 Mohsen Shahhosseini
Mohsen Shahhosseini Guiping Hu
Guiping Hu Saeed Khaki
Saeed Khaki Sotirios V. Archontoulis
Sotirios V. Archontoulis- 1Department of Industrial and Manufacturing Systems Engineering, Iowa State University, Ames, IA, United States
- 2Department of Agronomy, Iowa State University, Ames, IA, United States
We investigate the predictive performance of two novel CNN-DNN machine learning ensemble models in predicting county-level corn yields across the US Corn Belt (12 states). The developed data set is a combination of management, environment, and historical corn yields from 1980 to 2019. Two scenarios for ensemble creation are considered: homogenous and heterogenous ensembles. In homogenous ensembles, the base CNN-DNN models are all the same, but they are generated with a bagging procedure to ensure they exhibit a certain level of diversity. Heterogenous ensembles are created from different base CNN-DNN models which share the same architecture but have different hyperparameters. Three types of ensemble creation methods were used to create several ensembles for either of the scenarios: Basic Ensemble Method (BEM), Generalized Ensemble Method (GEM), and stacked generalized ensembles. Results indicated that both designed ensemble types (heterogenous and homogenous) outperform the ensembles created from five individual ML models (linear regression, LASSO, random forest, XGBoost, and LightGBM). Furthermore, by introducing improvements over the heterogenous ensembles, the homogenous ensembles provide the most accurate yield predictions across US Corn Belt states. This model could make 2019 yield predictions with a root mean square error of 866 kg/ha, equivalent to 8.5% relative root mean square and could successfully explain about 77% of the spatio-temporal variation in the corn grain yields. The significant predictive power of this model can be leveraged for designing a reliable tool for corn yield prediction which will in turn assist agronomic decision makers.
Introduction
Accurate crop yield prediction is essential for agriculture production, as it can provide insightful information to farmers, agronomists, and other decision makers. However, this is not an easy task, as there is a myriad of variables that affect the crop yields, from genotypes, environment, and management decisions to technological advancements. The tools that are used to predict crop yields are mainly divided into simulation crop modeling and machine learning (ML).
Although these models are usually utilized separately, there have been some recent studies to combine them toward improving prediction. The outputs of crop models have served as inputs to multiple linear regression models in an attempt to make better crop yield predictions (Mavromatis, 2016; Busetto et al., 2017; Pagani et al., 2017). Some other studies have made additional advancement and created hybrid crop model-ML methodologies by using crop model outputs as inputs to a ML model (Everingham et al., 2016; Feng et al., 2019). In a recent study, Shahhosseini et al. (2021) designed a hybrid crop model-ML ensemble framework, in which a crop modeling framework (APSIM) was used to provide additional inputs to the yield prediction task (For more information about APSIM refer to https://www.apsim.info/). The results demonstrated that coupling APSIM and ML could improve ML performance up to 29% compared to ML alone.
On the other hand, the use of more complex machine learning models with the intention of better using numerous ecological variables to predict yields has been recently becoming more prevalent (Basso and Liu, 2019). Although there is always a tradeoff between the model complexity and its interpretability, the recent complex models could better capture all kinds of associations such as linear and nonlinear relationships between the variables associated with the crop yields, resulting in more accurate predictions and subsequently better helping decision makers (Chlingaryan et al., 2018). These models span from models as simple as linear regression, k-nearest neighbor, and regression trees (González Sánchez et al., 2014; Mupangwa et al., 2020), to more complex methods such as support vector machines (Stas et al., 2016), homogenous ensemble models (Vincenzi et al., 2011; Fukuda et al., 2013; Heremans et al., 2015; Jeong et al., 2016; Shahhosseini et al., 2019), heterogenous ensemble models (Cai et al., 2017; Shahhosseini et al., 2020, 2021), and deep neural networks (Liu et al., 2001; Drummond et al., 2003; Jiang et al., 2004, 2020; Pantazi et al., 2016; You et al., 2017; Crane-Droesch, 2018; Wang et al., 2018; Khaki and Wang, 2019; Kim et al., 2019; Yang et al., 2019; Khaki et al., 2020a, b). Homogeneous ensemble models are the models created using same-type base learners, while the base learners in the heterogenous ensemble models are different.
Although deep neural networks demonstrate better predictive performance compared to single layer networks, they are computationally more expensive, more likely to overfit, and may suffer from vanishing gradient problem. However, some studies have proposed solutions to address these problems and possibly boost deep neural network’s performance (Bengio et al., 1994; Srivastava et al., 2014; Ioffe and Szegedy, 2015; Szegedy et al., 2015; Goodfellow et al., 2016; He et al., 2016).
Convolutional neural networks (CNNs) have mainly been developed to work with two-dimensional image data. However, they are also widely used with one-dimensional and three-dimensional data. Essentially, CNNs apply a filter to the input data which results in summarizing different features of the input data into a feature map. In other words, CNN paired with pooling operation can extract high-level features from the input data that includes the necessary information and has lower dimension. This means CNNs are easier to train and have fewer parameters compared to fully connected networks (Goodfellow et al., 2016; Zhu et al., 2018; Feng et al., 2020).
Since CNNs are able to preserve the spatial and temporal structure of the data, they have recently been used in ecological problems, such as yield prediction. Khaki et al. (2020b) proposed a hybrid CNN-RNN framework for crop yield prediction. Their framework consists of two one-dimensional CNNs for capturing linear and nonlinear effects of weather and soil data followed by a fully connected network to combine high-level weather and soil features, and a recursive neural network (RNN) that could capture time dependencies in the input data. The results showed that the model could achieve decent relative root mean square error of 9 and 8% when predicting corn and soybean yields, respectively. You et al. (2017) developed CNN and LSTM models for soybean yield prediction using remote sensor images data. The developed models could predict county-level soybean yields in the U.S. better than the competing approaches including ridge regression, decision trees, and deep neural network (DNN). Moreover, Yang et al. (2019) used low-altitude remotely sensed imagery to develop a CNN model. The experimental results revealed that the designed CNN outperformed the traditional vegetation index-based regression model for rice grain yield estimation, significantly.
Another set of developed models to capture complex relationships in the input raw data are ensemble models. It has been proved that combining well-diverse base machine learning estimators of any types, can result in a better-performing model which is called an ensemble model (Zhang and Ma, 2012). Due to their predictive ability, ensemble models have also been used recently by ecologists. Several heterogenous ensemble models including optimized weighted ensemble, average ensemble, and stacked generalized ensembles were created using five base learners, namely LASSO regression, linear regression, random forest, XGBoost, and LightGBM. The computational results showed that the ensemble models outperformed the base models in predicting corn yields. Cai et al. (2017) combined several ML estimators to form a stacked generalized ensemble. The back-testing numerical results demonstrate that their model’s performance is comparable to the USDA forecasts.
Although these models have provided significant advances toward making better yield predictions, there is still a need to increase the predictive capacity of the existing models. This can be done by improving the data collections, and by the means of developing more advanced and forward-thinking models. The ensemble models are excellent tools that have the potential to turn very good models to outstanding predictor models.
Motivated by the high predictive performance of CNNs and ensemble models in ecology (Cai et al., 2017; You et al., 2017; Yang et al., 2019; Khaki et al., 2020b; Shahhosseini et al., 2020, 2021), we propose a set of ensemble models created from multiple hybrid CNN-DNN base learners for predicting county-level corn yields across US Corn Belt states. Building upon successful studies in the literature (Khaki et al., 2020b; Shahhosseini et al., 2020), we designed a base architecture consisting of two one-dimensional CNNs and one fully connected network (FC) as the first layer networks, and another fully connected network that combined the outputs of the first-layer networks and made final predictions, as the second-layer network. Afterwards, two scenarios are considered for base learner generation: heterogenous and homogenous ensemble creation. In the heterogenous scenario, the base learners are neural networks with the same described architecture, but with different hyperparameters. On the contrary, the homogenous ensembles are created with bagging the same architecture and forming diverse base learners. In each scenario, the generated base learners are combined by several methods including simple averaging, optimized weighted averaging, and stacked generalization.
Materials and Methods
The designed ensemble framework uses a combination of historical yield and management data obtained from USDA NASS, historical weather and soil data as the data inputs. The details of the created data set and the developed model will be explained below.
Data Preparation
Data Sources
The main variables that affect corn yields are environment, genotype, and management. Although genotype information are not publicly available, other pieces of information including environment (soil and weather) and some of the management decisions data could be accessed publicly. To this end, we created a data set from environment and management variables that could be used to predict corn yields. This data includes county-level weather, soil, and management data considering 12 US Corn Belt states (Illinois, Indiana, Iowa, Kansas, Michigan, Minnesota, Missouri, Nebraska, North Dakota, Ohio, South Dakota, and Wisconsin). It is also noteworthy that since only some of the locations across US Corn Belt states are irrigated, to keep the consistency across the entire developed data set, we assumed that all farms are rainfed and didn’t consider irrigation as a feature. The variables weekly planting progress per state and corn yields per county were downloaded from USDA National Agricultural Statistics Service (NASS, 2019). The weather was obtained from a reanalysis weather database based off of NASA Power1 and Iowa Environmental Mesonet.2 Finally, the soil data was created from SSURGO, a soil database based off of soil survey information collected by the National Cooperative Soil Survey (Soil Survey Staff [SSS], 2019). These variables are described below. Across 12 states, on average the data from 950 counties in total were used per year.
- Planting progress (planting date): 52 features explaining the weekly cumulative percentage of corn planted within each state. Each of these state-level weekly features represents the cumulative percentage of corn planted until that particular week (NASS, 2019).
- Weather: Five weather features accumulated weekly (52 × 5 = 260 features), obtained from NASA Power and Iowa Environmental Mesonet.
◦ Daily minimum air temperature in degrees Celsius.
◦ Daily maximum air temperature in degrees Celsius.
◦ Daily total precipitation in millimeters per day.
◦ Shortwave radiation in watts per square meter.
◦ Growing degree days.
- Soil: The soil features wet soil bulk density, dry bulk density, clay percentage, plant available water content, lower limit of plant available water content, hydraulic conductivity, organic matter percentage, pH, sand percentage, and saturated volumetric water content. All variables determined at 10 soil profile depths (cm): 0–5, 5–10, 10–15, 15–30, 30–45, 45–60, 60–80, 80–100, 100–120, and 120–150 (Soil Survey Staff [SSS], 2019).
- Corn Yield: Yearly corn yield in bushel per acre, collected from USDA-NASS (2019).
Data Pre-processing
The following pre-processing tasks were performed on the created data set to make it prepared for training the designed ensemble models.
- Imputing missing planting progress data for the state North Dakota before the year 2000 by considering average progress values of two closest states (South Dakota and Minnesota).
- Removing out-of-season planting progress data before planting and after harvesting.
- Removing out-of-season weather features before planting and after harvesting.
- Aggregating weather features to construct quarterly and annually weather features. The features solar radiation and precipitation were aggregated by summation, while other weather features (minimum and maximum temperature) were aggregated by a row-wise average.
- The observations with the yield less than 10 bu/acre were considered as outliers and dropped from the data set.
- Investigating the historical corn yields over the time reveals an increasing trend in the yield values. This could be explained as the effect of technological advances, like genetic gains, management progress, advanced equipment, and other technological advances. Hence, a new input feature was constructed using the observed trends that enabled the models to account for the increasing yield trend.
◦ yield_trend: this feature explained the observed trend in corn yields. A linear regression model using the training data was built for each location as the trends for each site tend to be different. The year (YEAR) and yield (Y) features served as the predictor and response variables of this linear regression model, respectively. Then the predicted value for each data point () is added as a new input variable that explains the increasing annual trend in the target variable. The corresponding value for the observations in the test data set was estimated by plugging in their corresponding year in the trained linear regression models (). The following equation shows the trend value () calculated for each location (i), that is added to the data set as a new feature.
- All independent variables were scaled to be ranged between 0 and 1.
Base Models Generation
We propose the following CNN-DNN architecture as the foundation for generating multiple base learners that serve as the inputs to the ensemble creation models. The architecture consists of two layers of deep neural networks.
First Layer
Due to the ability of CNNs in capturing the spatial and temporal dependencies that exist in the soil and weather data, respectively, we decided to build two separate set of one-dimensional CNNs for each of the weather (W-CNN) and soil (S-CNN) groups of features. Such networks have been used before in different studies and have been proved to be effective in capturing linear and nonlinear effects in the soil and weather (Ince et al., 2016; Borovykh et al., 2017; Kiranyaz et al., 2019). In addition, a fully connected network (FC1) was built that took planting progress, and other constructed features as inputs and the output is concatenated with the outputs of the CNN components to serve as inputs of the second layer of the networks.
Specifically, the first layer includes three network types:
1 Weather CNN models (W-CNN):
CNN is able to capture the temporal effect of weather data measured over time. In the case of the developed data set, we will use a set of one-dimensional CNNs inside the W-CNN component.
2 Soil CNN models (S-CNN):
CNN can also capture the spatial effect of soil data which is measured over time and on different depths. Considering the data set, we will use a set of one-dimensional CNNs to build this component of the network.
3 Other variables FC model (FC1):
This fully connected network can capture the linear and nonlinear effect of other input features.
Second Layer (FC2)
In the second layer we used a fully connected network (FC2) that aggregates all extracted features of the first layer networks (W-CNN, S-CNN, and FC1), and makes the final yield prediction.
The architecture of the proposed base network is depicted in Figure 1. As it is shown in the figure, the W-CNN and S-CNN components of the network each are comprised of a set of CNNs that are in charge of one data input type and their outputs are aggregated with a fully connected network. For the case of W-CNN component, there are five CNNs for each weather data type (precipitation, maximum temperature, minimum temperature, solar radiation, and growing degree days). Similarly, 10 internal CNNs are designed inside S-CNN component for each of the 10 soil data types. The reason we decided to design one CNN for each data type is the differences in the natures of different data types and our experiments showed that separate CNNs for each data type could extract more useful information and will result in better final predictions. The two inner fully connected networks (FC_W and FC_S) both have one hidden layer with 60 and 40 neurons, respectively.
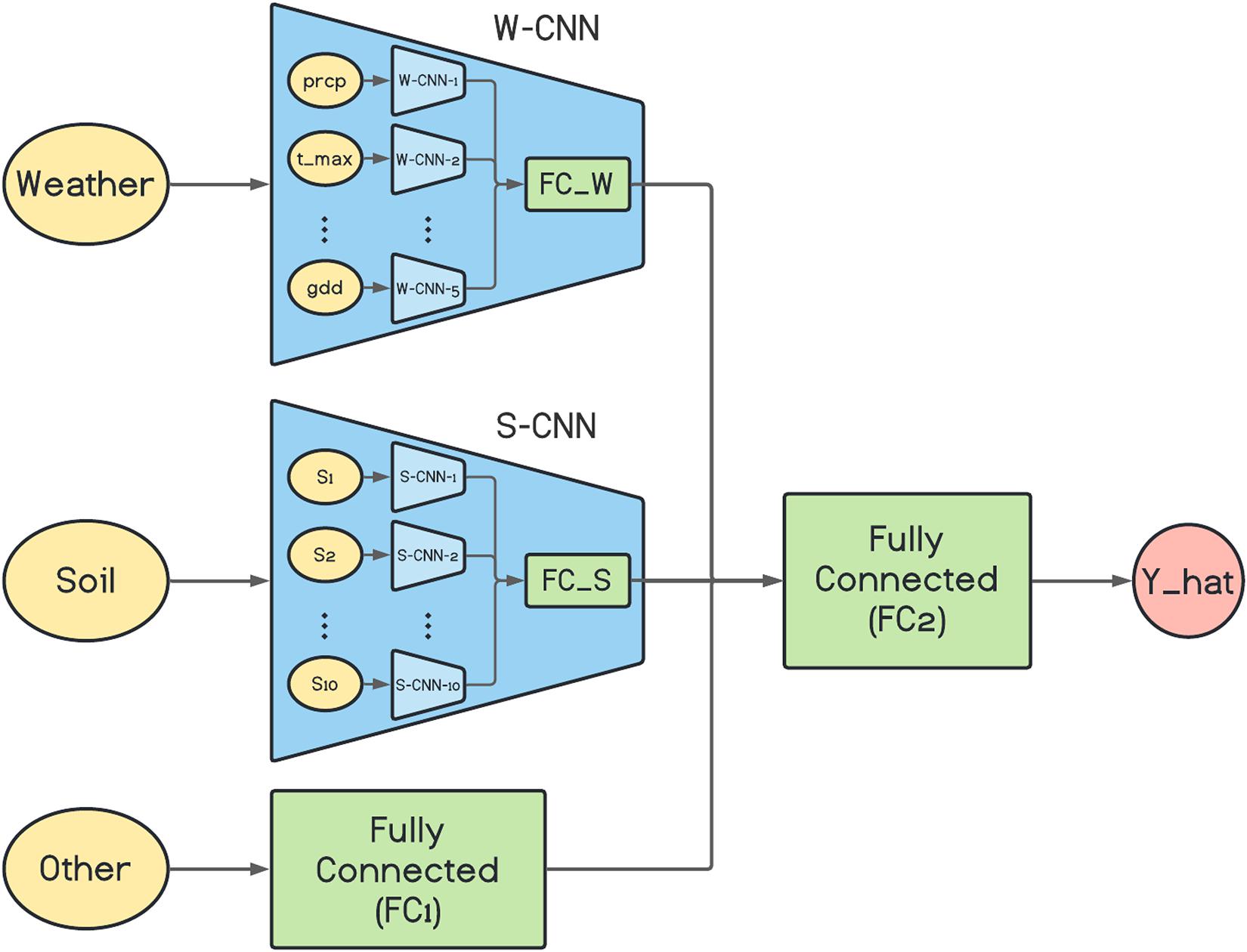
Figure 1. The architecture of the proposed base network. prcp, t_max, and gdd represent precipitation, maximum temperature, and growing degree days, respectively. S1, S2, …, and S10 are 10 soil variables which each are measured at 10 depth levels. Y_hat represents the final corn yield prediction made by the model.
We used VGG-like architecture for the CNN models (Simonyan and Zisserman, 2014). The details about each of the designed CNN networks are presented in Table 1. We performed downsampling in the CNN models by average pooling with a stride of size 2. The feed-forward fully connected network in the first layer (FC1) has three hidden layers with 64, 32, and 16 neurons. The final fully connected network of the second layer (FC2) is grown with two hidden layers with 128 and 64 neurons. In addition, two dropout layers with dropout ratio of 0.5 are located at the two last layers of the FC2 to prevent the model from overfitting. We used Adam optimizer with the learning rate of 0.0001 for the entire model training stage and trained the model for 1,000 iterations considering batches of size 16. Rectified linear unit (ReLU) was used as the activation function of all networks throughout the architecture except the output layer that had a linear activation function.
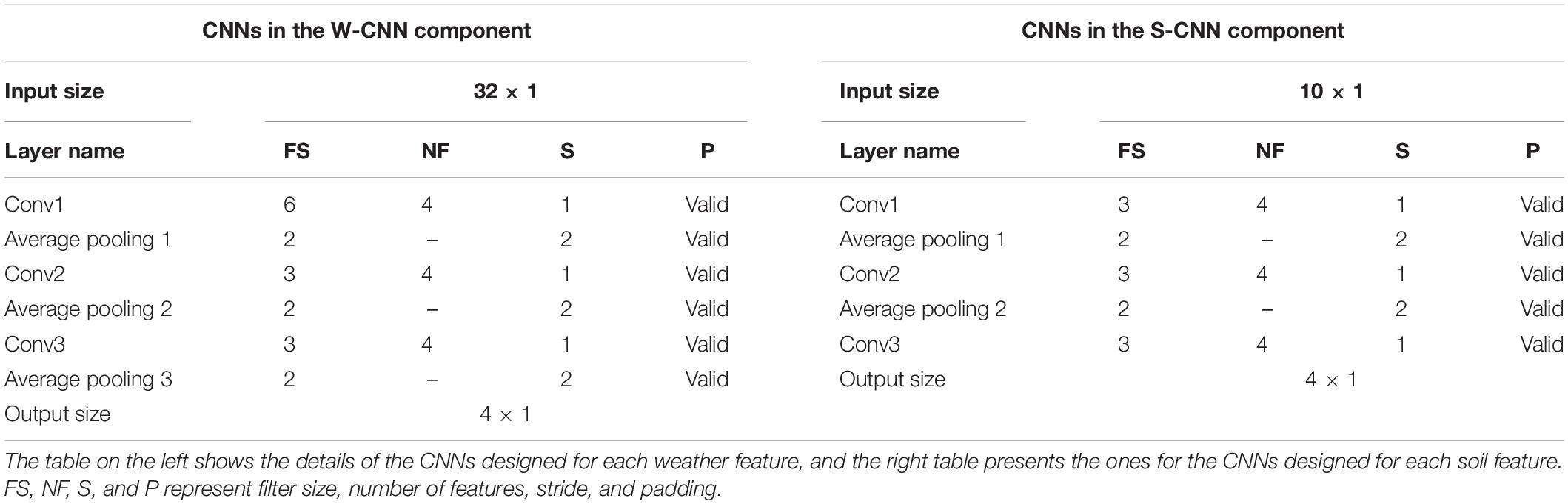
Table 1. Detailed structure of the CNN networks of CNN components designed as the foundation for ensemble neural networks.
To ensure that the ensemble created from a set of base learners performs better than them, the base learners should have a certain level of diversity and prediction accuracy (Brown, 2017). Hence, two scenarios for generating diverse base models are considered which are systematically different: homogenous and heterogenous ensemble base model generation.
Homogenous Ensembles
The homogenous ensembles are the models whose base learners are all the same type. Random forest and gradient boosting are examples of homogenous ensemble models. Their base learners are decision trees with the same hyperparameter values. Bootstrap aggregating (Bagging) is an ensemble framework which was proposed by Breiman (1996). Bagging generates multiple training data sets from the original data set by sampling with replacement (bootstrapping). Then, one base model is trained on each of the generated training data sets and the final prediction is the average (for regression problems) or voting (for classification problems) of the predictions made by each of those base models. Basically, by sampling with replacement and generating multiple data sets, and subsequently multiple base models, bagging ensures the base models have a certain level of diversity. In other words, bagging tries to reduce the prediction variance by averaging the predictions of multiple diverse base models.
Here, inspired by the way bagging introduces diversity in the base model generation, we design a bagging schema which generates multiple base CNN-DNN models using the same foundation model (Figure 1). This is shown in Figure 2. Then several ensemble creation methods make use of these bagged networks as the base models to create a better-performing ensemble network. We believe one drawback of bagging is assigning equal weights to the bagged models. To address that, we will use different ensemble creation methods in order to optimally combine the bagged models. We will discuss ensemble creation in the next chapter.
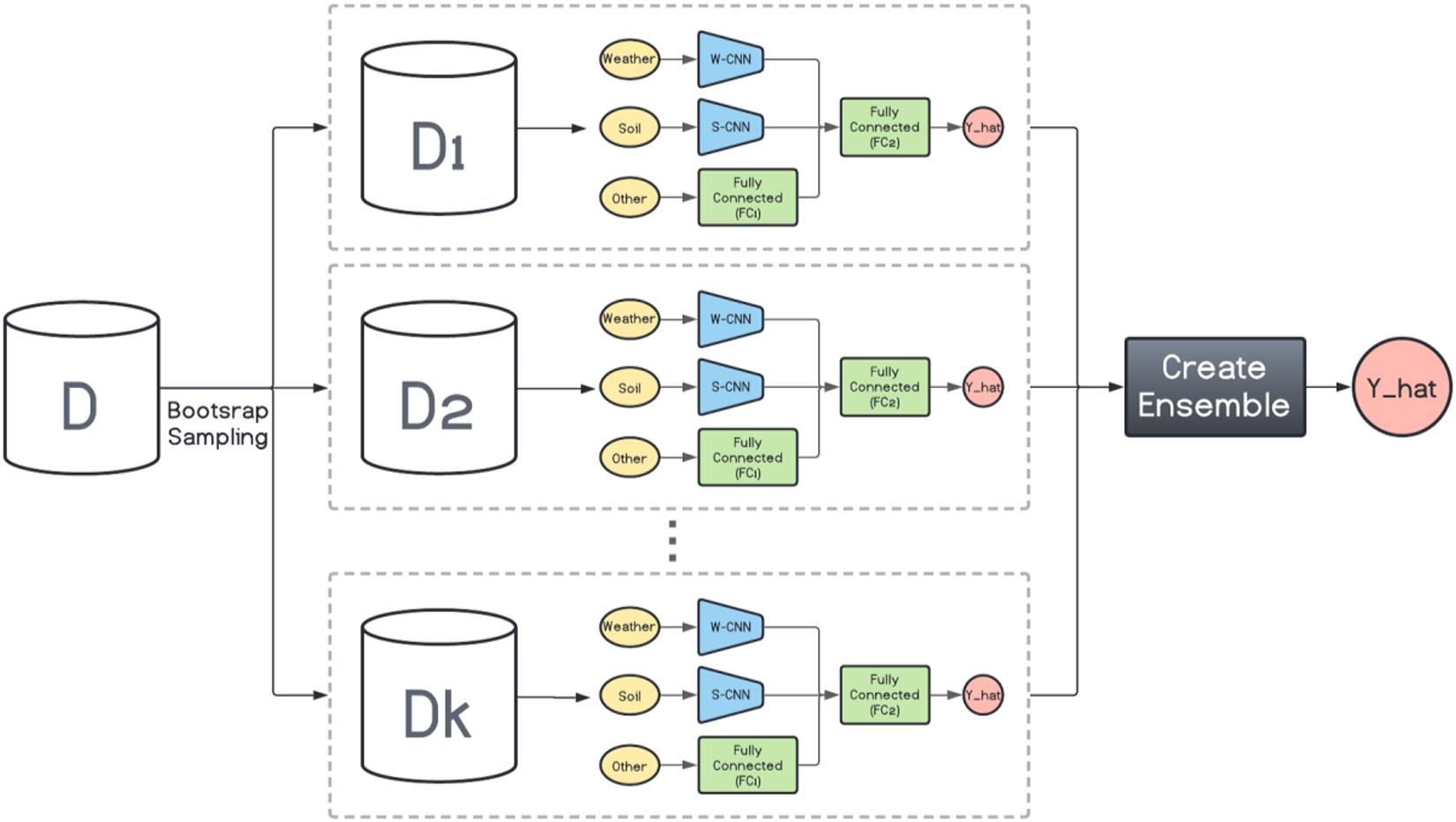
Figure 2. Homogenous ensemble creation with bagging architecture. k data sets (D1, D2, …, Dk) were generated with bootstrap sampling from the original data set (D) and the same base network is trained on each of them. The ensemble creation combines the predictions made by the base networks.
Heterogenous Ensembles
On the other hand, the base models in the heterogenous ensembles are not the same. They can be any machine learning model from the simplest to the most complex models. However, as mentioned before, the ensemble is not expected to perform favorably if the base models do not exhibit a certain level of diversity. To that end, we train k variations of the base CNN-DNN model presented earlier. The foundation architecture of these k models are the same, but their CNN hyperparameters are different. In other words, we preserve the same architecture for all models and change the number of filters inside each CNN network to create various CNN-DNN models. These models will serve as the inputs to the ensemble creation methods explained in the next chapter (see Figure 3).
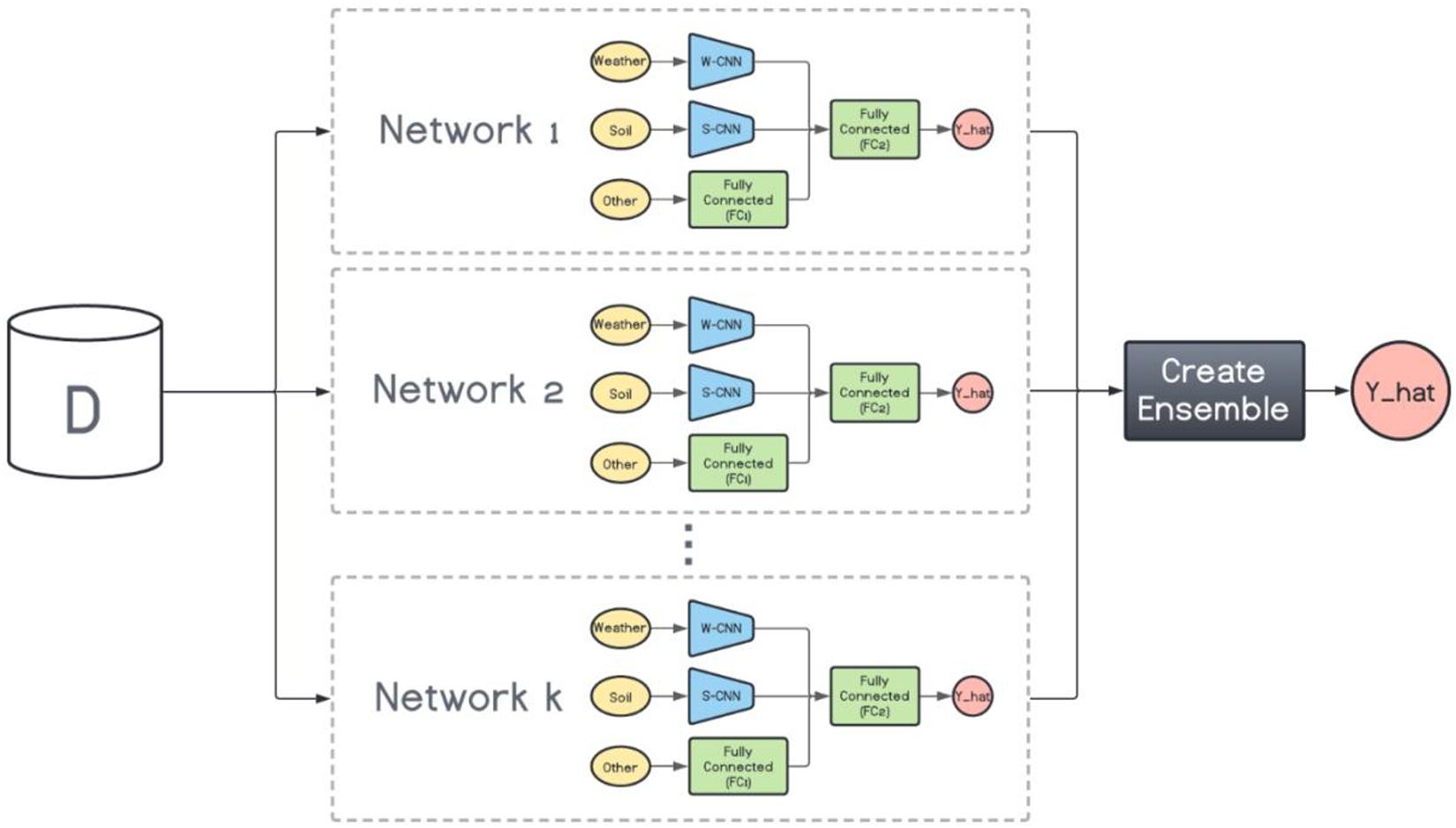
Figure 3. Heterogenous ensemble creation. k networks with the same architecture but with different hyperparameters are created using the original data set (D).
Ensemble Creation
After generating base learners in either of the heterogenous and homogenous methods, they should be combined using a systematic procedure. We have used three different types of ensemble creation methods which are Basic Ensemble Method (BEM), Generalized Ensemble Method (GEM), and stacked generalized ensemble method.
Basic Ensemble Method (BEM)
Perrone and Cooper (1992) proposed BEM as the most natural way of combining base learners. BEM creates a regression ensemble by simple averaging the base estimators. This study claims that BEM can reduce mean squared error of predictions, given that the base learners are diverse.
Generalized Ensemble Method (GEM)
GEM is the general case of a BEM ensemble creation method and tries to create a regression ensemble as the linear combination of the base estimators. Cross-validation is used to generate out-of-bag (OOB) predictions and optimize the ensemble weights and the model was claimed to avoid overfitting the data (Perrone and Cooper, 1992).
The nonlinear convex optimization problem is as follows.
wj ≥ 0,∀j = 1…,k. In which wj is the weight of base model j (j = 1…,k), n is the total number of observations, yi is the true value of observation i, and is the prediction of observation i by base model j.
Stacked Generalized Ensemble Method
Stacked generalization is referred to combining several base estimators by performing at least one more level of machine learning task. Usually, cross-validation is used to generate OOB predictions form the training samples and learn the higher-level machine learning models (Wolpert, 1992). The second level learner can be any choice of ML models. In this study we have selected linear regression, LASSO, random forest and LightGBM as the second level learners.
Results
The historical county-level data of the US Corn Belt states (Illinois, Indiana, Iowa, Kansas, Michigan, Minnesota, Missouri, Nebraska, North Dakota, Ohio, South Dakota, and Wisconsin) spanning across years 1980–2019 were used to train all considered models. The data from the years 2017, 2018, and 2019, in turn, were reserved as the test data and the data from the years before each of them formed the training data.
As mentioned in the section “Ensemble Creation,” the ensemble creation methods require OOB predictions from all the input models that represent the test data to optimally combine the base models. The current procedure to create these OOB predictions is using a cross-validation method. However, due to time-dependency in the training data and the fact that in the homogenous ensemble models the training data is resampled k times, it is not possible to find a consistent vector of OOB predictions across all models and use it to combine the base models. Therefore, 20% of the training data was considered as the validation data and was not used in model training. It is noteworthy that the training data is split to 20–80% with a stratified split procedure to ensure the validation data has a similar distribution with the training data. To achieve the stratified splits, we binned the observations in the training data into five linearly spaced bins based on their corresponding yield values.
The CNN structure of the base models trained for creating homogenous ensemble models are same as the one shown in Table 1. We have resampled the training data 10 times (with replacement) and trained the same CNN-DNN model on each of the 10 newly created training data. The OOB predictions are the predictions made by each of the 10 mentioned models on the validation data.
On the other hand, the base models trained for creating heterogenous ensemble models are not the same and they differ in their CNN hyperparameters (number of filters). We trained five different CNN-DNN base models on the same training data and formed the OOB predictions by each of those five models predicting the observations in the validation data. The details of the CNN components in these five models are shown in the Table 2.
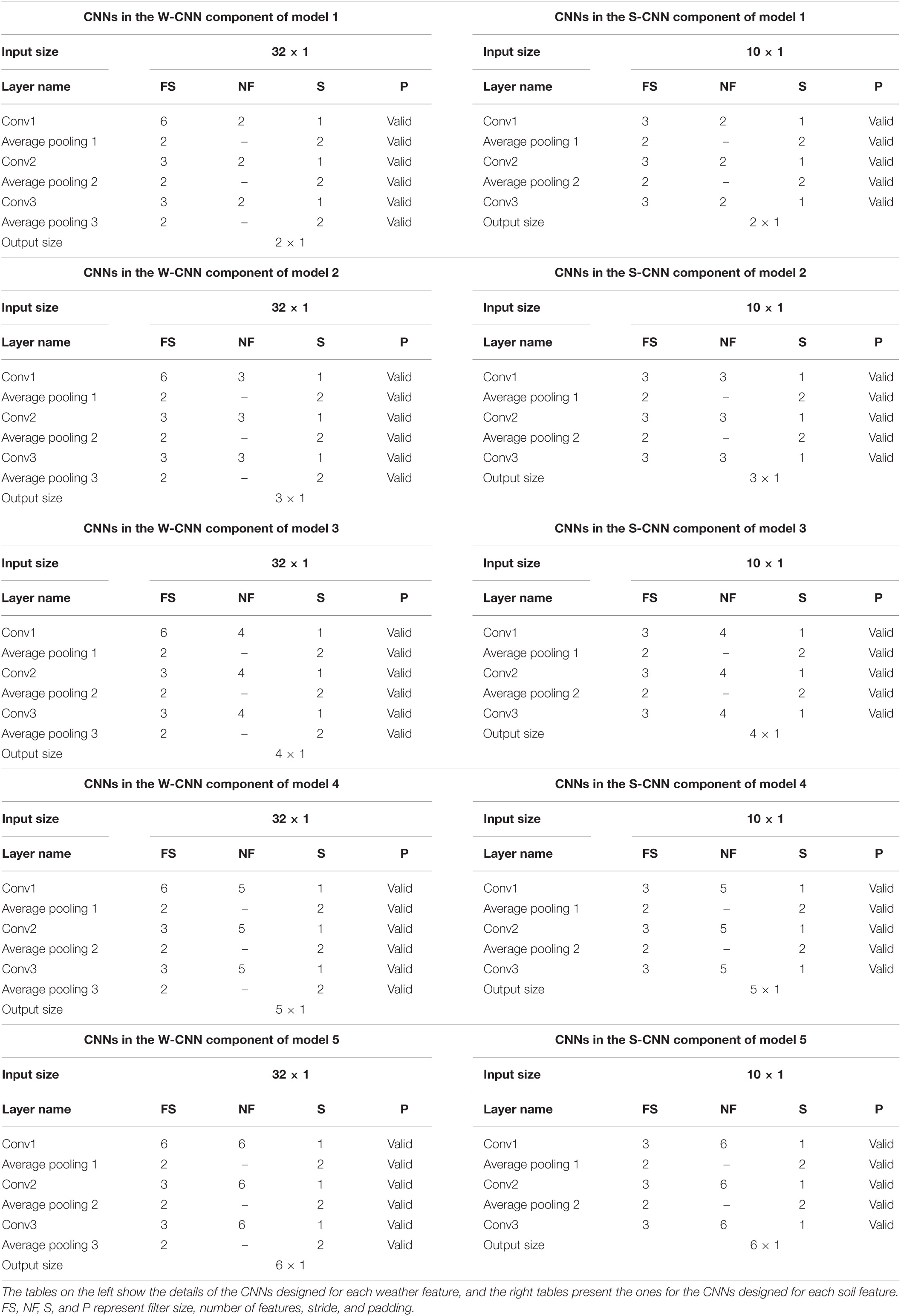
Table 2. Detailed structure of the CNN networks of CNN components designed for heterogenous ensemble models.
To evaluate the performance of the trained heterogenous and homogenous CNN-DNN ensembles, the ensembles created from five individual machine learning models (linear regression, LASSO, XGBoost, random forest, and LightGBM) were considered as benchmark and were trained on the same data sets developed for training the CNN-DNN ensemble models. The benchmark models were run on a computer equipped with a 2.6 GHz Intel E5-2640 v3 CPU, and 128 GB of RAM. The CNN-DNN models were run on a computer with a 2.3 GHz Intel E5-2650 v3 CPU, NVIDIA k20c GPU, and 768 GB of RAM.
The predictive performance of these ensemble models was previously shown in two separate published papers (Shahhosseini et al., 2020, 2021). The results are summarized in the Table 3 (see Supplementary Figure 1 for XY plots of some of the designed ensembles).
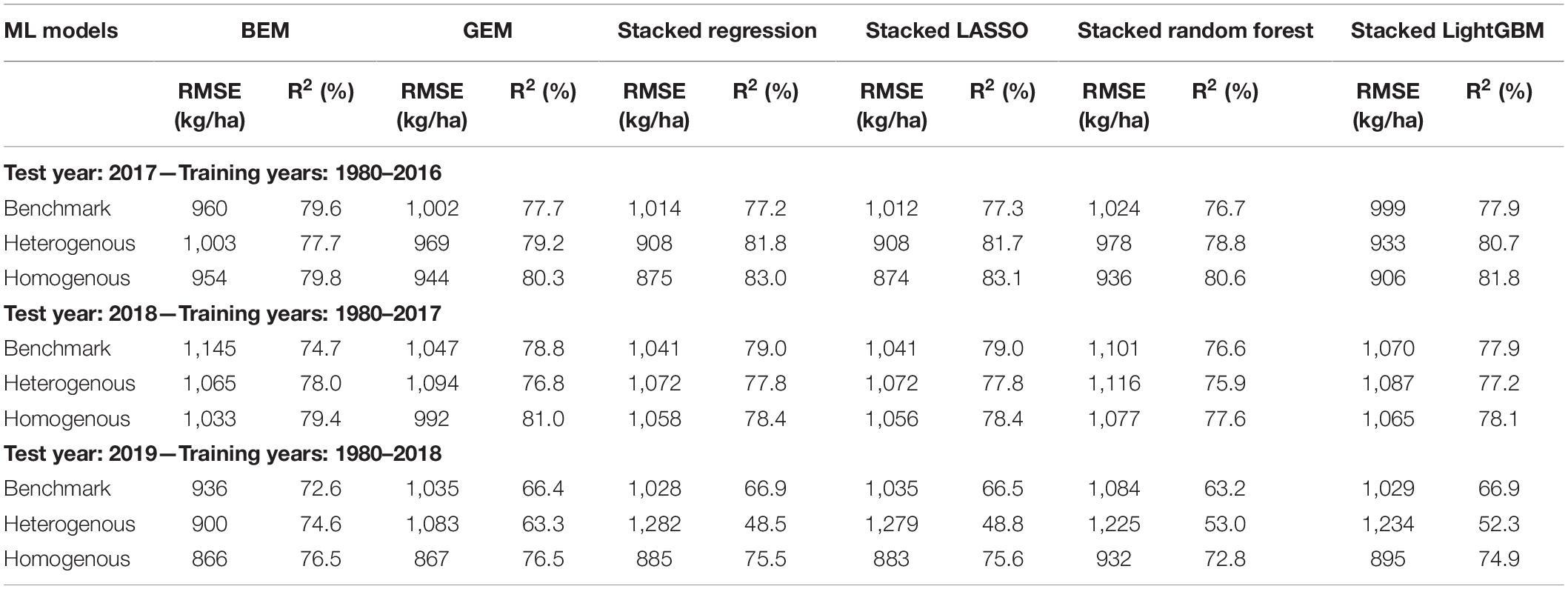
Table 3. Test prediction error (RMSE) and coefficient of determination (R2) of designed ensemble models compared to the benchmark ensembles (Shahhosseini et al., 2020, 2021).
The heterogenous and homogenous ensemble models both provide improvements over the well-performing ensemble benchmarks in most cases (Table 3). However, the heterogenous ensemble model is constantly outperformed by the homogeneous ensemble models. This is in line with what we expected as the homogeneous model inherently introduces more diversity in the ensemble base models which in turn will result in lowering the prediction variance and consequently better generalizability of the trained model. The performance comparison of homogeneous ensemble model compared to the benchmark is shown in the Figure 4. Another observation in the Table 3 is that in case of homogenous ensembles, some of the ensemble creation methods have made better predictions than average homogeneous ensemble (BEM) i.e., bagged CNN-DNN. This again confirms our assertion that assigning unequal weights to the bagged models results in better predictions.
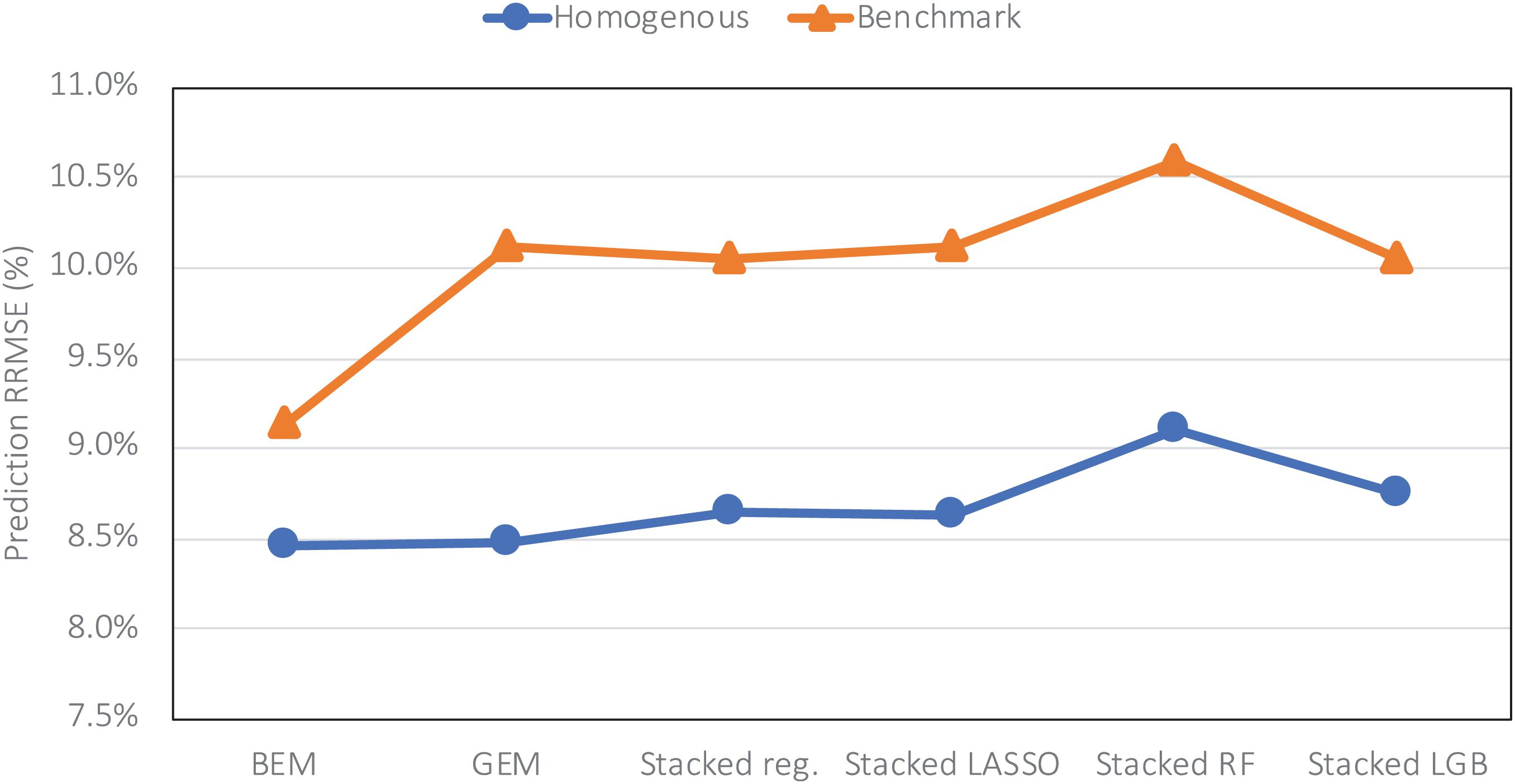
Figure 4. Comparing prediction error (relative RMSE) of the homogeneous model with the benchmark on the data from the year 2019 taken as the test data.
The generalizability of all trained models is proved as we have shown that in three test scenarios, the ensemble models demonstrate superb prediction performance. This also can be observed by looking at the train and test loss vs. epochs graphs. Some examples of these graphs are shown in Figure 5. As the figure suggests, the dropout layers could successfully prevent overfitting of the CNN-DNN models, and the test errors tend to stay stable across the iterations. The generalizability of the trained models will further be discussed in the chapter 4.
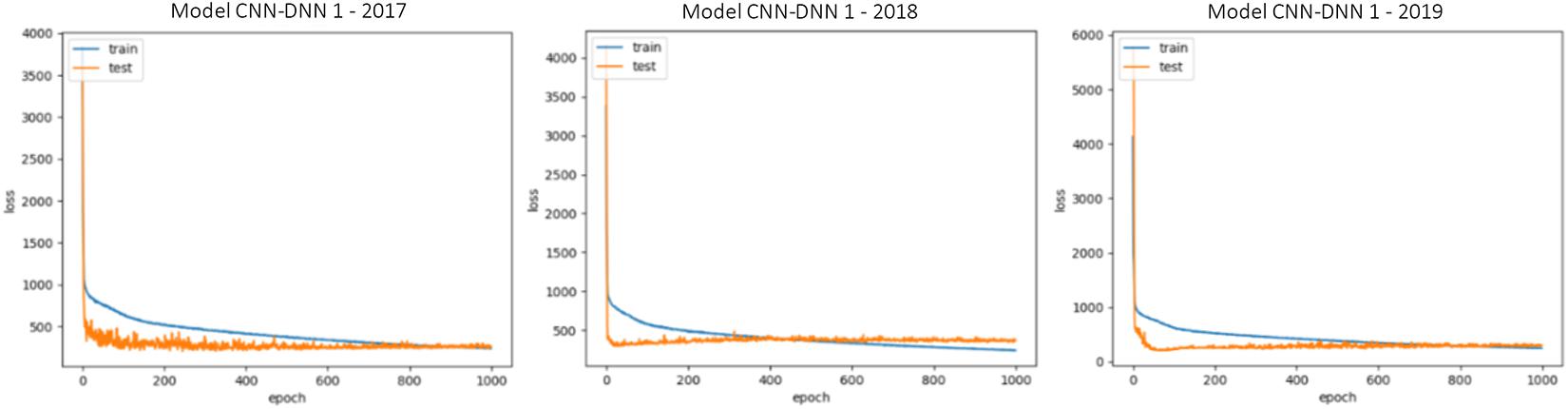
Figure 5. Train and test loss vs. epochs of some of the trained CNN-DNN models. Similar observations were made for all trained models and only some of them are shown for illustration purposes. The shown examples are representative of all the examples.
Discussion
Models’ Performance Comparison With the Literature
We designed a novel CNN-DNN ensemble model with the objective of providing the most accurate prediction model for county-level corn yield across US Corn Belt states. The numerical results confirmed the superb performance of the designed ensemble models compared to literature models. Table 3 showed that the homogenous ensemble models outperform the benchmark (Shahhosseini et al., 2020) by 10–16%. In addition, comparing the results with another well-performing prediction model in the literature (Khaki et al., 2020b), the homogeneous ensemble could outperform the prediction results of Khaki et al. (2020b) by 10–12% in common test set scenarios (2017 and 2018 test years). The CNN-RNN model developed by Khaki et al. (2020b) presented test prediction errors of 988 kg/ha (15.74 bu/acre) and 1,107 kg/ha (17.64 bu/acre) for the test years 2017 and 2018, respectively, while the homogeneous ensemble model designed here resulted in test prediction errors of 874 kg/ha (13.93 bu/acre) and 992 kg/ha (15.8 bu/acre) for the test years 2017 and 2018, respectively.
This is the first study that designed a novel ensemble neural network architecture that has the potential to make the most accurate yield predictions. The model developed here is advantageous compared to the literature due to the ability of the ensemble model in decreasing prediction variance by combining diverse models as well as reducing prediction bias by training the ensemble model based on powerful base models. Shahhosseini et al. (2020) had used ensemble learning for predicting county-level yield prediction, but neural network-based architectures were not considered, and the models were trained only on three states (IL, IA, IN). Khaki et al. (2020b) trained a CNN-RNN model for predicting US Corn Belt corn and soybean yields, but the model developed there is unable to make predictions as accurate as the models designed in this study and is not benefitting from the diversity in the predictions.
Including remote sensing data as well as simulated data from crop model like APSIM could potentially improve the predictions made by our models further which can be pursued as the future research direction. In addition, we assumed all considered farms are rainfed, while in states such as Kansas and Nebraska many of the farms are irrigated. Surprisingly, the prediction accuracy in these states was comparable with other states (Figures 6, 7). We believe this is because of the use of average or rainfed corn yields from these states, not irrigated yields to train our models. Including the irrigation data can result in better prediction and perhaps new models for those states and is another possible future research direction.
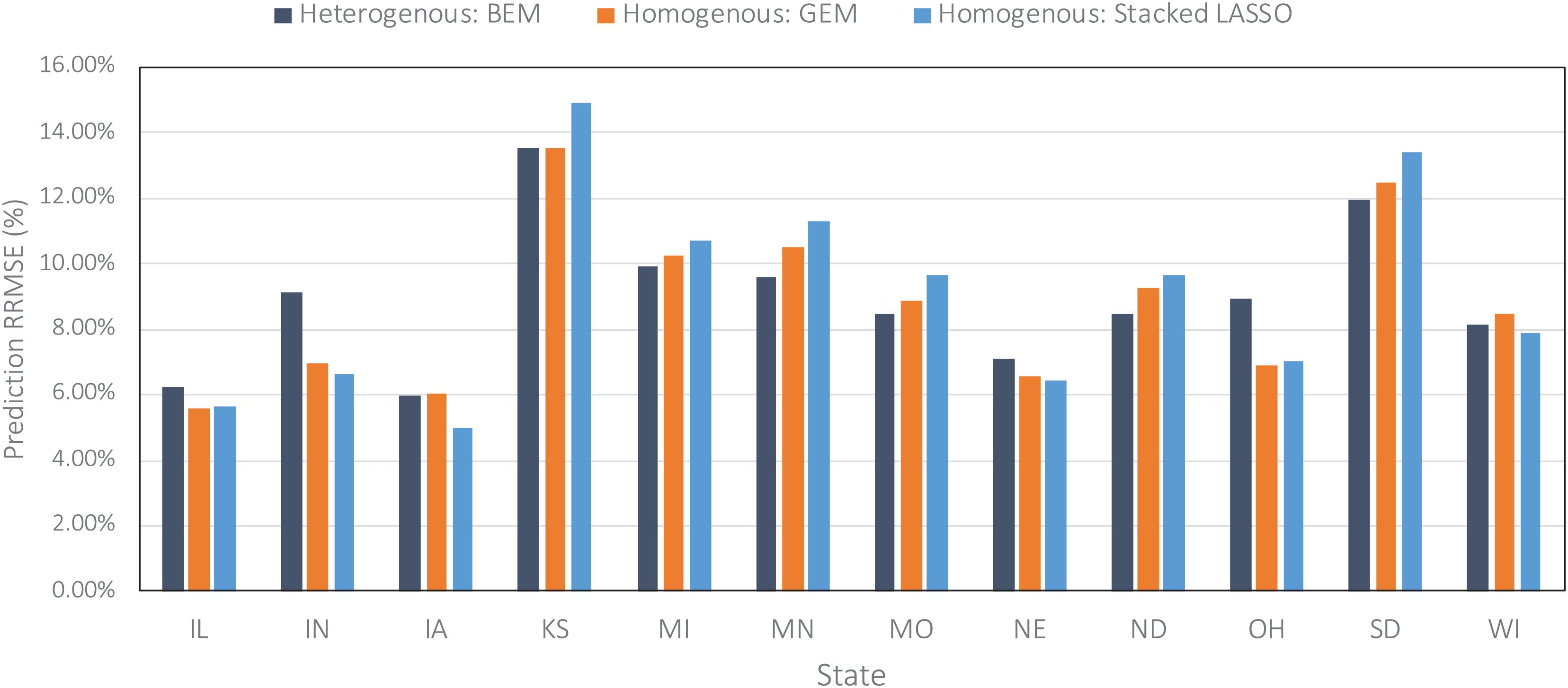
Figure 6. Comparing prediction error (relative RMSE) of some of the designed ensembles across all US Corn Belt states on the data from the year 2019 taken as the test data.
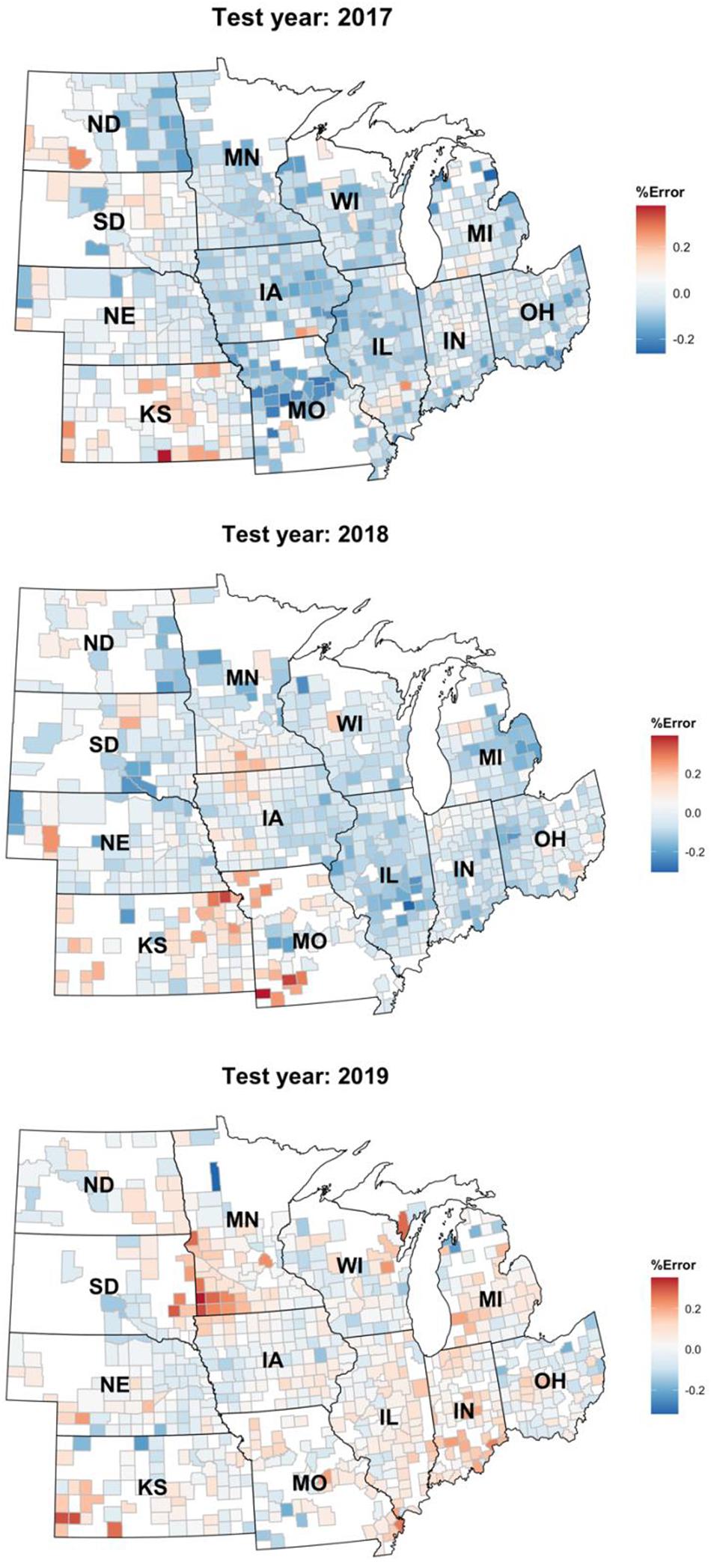
Figure 7. Relative percentage error of the Homogenous GEM predictions shown on a choropleth map of the US Corn Belt.
Comparing the Models’ Performance Across US Corn Belt States
Figure 6 compares the prediction errors of the test year of 2019 for some of the designed ensemble models represented by relative root mean squared error (RRMSE) for each of the 12 US Corn Belt states under study. The models performed the best in Iowa, Illinois, and Nebraska, and worst in Kansas and South Dakota. The worse prediction error in Kansas can be explained by the fact that the majority of the farms in Kansas state are irrigated and this irrigation is not considered as one of the variables when training the ensemble models. It is clear that including irrigation variable can improve the predictions. However, that was not the case for Nebraska, suggesting that irrigation may not be the only reason for the low performance in Kansas. Upon further investigate, we realized the corn yields in the Nebraska state are highly correlated with the weather features especially maximum temperature, while the corn yields in the Kansas state don’t show this amount of correlation to weather features and are slightly correlated with both weather and soil features. In other words, it seems that although the weather features are adequate for making decent predictions in the Nebraska state, this is not the case for the Kansas.
Figure 7 depicts the relative error percentage of each year’s test predictions on a county choropleth map of the US Corn Belt. The errors are calculated by dividing over/under prediction of the homogenous GEM model divided by the yearly average yield. This figure proves that the model is robust and can be easily generalized to other environments/years. One observation is that the model keeps overpredicting the yields in the Kansas state. This could be explained by the irrigation assumption we made when developing the data set. We assumed all the farms are rainfed and did not consider irrigation in states like Kansas in which some of the farms are irrigated.
Generalization Power of the Designed Ensemble CNN-DNN Models
To further test the generalization power of the designed ensembles, we gathered the data of all considered US Corn Belt states for the year 2020 and applied the trained heterogeneous and homogeneous ensemble models as well as the benchmarks on the new unseen observations of the year 2020. As the results imply (Table 4), both heterogenous and homogeneous ensemble models provide better predictions than the benchmark ensemble models, with the homogeneous Generalized Ensemble Model (GEM) being the most accurate prediction model. This model could provide predictions with 958 kg/ha root mean squared error and explain about 77% of the total variability in the response variable.

Table 4. Test prediction error (RMSE) and coefficient of determination (R2) of designed ensemble models compared to the benchmark ensembles (Shahhosseini et al., 2020, 2021) when applied on 2020 test data.
Conclusion
In this study we designed two novel CNN-DNN ensemble types for predicting county-level corn yields across US Corn Belt states. The base architecture used for creating the ensembles is a combination of CNNs and deep neural networks. The CNNs were in charge of extracting useful high-level features from the soil and weather data and provide them to a fully connected network for making the final yield predictions. The two ensemble types were heterogeneous and homogeneous which used the same base CNN-DNN structure but generated the base models in different manners. The homogenous ensemble used one fixed CNN-DNN network but applied it on multiple bagged data sets. The bagged data sets introduced a certain level of diversity that the created ensembles had benefited from. On the other hand, the heterogeneous ensemble used different base CNN-DNN networks which shared the same structure but differed in their number of filters. The different numbers of filters were considered as another method of introducing diversity into the ensembles. All base models generated from either of these two ensemble types were combined with each other using three ensemble creation methods: BEM, GEM, and stacked generalized ensembles. The numerical results showed that the ensemble models of both homogeneous and heterogeneous types could outperform the benchmark ensembles which had previously proved to be effective (Shahhosseini et al., 2020, 2021) as well as well-performing CNN-RNN architecture designed by Khaki et al. (2020b). In addition, homogeneous ensembles provide the most accurate predictions across all US Corn Belt states. The results demonstrated that in addition to the fact that these ensemble models benefitted from higher level of diversity from the bagged data sets, they provided a better combination of base models compared to simple averaging in the bagging. The generalization power of the designed ensembles was proved by applying them on the unseen observations of the year 2020. Once again heterogeneous and homogeneous ensemble models outperformed the benchmark ensembles.
Data Availability Statement
The original contributions presented in the study are included in the article/Supplementary Material, further inquiries can be directed to the corresponding author/s.
Author Contributions
MS led the research and wrote the manuscript. GH oversaw the research and edited the manuscript. SK contributed to the research idea and data processing. SA provided the data and edited the manuscript. All authors contributed to the article and approved the submitted version.
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2021.709008/full#supplementary-material
Footnotes
References
Basso, B., and Liu, L. (2019). “Chapter Four - Seasonal crop yield forecast: Methods, applications, and accuracies,” in Advances in Agronomy, ed. D. L. Sparks (Cambridge, Massachusetts: Academic Press), 154, 201–255. doi: 10.1016/bs.agron.2018.11.002
Bengio, Y., Simard, P., and Frasconi, P. (1994). Learning long-term dependencies with gradient descent is difficult. IEEE Trans. Neural Netw. 5, 157–166. doi: 10.1109/72.279181
Borovykh, A., Bohte, S., and Oosterlee, C. W. (2017). Conditional time series forecasting with convolutional neural networks. arXiv [preprint] Available Online at: arXiv:1703.04691 (accessed April, 2021).
Brown, G. (2017). “Ensemble Learning,” in Encyclopedia of Machine Learning and Data Mining, eds C. Sammut and G. I. Webb (Boston, MA: Springer US), 393–402.
Busetto, L., Casteleyn, S., Granell, C., Pepe, M., Barbieri, M., Campos-Taberner, M., et al. (2017). Downstream Services for Rice Crop Monitoring in Europe: from Regional to Local Scale. [Article]. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 10, 5423–5441.
Cai, Y., Moore, K., Pellegrini, A., Elhaddad, A., Lessel, J., Townsend, C., et al. (2017). Crop yield predictions-high resolution statistical model for intra-season forecasts applied to corn in the US. Paper presented at the 2017 Fall Meeting. United States: Gro Intelligence Inc.
Chlingaryan, A., Sukkarieh, S., and Whelan, B. (2018). Machine learning approaches for crop yield prediction and nitrogen status estimation in precision agriculture: a review. Comput. Electron. Agric. 151, 61–69. doi: 10.1016/j.compag.2018.05.012
Crane-Droesch, A. (2018). Machine learning methods for crop yield prediction and climate change impact assessment in agriculture. Environ. Res. Lett. 13:114003. doi: 10.1088/1748-9326/aae159
Drummond, S. T., Sudduth, K. A., Joshi, A., Birrell, S. J., and Kitchen, N. R. (2003). STATISTICAL AND NEURAL METHODS FOR SITE–SPECIFIC YIELD PREDICTION. Trans. ASAE 46, 5–14.
Everingham, Y., Sexton, J., Skocaj, D., and Inman-Bamber, G. (2016). Accurate prediction of sugarcane yield using a random forest algorithm. Agron. Sustain. Dev. 36:27.
Feng, P., Wang, B., Liu, D. L., Waters, C., and Yu, Q. (2019). Incorporating machine learning with biophysical model can improve the evaluation of climate extremes impacts on wheat yield in south-eastern Australia. Agric. For. Meteorol. 275, 100–113. doi: 10.1016/j.agrformet.2019.05.018
Feng, S.-H., Xu, J.-Y., and Shen, H.-B. (2020). “Chapter Seven - Artificial intelligence in bioinformatics: automated methodology development for protein residue contact map prediction,” in Biomedical Information Technology (Second Edition), ed. D. D. Feng (Cambridge, Massachusetts: Academic Press), 217–237.
Fukuda, S., Spreer, W., Yasunaga, E., Yuge, K., Sardsud, V., and Müller, J. (2013). Random Forests modelling for the estimation of mango (Mangifera indica L. cv. Chok Anan) fruit yields under different irrigation regimes. Agric. Water Manage. 116, 142–150. doi: 10.1016/j.agwat.2012.07.003
González Sánchez, A., Frausto Solís, J., and Ojeda Bustamante, W. (2014). Predictive ability of machine learning methods for massive crop yield prediction. Span. J. Agric. Res. 12, 313–328. doi: 10.5424/sjar/2014122-4439
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for image recognition,” in Paper presented at the Proceedings of the IEEE conference on computer vision and pattern recognition, (Las Vegas, NV, USA: IEEE).
Heremans, S., Dong, Q., Zhang, B., Bydekerke, L., and Orshoven, J. V. (2015). Potential of ensemble tree methods for early-season prediction of winter wheat yield from short time series of remotely sensed normalized difference vegetation index and in situ meteorological data. J. Appl. Remote Sens. 9:097095. doi: 10.1117/1.jrs.9.097095
Ince, T., Kiranyaz, S., Eren, L., Askar, M., and Gabbouj, M. (2016). Real-Time Motor Fault Detection by 1-D Convolutional Neural Networks. IEEE Trans. Industr. Electron. 63, 7067–7075. doi: 10.1109/tie.2016.2582729
Ioffe, S., and Szegedy, C. (2015). Batch normalization: accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv Available Online at: http://arxiv.org/abs/1502.03167. (accessed April, 2021).
Jeong, J. H., Resop, J. P., Mueller, N. D., Fleisher, D. H., Yun, K., Butler, E. E., et al. (2016). Random forests for global and regional crop yield predictions. PLoS One 11:e0156571. doi: 10.1371/journal.pone.0156571
Jiang, D., Yang, X., Clinton, N., and Wang, N. (2004). An artificial neural network model for estimating crop yields using remotely sensed information. Int. J. Remote Sens. 25, 1723–1732. doi: 10.1080/0143116031000150068
Jiang, H., Hu, H., Zhong, R., Xu, J., Xu, J., Huang, J., et al. (2020). A deep learning approach to conflating heterogeneous geospatial data for corn yield estimation: a case study of the US Corn Belt at the county level. Glob. Chang. Biol. 26, 1754–1766. doi: 10.1111/gcb.14885
Khaki, S., Khalilzadeh, Z., and Wang, L. (2020a). Predicting yield performance of parents in plant breeding: a neural collaborative filtering approach. PLoS One 15:e0233382. doi: 10.1371/journal.pone.0233382
Khaki, S., Wang, L., and Archontoulis, S. V. (2020b). A CNN-RNN Framework for Crop Yield Prediction. Front. Plant Sci. 10:1750. doi: 10.3389/fpls.2019.01750
Khaki, S., and Wang, L. (2019). Crop Yield Prediction Using Deep Neural Networks. Front. Plant Sci. 10:621. doi: 10.3389/fpls.2019.00621
Kim, N., Ha, K.-J., Park, N.-W., Cho, J., Hong, S., and Lee, Y.-W. (2019). A Comparison Between Major Artificial Intelligence Models for Crop Yield Prediction: case Study of the Midwestern United States, 2006–2015. ISPRS Int. J. Geo Inform. 8:240. doi: 10.3390/ijgi8050240
Kiranyaz, S., Ince, T., Abdeljaber, O., Avci, O., and Gabbouj, M. (2019). “1-D Convolutional Neural Networks for Signal Processing Applications,” in Paper presented at the ICASSP 2019 - 2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), (Brighton, UK: IEEE).
Liu, J., Goering, C., and Tian, L. (2001). A neural network for setting target corn yields. Trans. ASAE 44, 705–713.
Mavromatis, T. (2016). Spatial resolution effects on crop yield forecasts: an application to rainfed wheat yield in north Greece with CERES-Wheat. Agric. Syst. 143, 38–48. doi: 10.1016/j.agsy.2015.12.002
Mupangwa, W., Chipindu, L., Nyagumbo, I., Mkuhlani, S., and Sisito, G. (2020). Evaluating machine learning algorithms for predicting maize yield under conservation agriculture in Eastern and Southern Africa. SN Appl. Sci. 2:952.
NASS, U. (2019). Surveys. National Agricultural Statistics Service. Washington, D.C., United States: U.S. Department of Agriculture.
Pagani, V., Stella, T., Guarneri, T., Finotto, G., van den Berg, M., Marin, F. R., et al. (2017). Forecasting sugarcane yields using agro-climatic indicators and Canegro model: a case study in the main production region in Brazil. Agric. Syst. 154, 45–52. doi: 10.1016/j.agsy.2017.03.002
Pantazi, X. E., Moshou, D., Alexandridis, T., Whetton, R. L., and Mouazen, A. M. (2016). Wheat yield prediction using machine learning and advanced sensing techniques. Comput. Electron. Agric. 121, 57–65. doi: 10.1016/j.compag.2015.11.018
Perrone, M. P., and Cooper, L. N. (1992). When Networks Disagree: Ensemble Methods For Hybrid Neural Networks. Rhode Island: Brown University in Providence.
Shahhosseini, M., Hu, G., and Archontoulis, S. V. (2020). Forecasting Corn Yield With Machine Learning Ensembles. Front. Plant Sci. 11:1120 doi: 10.3389/fpls.2020.01120
Shahhosseini, M., Hu, G., Huber, I., and Archontoulis, S. V. (2021). Coupling machine learning and crop modeling improves crop yield prediction in the US Corn Belt. Sci. Rep. 11:1606. doi: 10.1038/s41598-020-80820-1
Shahhosseini, M., Martinez-Feria, R. A., Hu, G., and Archontoulis, S. V. (2019). Maize yield and nitrate loss prediction with machine learning algorithms. Environ. Res. Lett. 14:124026. doi: 10.1088/1748-9326/ab5268
Simonyan, K., and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv Available Online at: http://arxiv.org/abs/1409.1556. (accessed April, 2021).
Soil Survey Staff [SSS]. (2019). Natural Resources Conservation Service United States Department of Agriculture Web Soil Survey Available Online at: https://websoilsurvey.nrcs.usda.gov/. (accessed April, 2021).
Srivastava, N., Hinton, G., Krizhevsky, A., Sutskever, I., and Salakhutdinov, R. (2014). Dropout: a simple way to prevent neural networks from overfitting. J. Mach. Learn. Res. 15, 1929–1958.
Stas, M., Van Orshoven, J., Dong, Q., Heremans, S., and Zhang, B. (2016). “A comparison of machine learning algorithms for regional wheat yield prediction using NDVI time series of SPOT-VGT,” in 2016 Fifth International Conference on Agro-Geoinformatics (Agro-Geoinformatics). IEEE. (pp. 1–5).
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). “Going deeper with convolutions,” in Paper Presented At The Proceedings Of The IEEE Conference On Computer Vision And Pattern Recognition, (Boston, MA, USA: IEEE).
Vincenzi, S., Zucchetta, M., Franzoi, P., Pellizzato, M., Pranovi, F., De Leo, G. A., et al. (2011). Application of a Random Forest algorithm to predict spatial distribution of the potential yield of Ruditapes philippinarum in the Venice lagoon, Italy. Ecol. Model. 222, 1471–1478. doi: 10.1016/j.ecolmodel.2011.02.007
Wang, A. X., Tran, C., Desai, N., Lobell, D., and Ermon, S. (2018). “Deep transfer learning for crop yield prediction with remote sensing data,” in Paper presented at the Proceedings of the 1st ACM SIGCAS Conference on Computing and Sustainable Societies. New York, United States: ACM
Yang, Q., Shi, L., Han, J., Zha, Y., and Zhu, P. (2019). Deep convolutional neural networks for rice grain yield estimation at the ripening stage using UAV-based remotely sensed images. Field Crops Res. 235, 142–153. doi: 10.1016/j.fcr.2019.02.022
You, J., Li, X., Low, M., Lobell, D., and Ermon, S. (2017). “Deep gaussian process for crop yield prediction based on remote sensing data,” in Paper presented at the Thirty-First AAAI conference on artificial intelligence, (Menlo Park: AAAI).
Zhang, C., and Ma, Y. (2012). Ensemble Machine Learning: Methods And Applications. Germany: Springer.
Zhu, W., Ma, Y., Zhou, Y., Benton, M., and Romagnoli, J. (2018). “Deep Learning Based Soft Sensor and Its Application on a Pyrolysis Reactor for Compositions Predictions of Gas Phase Components,” in Computer Aided Chemical Engineering, eds M. R. Eden, M. G. Ierapetritou, and G. P. Towler (Amsterdam: Elsevier), 44, 2245–2250. doi: 10.1016/b978-0-444-64241-7.50369-4
Keywords: yield prediction, CNN-DNN, homogenous ensemble, heterogenous ensemble, US Corn Belt
Citation: Shahhosseini M, Hu G, Khaki S and Archontoulis SV (2021) Corn Yield Prediction With Ensemble CNN-DNN. Front. Plant Sci. 12:709008. doi: 10.3389/fpls.2021.709008
Received: 13 May 2021; Accepted: 05 July 2021;
Published: 02 August 2021.
Edited by:
Kioumars Ghamkhar, AgResearch Ltd., New ZealandReviewed by:
Jingli Lu, AgResearch Ltd., New ZealandMonica Herrero Huerta, Purdue University, United States
Copyright © 2021 Shahhosseini, Hu, Khaki and Archontoulis. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Guiping Hu, Z3BodUBpYXN0YXRlLmVkdQ==