Formal analysis, Methodology, Validation, Writing – review & editing. MG: Methodology, Validation, Writing – review & editing. ZW: Data curation, Formal analysis, Validation, Writing – review & editing. LW: Investigation, Software, Writing – review & editing. XC: Investigation, Project administration, Writing – review & editing, Software. XN: Investigation, Supervision, Validation, Writing – review & editing. YW: Data curation, Investigation, Software, Writing – review & editing. SA: Writing – review & editing, Resources. YFW: Conceptualization, Project administration, Supervision, Writing – original draft.
Funding
The author(s) declare financial support was received for the research and/or publication of this article. This research was funded by the National Natural Science Foundation of China (Grant No. 32501779), Henan Provincial Science and Technology Research Project (No.242102111185, No. 252102521059), 2024 Henan Science and Technology Commissioner Project, Collaborative Education Project of Ministry of Education (No.220505078205656, No.220503880205011), Young Backbone Teachers Program of Henan University of Science and Technology (No.13450009), Postgraduate Education Reform and Quality Improvement Project of Henan Province (No.YJS2025AL49, No.YJS2025SZ18)and the National Natural Science Foundation of China (No.32202096).
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Any alternative text (alt text) provided alongside figures in this article has been generated by Frontiers with the support of artificial intelligence and reasonable efforts have been made to ensure accuracy, including review by the authors wherever possible. If you identify any issues, please contact us.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Abadi, M., Agarwal, A., Barham, P., Brevdo, E., Chen, Z., Citro, C., et al. (2016). TensorFlow: Large-scale machine learning on heterogeneous distributed systems. CoRR., abs/1603.04467. Available at: http://arxiv.org/abs/1603.04467.
Archana, R. and Jeevaraj, P. S. E. (2024). Deep learning models for digital image processing: a review. Artif. Intell. Rev. 57, 11. doi: 10.1007/s10462-023-10631-z
Bevers, N., Sikora, E. J., and Hardy, N. B. (2022). Pictures of diseased soybean leaves by category captured in field and with controlled backgrounds: Auburn soybean disease image dataset (ASDID). Dryad, Dataset. doi: 10.5061/dryad.41ns1rnj3
Buda, M., Maki, A., and Mazurowski, M. A. (2018). A systematic study of the class imbalance problem in convolutional neural networks. Neural Networks 106, 249–259. doi: 10.1016/j.neunet.2018.07.011
Chen, M., Chang, Z., and Jin, C. (2025). Classification and recognition of soybean quality based on hyperspectral imaging and random forest methods. Sensors 25, 1539. doi: 10.3390/s25051539
Chen, X., He, W., and Ye, Z. (2024). Soybean seed pest damage detection method based on spatial frequency domain imaging combined with RL-SVM. Plant Methods 20, 130. doi: 10.1186/S13007-024-01257-5
Ding, Y., Ma, H., Wang, K., Azam, S. R., Wang, Y., Zhou, J., et al. (2021). Ultrasound frequency effect on soybean protein: Acoustic field simulation, extraction rate and structure. Lwt-Food Sci. Technol. 145, n/a. doi: 10.1016/j.lwt.2021.111320
El Sakka, M., Ivanovici, M., and Chaari, L. (2025). A review of CNN applications in smart agriculture using multimodal data. Sensors 25, 472. doi: 10.3390/s25020472
Gao, J., Ni, J., and Yang, H. (2021). Pistachio visual detection based on data balance and deep learning. Trans. Chin. Soc Agric. 52, 367–372. doi: 10.6041/j.issn.1000-1298.2021.07.040
Goshika, S., Meksem, K., and Ahmed, K. R. (2023). Deep learning model for classifying and evaluating soybean leaf disease damage. Int. J. Mol. Sci. 25, 106. doi: 10.3390/ijms25010106
Guo, J., Zhang, K., and Adade, S. Y. S. S. (2025). Tea grading, blending, and matching based on computer vision and deep learning. J. Sci. Food Agric. 105, 3239–3251. doi: 10.1002/jsfa.14088
Han, J. H., Wu, Q. F., Xu, B., Zhou, S. L., and Ding, F. (2016). Quality characteristics of soybean germ oil obtained by innovative subcritical butane experimental equipment. Qual. Assur. Saf. Crops Foods 8, 369–377. doi: 10.3920/QAS2015.0625
Huang, L., Ding, X., Li, Y., and Ma, H. (2019). The aggregation, structures and emulsifying properties of soybean protein isolate induced by ultrasound and acid. Food Chem. 279, 114–119. doi: 10.1016/j.foodchem.2018.11.147
Huang, G., Liu, Z., and van der Maaten, L. (2017). “Densely connected convolutional networks,” in Proceedings of the IEEE conference on computer vision and pattern recognition. (CVPR), Honolulu, HI, USA, 2261–2269. doi: 10.1109/CVPR.2017.243
Jiehong, C., Jun, S., and Kunshan, Y. (2023). Multi-task convolutional neural network for simultaneous monitoring of lipid and protein oxidative damage in frozen-thawed pork using hyperspectral imaging[J]. Meat Science, 201, 109196–109196.
Kang, J., Shin, T., and Ko, J. (2025). Optimized deep learning model for soybean leaf classification in complex field environments. Korean J. Of Crop Sci. 70, 68–78. doi: 10.7740/kjcs.2025.70.2.068
Karlekar, A. and Seal, A. (2020). SoyNet: Soybean leaf diseases classification. Comput. Electron. Agric. 172, 105342. doi: 10.1016/j.compag.2020.105342
Ma, J., Zhao, Y., and Fan, W. (2024). An improved YOLOv8 model for lotus seedpod instance segmentation in the lotus pond environment. Agronomy 14, 1325–1325. doi: 10.3390/agronomy14061325
Mahmood ur Rehman, M., Liu, J., and Nijabat, A. (2024). Leveraging convolutional neural networks for disease detection in vegetables: A comprehensive review. Agronomy 14, 2231. doi: 10.3390/agronomy14102231
Miao, Y., Xiaodan, M., and Haiou, G. (2023). Recognition method of soybean leaf diseases using residual neural network based on transfer learning. Ecol. Inf. 76, 102096. doi: 10.1016/j.ecoinf.2023.102096
Pei, H. (2022). Weed detection in maize fields by UAV images based on crop row preprocessing and improved YOLOv4. Agriculture 12, 975–975. doi: 10.3390/agriculture12070975
Pradhan, A., Shrestha, D. S., and McAloon, A. (2010). Energy life-cycle assessment of soybean biodiesel. In Biofuel Lifecycle Issues and Research 121. Nova Science Publishers, Inc.
Qiu, D., Guo, T., Yu, S., Liu, W., Li, L., Sun, Z., et al. (2024). Classification of apple color and deformity using machine vision combined with CNN. Agriculture 14, 978. doi: 10.3390/agriculture14070978
Rachmad, A., Ansori, N., Rifka, S., Rochman, E. M. S., and Setiawan, W. (2023). Classification of Diseases on Corn Stalks using a Random Forest based on a Combination of the Feature Extraction (Local Binary Pattern and Color Histogram). Technium: Romanian J. Appl. Sci. Technol. 16, 303–309. doi: 10.47577/technium.v16i.10002
Savary, S., Willocquet, L., Pethybridge, S. J., Esker, P., McRoberts, N., and Nelson, A. (2019). The global burden of pathogens and pests on major food crops. Nat. Ecol. Evol. 3, 430–439. doi: 10.1038/s41559-018-0793-y
Sharma, V., Tripathi, A. K., and Mittal, H. (2025). SoyaTrans: A novel transformer model for fine-grained visual classification of soybean leaf disease diagnosis. Expert Syst. Appl. 260, 125385–125385. doi: 10.1016/j.eswa.2024.125385
Shengyi, Z., Yun, P., and Jizhan, L. (2021). Tomato Leaf Disease Diagnosis Based on Improved Convolution Neural Network by Attention Module[J]. Agriculture, 11 (7), 651–651.
Sun, J., He, X., Ge, X., Wu, X., Shen, J., and Song, Y. (2018). Detection of key organs in tomato based on deep migration learning in a complex background. Agriculture 8, 196. doi: 10.3390/agriculture8120196
Sun, J., Jiang, S., Mao, H., Wu, X., and Li, Q. (2016). Classification of black beans using visible and near infrared hyperspectral imaging. Int. J. Food Properties 19, 1687–1695. doi: 10.1080/10942912.2015.1055760
Sun, W. X., Zhang, R. J., Fan, J., He, Y., and Mao, X. H. (2018). Comprehensive transformative profiling of nutritional and functional constituents during germination of soybean sprouts. J. Food Measurement Characterization 12, 1295–1302. doi: 10.1007/s11694-018-9743-2
Wang, L., Dong, Y., Wang, L., Cui, M., Zhang, Y., Jiang, L., et al. (2023). Elucidating the effect of the Hofmeister effect on formation and rheological properties of soy protein\κ-carrageenan hydrogels. Food Hydrocolloids 143, 108905. doi: 10.1016/j.foodhyd.2023.108905
Wang, S., Sun, J., Fu, L., Xu, M., Tang, N., Cao, Y., et al. (2022). Identification of red jujube varieties based on hyperspectral imaging technology combined with CARS-IRIV and SSA-SVM. J. Food Process Eng. 45 (10), e14137. doi: 10.1111/jfpe.14137
Weidong, Z., Jun, S., and Simin, W. (2022). Identifying Field Crop Diseases Using Transformer-Embedded Convolutional Neural Network[J]. Agriculture, 12 (8), 1083–1083.
Woo, S., Park, J., and Lee, J. Y. (2018). “CBAM: Convolutional block attention module,” In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds) Computer Vision – ECCV 2018. ECCV 2018. Lecture Notes in Computer Science(), 11211. Springer, Cham. doi: 10.1007/978-3-030-01234-2_1
Wu, Q., Ma, X., and Liu, H. (2023). A classification method for soybean leaf diseases based on an improved ConvNeXt model. Sci. Rep. 13, 19141. doi: 10.1038/s41598-023-46492-3
Xu, J., Liu, H., and Shen, Y. (2024). Individual nursery trees classification and segmentation using a point cloud-based neural network with dense connection pattern. Scientia Hortic. 328, 112945. doi: 10.1016/j.scienta.2024.112945
Zhang, F., Bao, R., and Yan, B. (2024). LSANNet: A lightweight convolutional neural network for maize leaf disease identification[J]. Biosystems Engineering, 248, 97–107.
Zhang, J. and Dai, L. (2025). Application of Hyperspectral Imaging and Deep Convolutional Neural Network for Freezing Damage Identification on Embryo and Endosperm Side of Single Corn Seed[J]. Foods 14 (4), 659–659.
Zhang, Z., Yang, M., and Pan, Q. (2025). Identification of tea plant cultivars based on canopy images using deep learning methods. Scientia Hortic. 339, 113908–113908. doi: 10.1016/j.scienta.2024.113908
Zhiming, G. and Chanjun, Y. Z. (2024). Nondestructive determination of edible quality and watercore degree of apples by portable Vis/NIR transmittance system combined with CARS-CNN[J]. Journal of Food Measurement and Characterization. 18 (6), 4058–4073.
Keywords: soybean leaf diseases, disease diagnosis, multiscale feature extraction fusion, dense connectivity, deep convolutional neural networks
Citation: Zhang Y, Bao R, Guan M, Wang Z, Wang L, Cui X, Niu X, Wang Y, Ali S and Wang Y (2025) A lightweight deep convolutional neural network development for soybean leaf disease recognition. Front. Plant Sci. 16:1655564. doi: 10.3389/fpls.2025.1655564
Received: 28 June 2025; Accepted: 10 September 2025;
Published: 30 September 2025.
Edited by:
Xinhua Ding, Shandong Agricultural University, ChinaCopyright © 2025 Zhang, Bao, Guan, Wang, Wang, Cui, Niu, Wang, Ali and Wang. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Yakun Zhang, emhhbmd5a0BoYXVzdC5lZHUuY24=; Yafei Wang, d2FuZ3lhZmVpOTE4QHVqcy5lZHUuY24=