 Jue Wang1†
Jue Wang1† Yuankai Tian
Yuankai Tian Silan Dai
Silan Dai- 1Beijing Key Laboratory of Ornamental Plants Germplasm Innovation and Molecular Breeding, Beijing Laboratory of Urban and Rural Ecological Environment, Key Laboratory of Genetics and Breeding in Forest Trees and Ornamental Plants of Ministry of Education, National Engineering Research Center for Floriculture, School of Landscape Architecture, Beijing Forestry University, Beijing, China
- 2College of Technology, Beijing Forestry University, Beijing, China
The traditional Chinese large-flowered chrysanthemum is one of the cultivar groups of chrysanthemum (Chrysanthemum × morifolium Ramat.) with great morphological variation based on many cultivars. Some experts have established several large-flowered chrysanthemum classification systems by using the method of comparative morphology. However, for many cultivars, accurate recognition and classification are still a problem. Combined with the comparative morphological traits of selected samples, we proposed a multi-information model based on deep learning to recognize and classify large-flowered chrysanthemum. In this study, we collected the images of 213 large-flowered chrysanthemum cultivars in two consecutive years, 2018 and 2019. Based on the 2018 dataset, we constructed a multi-information classification model using non-pre-trained ResNet18 as the backbone network. The model achieves 70.62% top-5 test accuracy for the 2019 dataset. We explored the ability of image features to represent the characteristics of large-flowered chrysanthemum. The affinity propagation (AP) clustering shows that the features are sufficient to discriminate flower colors. The principal component analysis (PCA) shows the petal type has a better interpretation than the flower type. The training sample processing, model training scheme, and learning rate adjustment method affected the convergence and generalization of the model. The non-pre-trained model overcomes the problem of focusing on texture by ignoring colors with the ImageNet pre-trained model. These results lay a foundation for the automated recognition and classification of large-flowered chrysanthemum cultivars based on image classification.
Introduction
The traditional Chinese large-flowered chrysanthemum (larger-flowered chrysanthemum) is a particular group of chrysanthemum (Chrysanthemum × morifolium Ramat.) derived from wild Chrysanthemum species through domestication and selection for over 2,600 years in China (Dai et al., 2012). The cultivar group of large-flowered chrysanthemum has over 3,000 cultivars to date, and they exhibit a rich diversity in floral morphology. Thus, this cultivar group possesses excellent aesthetic value and prospects for the market (Zhang et al., 2014a; Dai and Hong, 2017; Su et al., 2019).
Cultivar identification and classification are very important for production and communication (Yu, 1963). Similar to the cultivar classification system for other ornamental plants, such as Lily,1 Rosa,2 Daffodils,3 and Peony,4 the classification of large-flowered chrysanthemum is also based on critical morphological traits, such as flower color (Hong et al., 2012), flower type (Zhang et al., 2014b), petal type (Song et al., 2018), and leaf type (Song et al., 2021), and classifies a considerable number of cultivars into multiple groups with high similarity within-group and high variation between groups.
At present, the researchers widely use the classification system of 9-color series based on flower color (Hong et al., 2012), five petal types, and 30 flower types based on flower shape (Wang, 1993). In the former, the large-flowered chrysanthemum is divided into nine color groups by quantitative classification. In the latter, the petal type (flat, spoon, tubular, anemone, and peculiar) is the first criteria of the classification, and the second is the flower shape (the petal details and the combination relationship among petals). The above two systems determine the distribution of floral characteristics in large-flowered chrysanthemum (Figure 1).
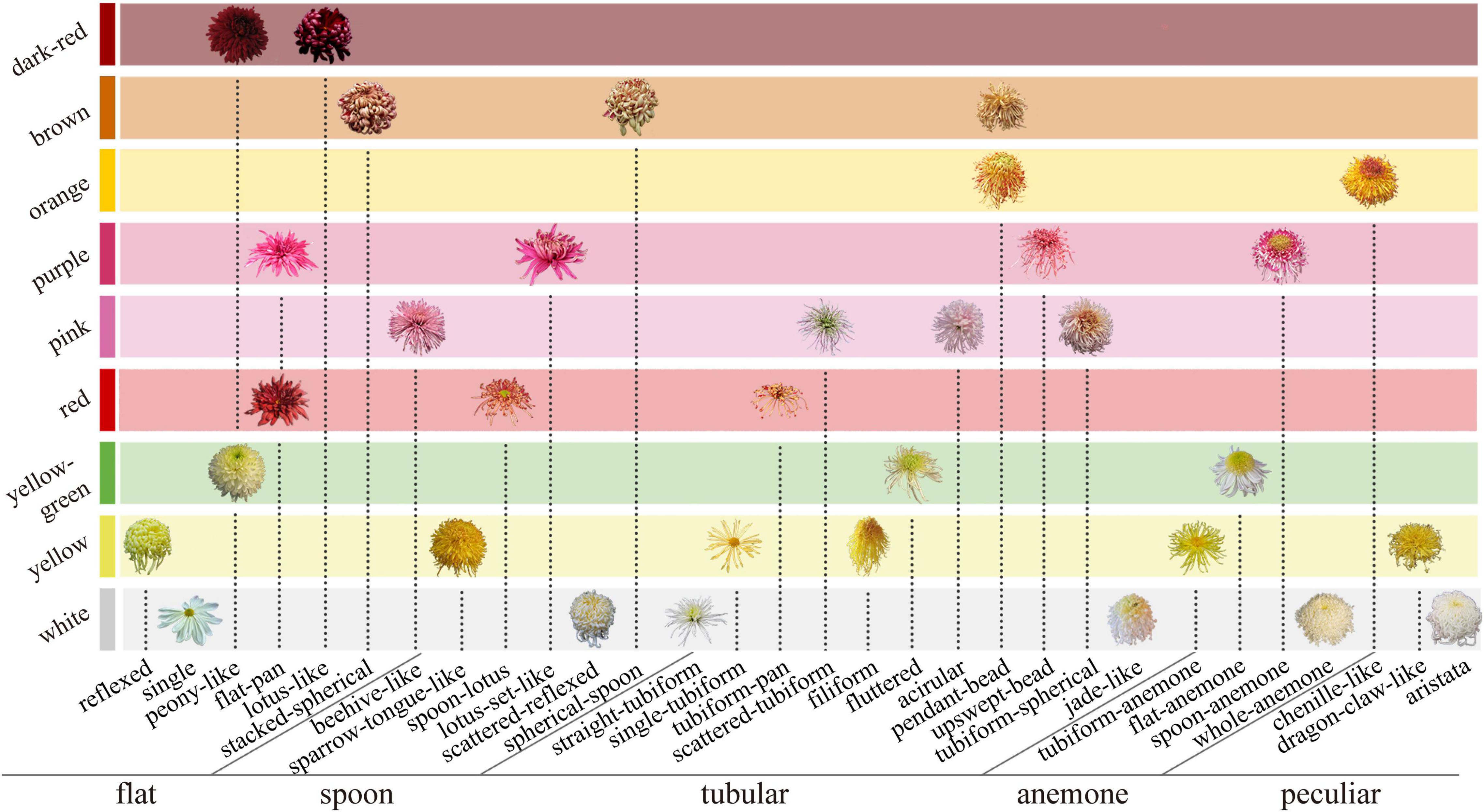
Figure 1. Classification system of large-flowered chrysanthemum based on flower color, petal type, and flower type.
However, faced with the vast number of large-flowered chrysanthemum cultivars, morphological variability within a cultivar, and similarity to other cultivars, the above classification system’s efficiency, and accuracy are often challenged.
Deep learning is an emerging area of machine learning for tackling large data analytics problems (Ubbens and Stavness, 2017). As one of the most popular branches of machine learning research, deep learning has been widely employed and has attracted more attention from various domains, such as protein prediction (Le and Huynh, 2019; Tng et al., 2022), plant disease detection (Abade et al., 2021), plant yield, growth prediction (Ni et al., 2020; Shibata et al., 2020), and animal identification (Norouzzadeh et al., 2018; Spiesman et al., 2021).
A significant trend in plant recognition in recent years has been to use deep learning for plant image classification (Wldchen and Mder, 2018). The network that applies to deep learning for plant images classification is the deep convolutional neural network (DCNN), which establishes the classification model by extracting features of plant images. So far, DCNN derived a series of network structures, such as VGG (Visual Geometry Group) (Simonyan and Zisserman, 2015), GoogleNet (Szegedy et al., 2015), and ResNet (Residual Neural Network) (He et al., 2016). ResNet is the first classification network that surpasses human accuracy in classification tasks (Russakovsky et al., 2015). At present, the ResNet-based classification model has been widely used in plant image research, such as plant age judgment (Yue et al., 2021), flowering pattern analysis (Jiang et al., 2020), and root image analysis (Wang et al., 2020).
For plant recognition, users only need to provide images of plant organs, such as leaves (Zhang et al., 2020) and flowers (Seeland et al., 2017; Liu et al., 2019), to complete the recognition of plants. With the application of related research and development, over 30,000 species of plants could be recognized (Mäder et al., 2021). However, because of the difficulties in data acquisition, many deep learning methods used pre-training models based on ImageNet (He et al., 2015, 2016; Russakovsky et al., 2015; Chattopadhay et al., 2018) as the backbone network, but ImageNet-trained CNNs are strongly biased toward recognizing textures and not sensitive to color (Geirhos et al., 2018). When using the classifier constructed by the ImageNet-trained model to test the images of large-flowered chrysanthemum in 2008, we also found that the top-5 results and test images have similar textures but a difference in color (Figure 2).

Figure 2. Examples of misclassified images by the pre-training model. (A) The test images. (B) The Top-5 results.
A number of previous studies utilized deep learning for plant image classification, which only provided single taxonomic information of plants (Waeldchen and Maeder, 2018). A recent study on large-flowered chrysanthemum image classification (Liu et al., 2019) established a recognition model with the output of cultivar name. It cannot fully meet the requirements of large-flowered chrysanthemum recognition and classification. It is important to recognize large-flowered chrysanthemum, and the classification according to corresponding petal type and flower type is also necessary for practical application. These results have practical value in market communication and landscape application.
We also consider the large intra-cultivar visual variation. The large-flowered chrysanthemum belonging to the same cultivars may show considerable differences in their morphological characteristics depending on their different abiotic factors, development stage, and opening periods, which is a challenge to the generalization of the model (Liu et al., 2019).
Based on previous research, for large-flowered chrysanthemum recognition and classification, and to overcome the bias to texture, we proposed a multi-information classification model that can output flower type, petal type, and cultivar name. We also tested the model’s generality on the datasets of different years.
Materials and Methods
Plant Material
According to the previous classification system of flower type and color (Wang, 1993; Hong et al., 2012), we selected large-flowered chrysanthemums in the chrysanthemum resource nursery (in Dadongliu nursery in Beijing) of the research group. To cover all flower colors, petal types, and flower types of chrysanthemum cultivars, we selected 126 cultivars in 2018 (as shown in Supplementary Table 1) and 117 cultivars in 2019 (as shown in Supplementary Table 2). After removing the duplication, there were 213 cultivars in 2018 and 2019.
Referring to the Chinese Chrysanthemum book (Zhang and Dai, 2013), we accomplished the cultivation and management of large-flowered chrysanthemum in the Dadongliu nursery in Beijing in 2018 and 2019, respectively.
Image Acquisition and Labeling
The image acquisition of large-flowered chrysanthemum was carried out during flowering periods in November to December in 2018 and 2019. The image acquisition device and image acquisition process are the same as the study by Liu et al. (2019). The image resolution was 6,000 × 6,000 pixels, and the format was PNG. In the gathered images, each cultivar had at least 2–3 individuals. We photographed each individual from the top view and oblique views while ignoring the background.
All the collected images were accurately and uniformly marked using LabelImg v1.7.0 software. See Supplementary Table 3 for cultivar name, petal type, and flower type marking.
Dataset Construction
2018 Dataset (Training Dataset and Validation Dataset)
The 2018 dataset contained 126 cultivars. To balance the samples, we randomly selected 80 images from each cultivar for 10,080 images. A total of 80% of the images were used for training and 20% for validating. Data augmentation plays a crucial role in improving classification performances. However, large-flowered chrysanthemum recognition is similar to face recognition, so some common data enhancement methods are not adopted. For example, color is essential information for flowers. Therefore, methods such as color jitter and gray scales are unsuitable for actually identified scenes. In addition, the symmetry of chrysanthemum structure, rotation, and flip operations are invalid. For large-flowered chrysanthemum image recognition, the deep network model focuses on the local information of the image (Liu et al., 2019), so the cropping is only for the training dataset. The original image of the training dataset is scaled to 256 × 256 pixels then randomly cropped to 224 × 224 pixels image patch. By random cropping, we expanded the number of the training dataset (Figure 3A) by 10 times to 80,640. The validation dataset (Figure 3B) is 2,016 images used to determine model architecture and hyper-parameters.

Figure 3. Sample images from dataset training and validation. (A,B) Are training and validation dataset, respectively.
2019 Dataset (Test Dataset)
The 2019 dataset contained 2,556 images belonging to 117 cultivars, including 640 images of 30 similar cultivars as the 2018 dataset. This dataset formed the test dataset. Figure 4 shows some of the same cultivars in 2018 and 2019. Because of the differences in climate environment and photo time in 2018 and 2019, the flower type of the same cultivar has changed to some extent, which can test the model’s generalization.

Figure 4. Some sample images in the 2018 and 2019 datasets. Row (A,B) belong to the 2018 and 2019 datasets, respectively.
Devices
The models were built and trained on the Ubuntu 16.04 system, based on Intel Xeon Gold 5120 CPU and 4 NVIDIA Titan Xp 16GB GPU hardware platform.
Approach
Many researchers used the pre-trained network model on the ImageNet dataset to extract image features. As mentioned above, ImageNet-trained CNNs are strongly biased toward recognizing textures and ignoring color. However, for large-flowered chrysanthemum, color is an essential characteristic for classification. We used the script of non-pre-trained ResNet18 (He et al., 2016) as the backbone network. Due to the limited amount of data, we abandoned the deeper network, such as ResNet50. The network comprised three parallel softmax classifiers to get a richer feature representation of large-flowered chrysanthemum images. It means that the network model has three outputs about botanical information of cultivar name, flower type, and petal type, respectively. Figure 5 shows the network structure. The features of the images are flatten-layer output with 512-dimensions. Keras was used for our experiments. The DCNN was initialized by He initialization (He et al., 2015).
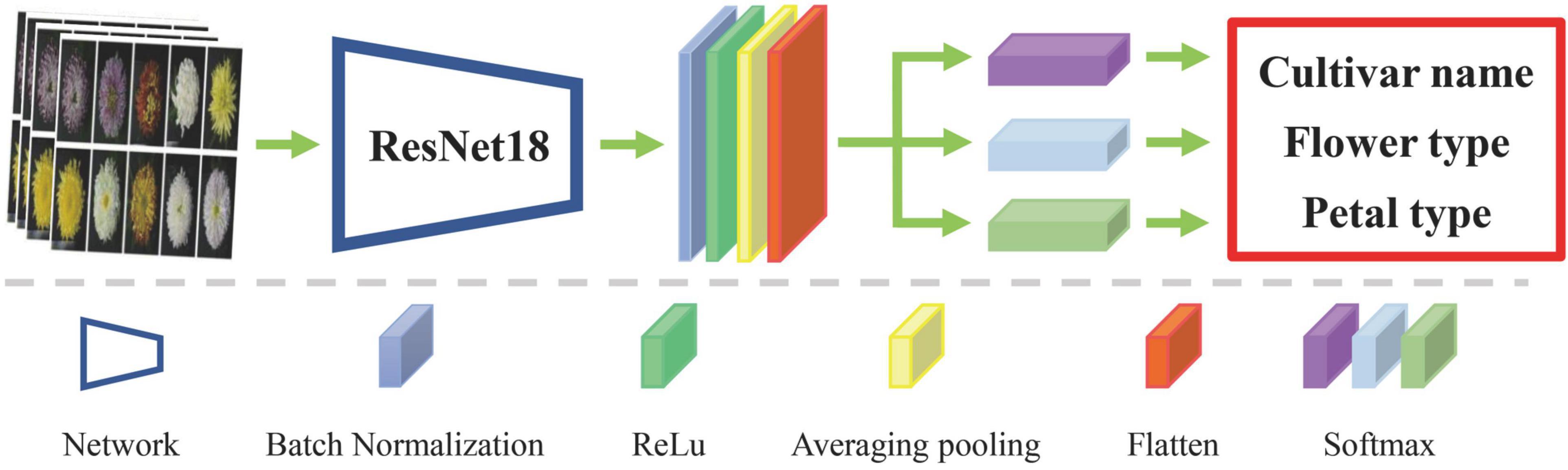
Figure 5. Architecture of the network model.
Model Training
The total loss function (1) includes cultivar name loss, flower type loss, and petal type loss.
The label smoothing (Szegedy et al., 2016) was used to increase the convergence rate in the training phase. The optimization method was the Stochastic Gradient Descent (SGD), Momentum of 0.9, training used a batch size of 32, and was terminated after 40 epochs.
In training, the network’s weights are updated according to a certain strategy. The weight update function is defined as (2).
α is the learning rate, the gradient is the corresponding weight gradient.
Because the model used the script of the ResNet18 network with nearly 32M parameters and 80,640 pictures in the training dataset, the network was easy to overfit. To avoid overfitting, we used different learning rate adjustment methods (Rosebrock, 2021) for comparison.
In the standard-decay strategy, the initial init_lr = 1e-2, the function is (3).
In the step-decay strategy, the initial init_lr = 1e-2, the formula is (4).
αI represents the initial learning rate, F represents the learning rate factor, F = 0.25, E represents the current echo, D represents each echo to adjust the learning rate, D = 10.
In the line-decay strategy, the initial init_lr = 1e-2, the formula is (5).
When pow = 1, it means the line-decay approach.
In the poly-decay strategy, the initial init_lr = 1e-2 (when pow = 5, it means the poly-decay strategy), the formula is (5).
Evaluation of Results
We used the Top-k accuracy to evaluate the model. If the K results include the correct categories, we consider the results valid. It took the average value of all images in each cultivar test dataset as the Top-1 and Top-5 accuracy. In addition, we used the F1-score and recall as the evaluation metrics.
Feature Analysis
After training, we extracted the 512-dimensional image features for the 126 cultivars in the 2018 validation dataset and 87 cultivars in the 2019 test dataset. By the AP clustering (Frey and Dueck, 2007), the correlation between image features and large-flowered chrysanthemum phenotype was analyzed. To explore the class separability of cultivars in the PCA space, we colored the points according to their characteristic labels.
Results
Model Training
We showed the loss change process of the training dataset and the validation dataset by different learning rate adjustment methods in Figure 6. As shown in Figure 6A, Standard-decay caused the convergence to be unstable, causing the loss curve to spike twice. At the same time, other learning rate adjustment methods were relatively stable, and the loss curve maintained stability. In the training process, the loss of the validation dataset gradually decreases, and the loss of the training process using the poly-decay strategy decreases most smoothly (Figure 6D), which reflects that the poly-decay strategy can ensure the convergence of the network.
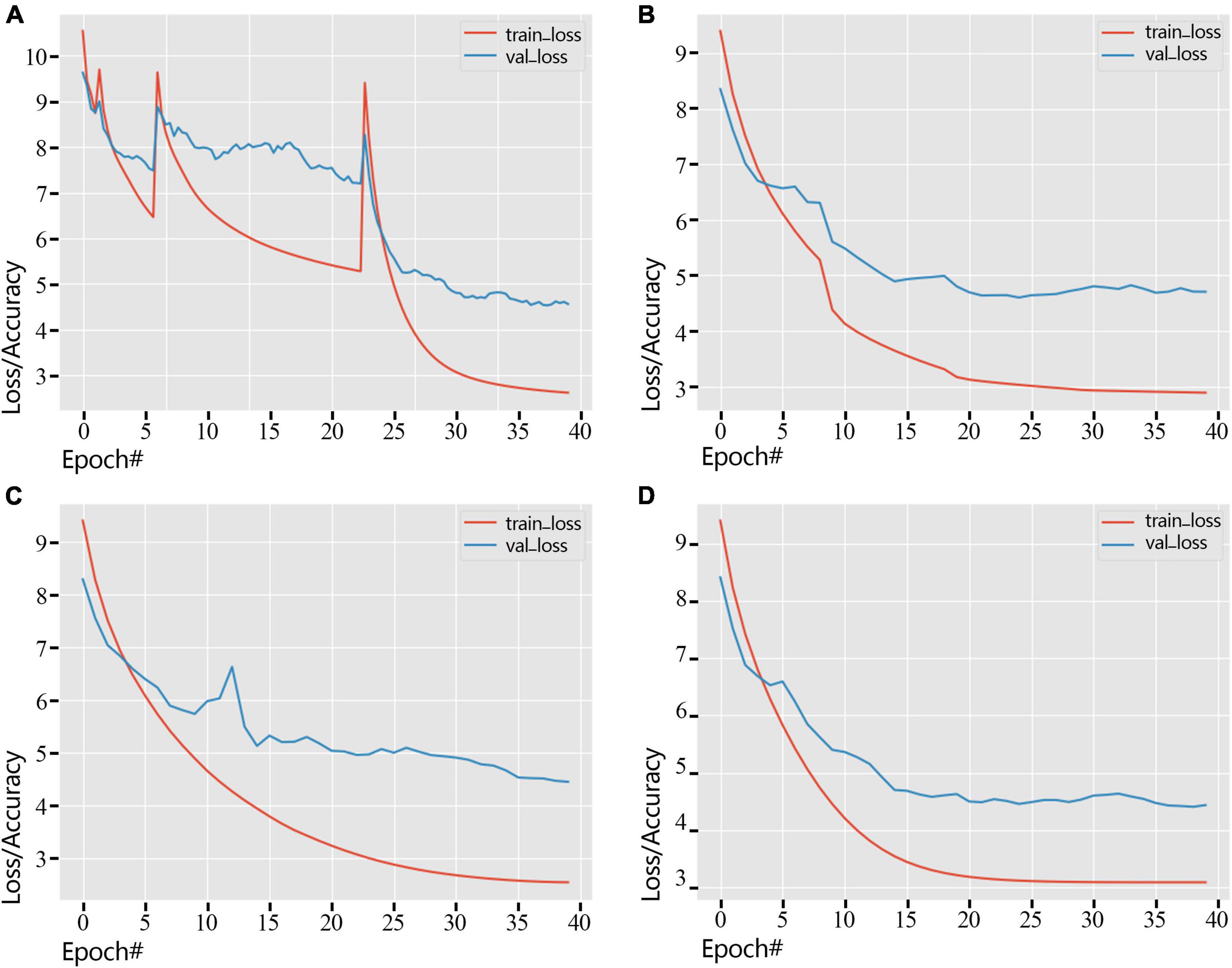
Figure 6. Error variation of training dataset and validation dataset under different strategies (2018 dataset). (A) Standard-decay. (B) Step-decay. (C) Line-decay. (D) Poly-decay.
By observing the loss changes of the three classifiers, i.e., cultivar name, flower type, and petal type, we obtain the best convergence result using the poly-decay strategy (Figure 7). Among the three classifiers, the petal type classifier has the highest accuracy because the model pays more attention to local features such as petal type than global features such as cultivar name and flower type (Figure 7D).
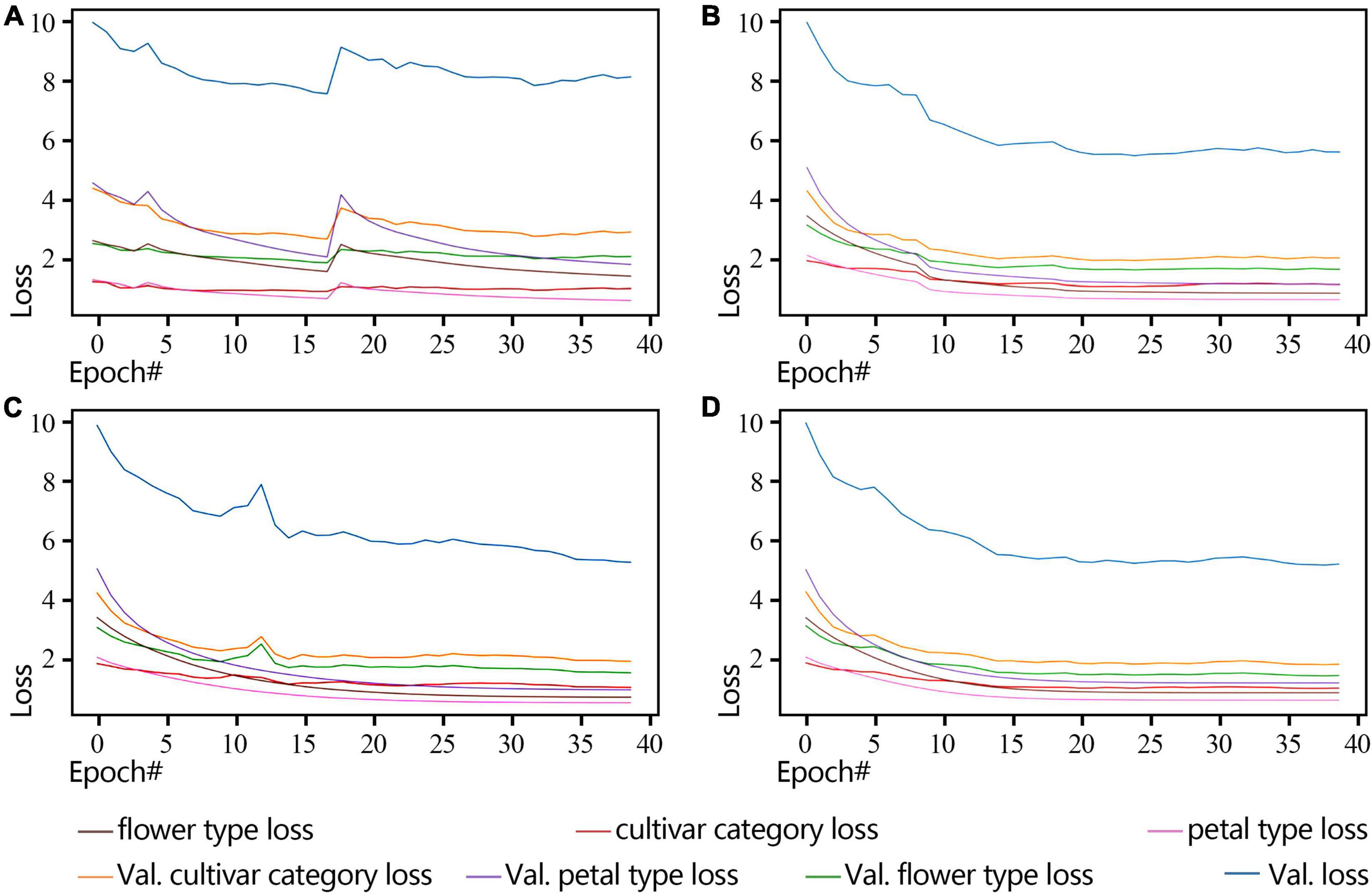
Figure 7. ResNet18 Loss curve of a non-pre-training model during training and validation (2018 dataset). (A) Standard-decay. (B) Step-decay. (C) Line-decay. (D) Poly-decay.
The validation accuracies of Top-1 and Top-5 of cultivar name, flower type, and petal type of 2018 validation dataset using four kinds of decay strategies are shown in Table 1. Except that the petal type of Top-1 accuracy is lower than the step-decay strategy, the other accuracies of the poly-decay are the highest, poly-decay also had the highest recall and F1-score.

Table 1. Comparison of decay strategy performance in the validation dataset.
Model Generalization Performance
The generalization ability to the 640 images of the same cultivars in the 2019 dataset and the 2018 dataset, while comparing the influence of image cropping, is shown in Table 2. For petal type, a local feature, the model’s accuracy with cropping image patches is higher than that without cropping. Compared with the petal type, the flower type, which reflects the overall features of the large-flowered chrysanthemum, the model’s accuracy with cropping image patches is lower than that without cropping. For cultivar name, the model’s accuracy with cropping image patches is four times higher than without cropping, confirming the previous conclusion that the large-flowered chrysanthemum classification model focuses on the local (Liu et al., 2019).

Table 2. Influence of cropping or non-cropping models on a generalization of 2019 cultivars classification.
The model could accurately identify the morphological changes of the same cultivars to some extent (Figure 8). The results show that among 30 cultivars, the accuracy of 9 cultivars is greater than or equal to 90%, and 18 cultivars are greater than or equal to 80%. For some cultivars (red frames marked) with significant morphological changes, the model can identify them with a high accuracy rate (over 85%). We also found some cultivars (blue frames marked) that changed to the degree that exceeded the model’s generalization, and we will further analyze this problem in our discussion.
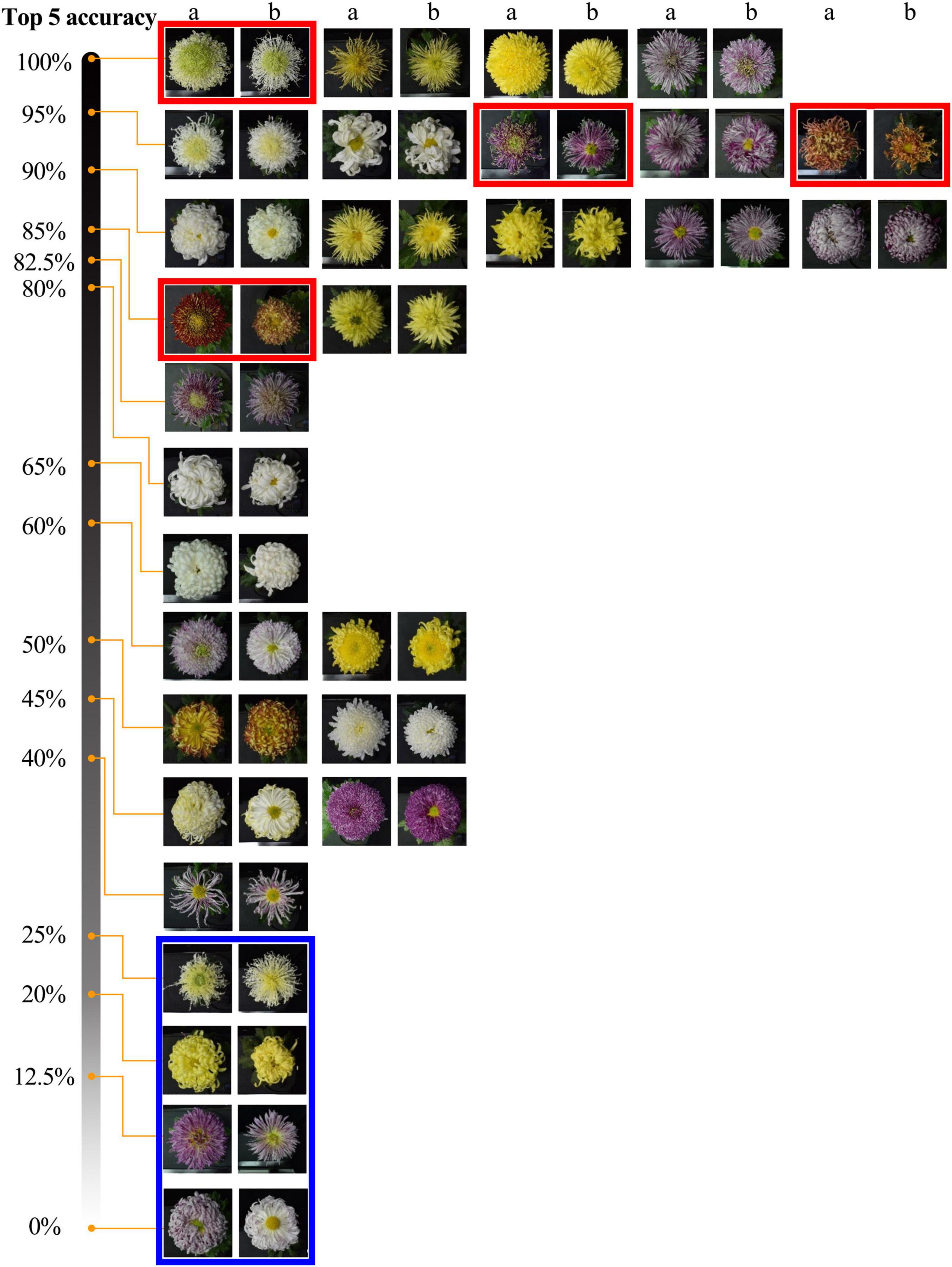
Figure 8. Top-5 recognition results of 2019 dataset. The two adjacent columns are the same cultivar, a and b belong to the 2019 and 2018 datasets. Red and blue frames indicate some cultivars with noticeable morphological changes but with high and low identification accuracy.
The Top-5 results’ details of some cultivars are shown in Figure 9. The Top-5 results are consistent in the flower color, which indicates that the model can recognize the vital character of flower color. When focusing on petal type and flower type, we found the model has higher accuracy for petal type.

Figure 9. Top-5 results of some cultivars. (A) is test images, (B) is Top-5 results, and the possibility from left to right gradually reduced. The text below the picture means the corresponding flower type and petal type for each cultivar.
Affinity Propagation Cluster Analysis
The AP clustering algorithm was used to cluster and compare the image features of the 2018 validation dataset (Figure 10). The maximum number of iterations is 1,000, the attenuation coefficient is λ = 0.9, and the convergence condition is δ = 100. The Ap clustering result is shown in Figure 10B. The 126 cultivars in 2018 were automatically clustered into 17 categories and the central cultivars of each category were extracted, as shown in the red frame.
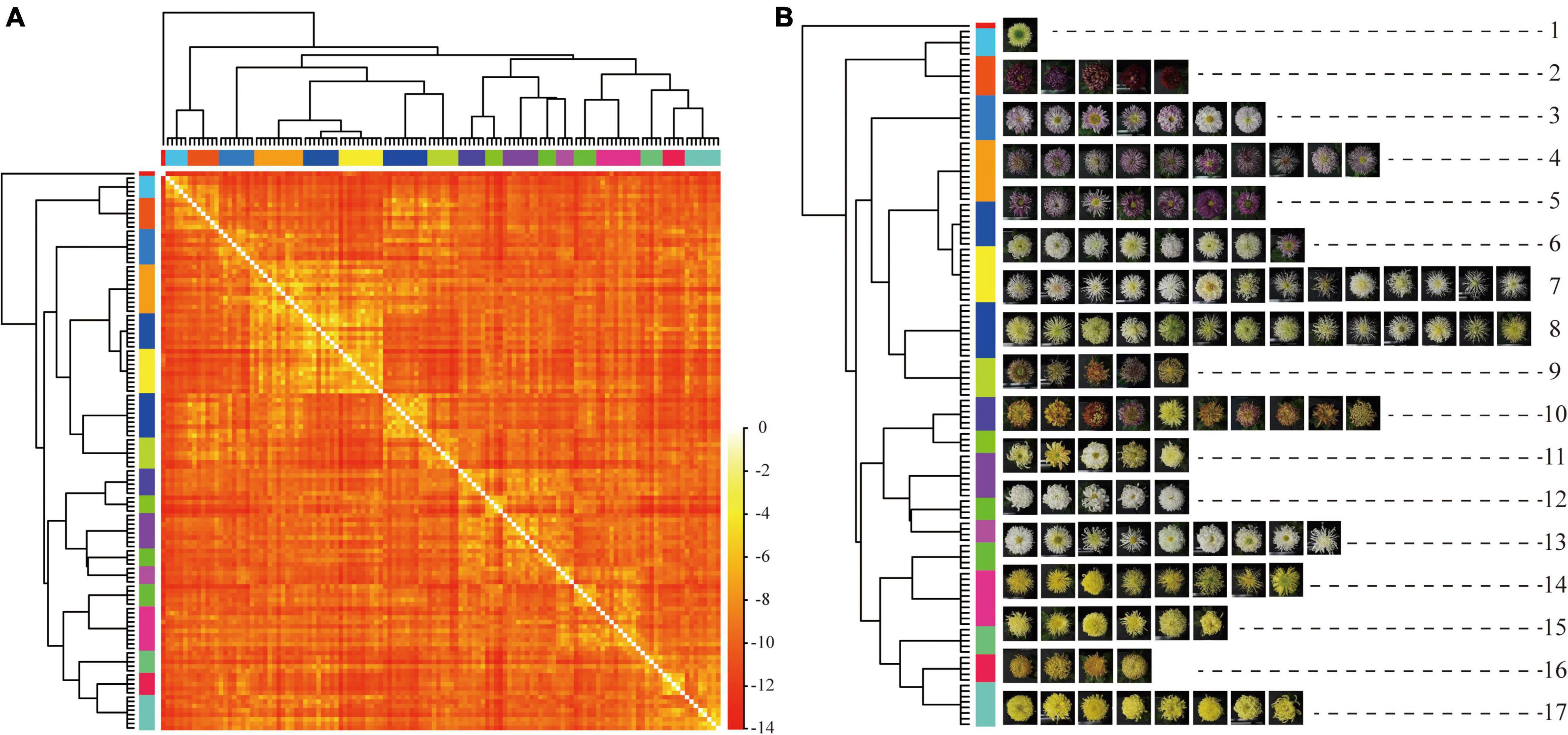
Figure 10. AP clustering analysis of image features of 126 cultivars. (A) AP clustering heat map of image features of 126 cultivars. (B) AP clustering analysis of image features of 126 cultivars. Note: each row represents a cluster, and the red box is the central cultivar of each category.
The large-flowered chrysanthemum images were not labeled with any color information, and the AP clustering still showed prominent clustering features by color. The second cluster belonged to dark red, the 12th cluster belonged to white, and the 14th, 15th, and 17th clusters belonged to yellow. While in other clusters, although they were not all the same color, the cultivars in the same clusters belonged to similar colors, such as the third, fourth, and fifth clusters belonged to pink-purple; sixth and seventh clusters are yellow-white; 14th, 15th, 16th, and 17th are yellow-orange.
For the petal type features, the image features of tubular petals were the most discriminative; most were clustered in clusters seventh and eighth, while the flat petal, the spoon petal, and the peculiar petal had poor clustering distribution. The spoon petal was the most relaxed.
Principal Components Analysis
Based on the non-pre-training Resnet18, we extracted the image feature of 87 new cultivars from the test dataset in 2019 for PCA. We show the results in Table 3. The interpretation degree of the first principal component (PC1) to the original data is 11.22%, and PC2 to the original data is 9.67%. The first two principal components (PCs) accounted for 20.89% of the total variance, while the first 38 PCs account for approximately 90% of the total variance in the original data.

Table 3. Interpretation of principal component analysis.
The 1,916 image features were visualized on the first two PCs, and colored by flower color (Figures 11C,D), petal type (Figures 11A,B), and flower type (Figures 11E,F), respectively. The image features of white, orange, purple, yellow, and pink large-flowered chrysanthemum cultivars were concentrated. The image features of yellow-green, red, and dark-red large-flowered chrysanthemum cultivars were scattered.
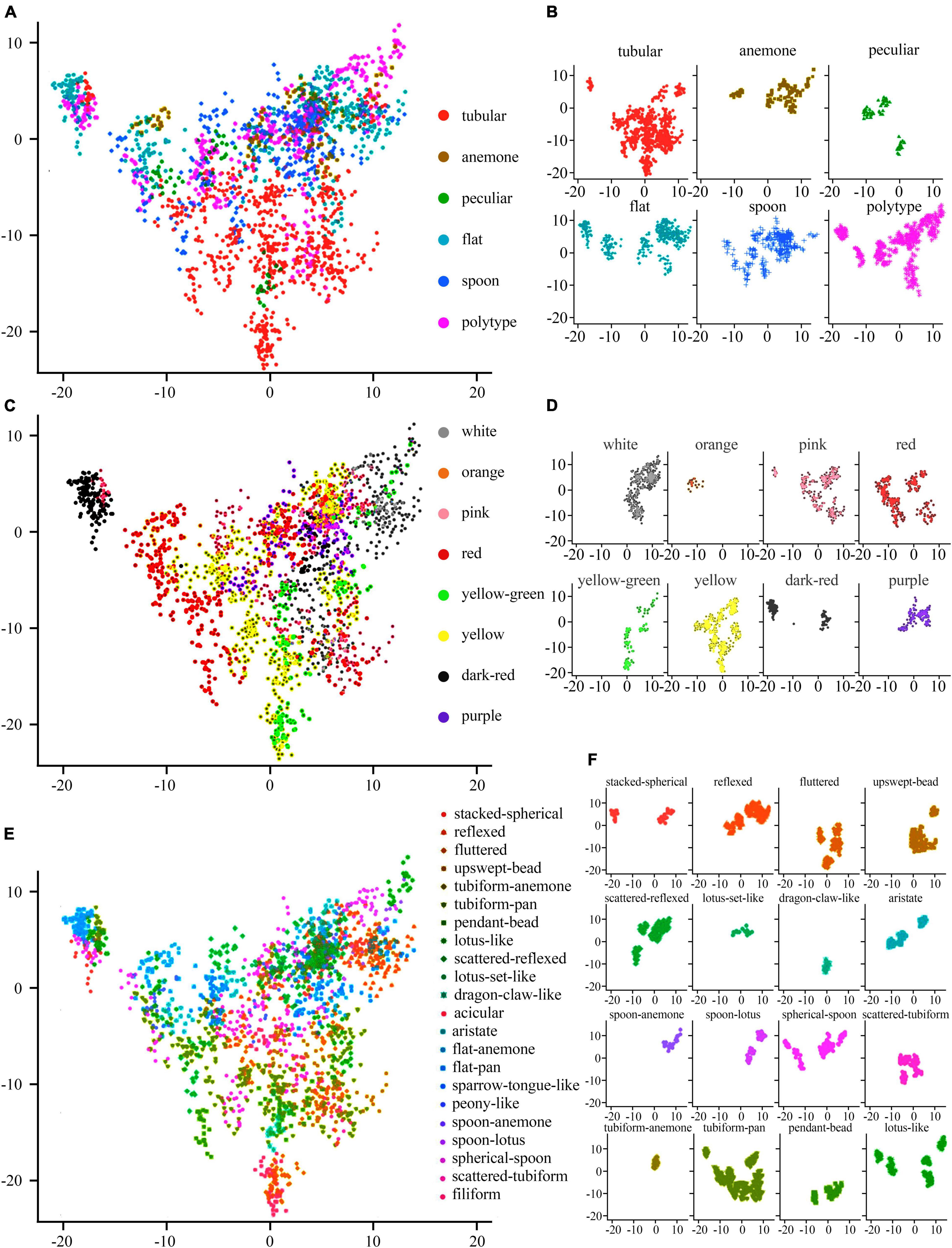
Figure 11. Distribution of various flower colors, petal types, and flower types on the first two PCs. (A,C,E) The comprehensive distribution results of flower colors, petal types, and flower types, respectively. (B,D,F) The individual distribution results of flower colors, petal types, and flower types, respectively.
For the distribution of petal types, we can clearly distinguish the tubular from other petal types on the distribution map (Figure 11A), while other petal types were mixed above the distribution map.
For the flower types (Figures 11E,F), it shows that the first two PCs have a certain explanatory effect on the image characteristic flower types of large-flowered chrysanthemum cultivars. Among flower types, Lotus set like, dragon claw like, and tubiform anemone have the best aggregation. However, some flower types, such as tubiform pan, Lotus like, and spherical spoon, not only have poor aggregation but also have a great overlap with each other.
Discussion
Dynamic Identification of Large-Flowered Chrysanthemum Image
For the 30 same cultivars in 2018 and 2019, the results of the Top-1 and Top-5 were only 32.81% and less than 70%. It was apparent that the vast differences in the images of large-flowered chrysanthemum obtained at different flowering stages directly affected the results of recognition and classification. For some cultivars with low recognition rates, the images obtained in different years have apparent flower color and flower type changes. Sometimes this change shows a comprehensive and complex shift in floral characteristics, but the model lacks sufficient generalization for this circumstance (Figure 12).
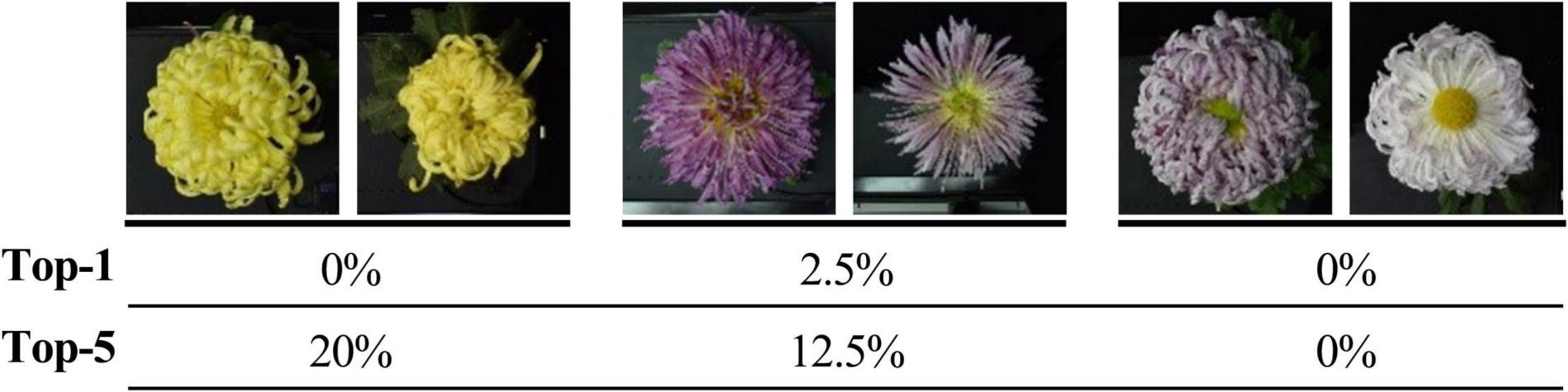
Figure 12. Top-1 and Top-5 identification accuracy of some cultivars. Two adjacent images are the same cultivars from datasets in 2018 and 2019, respectively.
The large-flowered chrysanthemum belonging to the same cultivars may show considerable changes in different developmental stages, nutrient levels, or stress conditions. The single classification network cannot be accurate enough for this dynamic process. In terms of dynamic phenotypic identification, good progress has been made in related studies on leaves. By obtaining leaf images at different growth stages (Zhang et al., 2021) or under different stress conditions (Hao et al., 2020), researchers have established a classification model that can recognize the changing leaves through multi-feature or multi-scale input. However, compared to leaf images, flowers are only available during a short period of the year. Due to being complex 3D objects, there is a considerable number of variations in viewpoint, occlusions, and scale of flower images. In the future, one problem to be solved is establishing a dynamic identification model that can accurately identify the 2D images of large-flowered chrysanthemum in various states.
Deep Features Analysis
It is difficult to interpret the principle of deep network decision-making and analyze the deep features (Castelvecchi, 2016; Lipton, 2018). When the primary purpose is to advance biological research based on accurate prediction, the interpretability of the deep learning model becomes crucial. Whether the classification model of large-flowered chrysanthemum has botanical application value, it needs to analyze whether the classification model is based on the relevant botanical characters and quantify botanical characters’ importance. Liu trained the VGG-16 network with the transfer learning method and extracted 4096-dimensional features, but the clustering results and visual analysis of extracted deep features did not reflect the general distribution rule (Liu et al., 2019). In this paper, the AP clustering and PCA analyzed the 512-dimensional features clustering, and the AP clustering showed that flower color presents high aggregation. For PCA, PC1, and PC2 only account 20.89% of the original data. The image features of chrysanthemum cultivars of each flower color, petal type, and flower type overlap in the first two PCs, and the boundary between different groups is not obvious. It shows that PC1 and PC2 are still not enough to explain the petal type, flower type, and flower color. Further research still needs more principal components.
Conclusion
The results show that the Top-5 accuracy of the ResNet18 non-pre-training model based on the poly-decay strategy is 70.62%. The image processing, model training scheme, and learning rate adjustment method significantly influence the model’s generalization performance. The AP clustering was used to analyze the deep features. The AP clustering result showed that the 126 cultivars in the 2018 dataset were divided into 17 clusters; the flower color and the petal type clustering effect were better than the flower type. Because the structure of the classification network limits the number of categories, it cannot meet the requirement of category increase. In this case, metric learning is a solution.
Data Availability Statement
The raw data supporting the conclusions of this article will be made available by the authors, without undue reservation.
Author Contributions
YT conceived the study. SD completed the work of cultivars’ confirmation, guided sample selection, and cultivation. JW and ZL undertook the cultivation, sample collection, and data labeling of the chrysanthemum. YT and RZ performed the experiments, analyzed the data, and prepared the figures and tables. JW and YKT completed the first draft. SD and YT revised the manuscript. All authors read and approved the final manuscript.
Funding
This study was performed under the National Natural Science Foundation of China (Nos. 31530064 and 31471907), the National Key Research and Development Plan (No. 2018YFD1000405), the Beijing Science and Technology Project (No. Z191100008519002), and the Major Research Achievement Cultivation Project of Beijing Forestry University (No. 2017CGP012).
Conflict of Interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Publisher’s Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
We are particularly indebted to Beijing Dadongliu Nursery for providing test sites. We thank Yushan Ji and Shuo Wang for their guidance on plant material cultivation.
Supplementary Material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2022.806711/full#supplementary-material
Footnotes
- ^ https://www.lilies.org/culture/types-of-lilies
- ^ https://www.rose.org/single-post/rose-classifications
- ^ https://thedaffodilsociety.com/a-guide-to-dafodils/classification-system
- ^ https://americanpeonysociety.org/learn/herbaceous-peonies/flower-types-anatomy
References
Abade, A., Ferreira, P. A., and de Barros Vidal, F. (2021). Plant diseases recognition on images using convolutional neural networks: a systematic review. Comp. Elect. Agricult. 185:6125. doi: 10.1016/j.compag.2021.106125
Chattopadhay, A., Sarkar, A., Howlader, P., and Balasubramanian, V. N. (2018). “Grad-CAM++: Generalized Gradient-Based Visual Explanations for Deep Convolutional Networks,” in 2018 IEEE Winter Conference on Applications of Computer Vision (WACV). (Lake Tahoe, NV).
Dai, S., and Hong, Y. (2017). Chrysanthemum: rich diversity of flower color and full possibilities for flower color modification. Leuven: ISHS, 193–208.
Dai, S., Zhang, L., Luo, X., Bai, X., Xu, Y., and Liu, Q. (2012). Advanced research on chrysanthemum germplasm resources in china. Leuven: ISHS, 347–354.
Frey, B. J., and Dueck, D. (2007). Clustering by passing messages between data points. Science 315, 972–976. doi: 10.1126/science.1136800
Geirhos, R., Rubisch, P., Michaelis, C., Bethge, M., Wichmann, F. A., and Brendel, W. (2018). ImageNet-trained CNNs are biased towards texture; increasing shape bias improves accuracy and robustness. Vienna: ICLR
Hao, X., Jia, J., Gao, W., Guo, X., Zhang, W., Zheng, L., et al. (2020). MFC-CNN: an automatic grading scheme for light stress levels of lettuce (Lactuca sativa L.) leaves. Comp. Elect. Agricult. 179:5847. doi: 10.1016/j.compag.2020.105847
He, K., Zhang, X., Ren, S., and Jian, S. (2015). Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. 2015 IEEE International Conference on Computer Vision (ICCV). Piscataway.
He, K., Zhang, X., Ren, S., and Sun, J. (2016). “Deep residual learning for image recognition,” in Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition (IEEE Computer Society), Piscataway. 770–778.
Hong, Y., Bai, X., Sun, W., Jia, F., and Dai, S. (2012). The numerical classification of chrysanthemum flower color phenotype. Acta Horticult. Sin. 39, 1330–1340.
Jiang, Y., Li, C., Xu, R., Sun, S., Robertson, J. S., and Paterson, A. H. (2020). DeepFlower: a deep learning-based approach to characterize flowering patterns of cotton plants in the field. Plant Methods 16:156. doi: 10.1186/s13007-020-00698-y
Le, N. Q. K., and Huynh, T. T. (2019). Identifying SNAREs by incorporating deep learning architecture and amino acid embedding representation. Front. Physiol. 10:1501. doi: 10.3389/fphys.2019.01501
Lipton, Z. C. (2018). The mythos of model interpretability. Commun. ACM 61, 36–43. doi: 10.1145/3233231
Liu, Z., Wang, J., Tian, Y., and Dai, S. (2019). Deep learning for image-based large-flowered chrysanthemum cultivar recognition. Plant Methods 15:7. doi: 10.1186/s13007-019-0532-7
Mäder, P., Boho, D., Rzanny, M., Seeland, M., Wittich, H. C., Deggelmann, A., et al. (2021). The Flora Incognita app – Interactive plant species identification. Methods Ecol. Evol. 44, 1131–1142. doi: 10.1111/2041-210x.13611
Ni, X., Li, C., Jiang, H., and Takeda, F. (2020). Deep learning image segmentation and extraction of blueberry fruit traits associated with harvestability and yield. Horticult. Res. 7:3. doi: 10.1038/s41438-020-0323-3
Norouzzadeh, M. S., Nguyen, A., Kosmala, M., Swanson, A., Palmer, M. S., Packer, C., et al. (2018). Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Nat. Acad. Sci. 115, E5716–E5725. doi: 10.1073/pnas.1719367115
Rosebrock, A. (2021). Deep Learning for Computer Vision with Python, 3rd Edn. Available at: https://www.kickstarter.com/projects/adrianrosebrock/deep-learning-for-computer-vision-with-python-eboo/description (accessed March 6, 2022).
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNet large scale visual recognition challenge. Int. J. Comp. Vis. 115, 211–252. doi: 10.1007/s11263-015-0816-y
Seeland, M., Rzanny, M., Alaqraa, N., Waldchen, J., and Mader, P. (2017). Plant species classification using flower images-A comparative study of local feature representations. PLoS One 12:e0170629. doi: 10.1371/journal.pone.0170629
Shibata, S., Mizuno, R., and Mineno, H. (2020). Semisupervised deep state-space model for plant growth modeling. Plant Phenom. 2020:4261965. doi: 10.34133/2020/4261965
Simonyan, K., and Zisserman, A. (2015). “Very deep convolutional networks for large-scale image recognition,” in 3rd International Conference on Learning Representations, ICLR. (Vienna: International Conference on Learning Representations, ICLR). doi: 10.3390/s21082852
Song, X., Gao, K., Fan, G., Zhao, X., Liu, Z., and Dai, S. (2018). Quantitative classification of the morphological traits of ray florets in large-flowered chrysanthemum. Hortscience 53, 1258–1265. doi: 10.21273/hortsci13069-18
Song, X., Gao, K., Huang, H., Liu, Z., Dai, S., and Ji, Y. (2021). Quantitative definition and classification of leaves in large- flowered chinese chrysanthemum based on the morphological traits. Chin. Bull. Bot. 56, 10–24. doi: 10.11983/cbb20014
Spiesman, B. J., Gratton, C., Hatfield, R. G., Hsu, W. H., Jepsen, S., McCornack, B., et al. (2021). Assessing the potential for deep learning and computer vision to identify bumble bee species from images. Sci. Rep. 11:1. doi: 10.1038/s41598-021-87210-1
Su, J., Jiang, J., Zhang, F., Liu, Y., Lian, D., Chen, S., et al. (2019). Current achievements and future prospects in the genetic breeding of chrysanthemum: a review. Horticult. Res. 6:8. doi: 10.1038/s41438-019-0193-8
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). “Going deeper with convolutions,” in 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (Boston, MA).
Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., and Wojna, Z. (2016). “Rethinking the Inception Architecture for Computer Vision,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), (Las Vegas, NV).
Tng, S. S., Le, N. Q. K., Yeh, H. Y., and Chua, M. C. H. (2022). Improved prediction model of protein lysine crotonylation sites using bidirectional recurrent neural networks. J. Proteome Res. 21, 265–273. doi: 10.1021/acs.jproteome.1c00848
Ubbens, J. R., and Stavness, I. (2017). Deep plant phenomics: a deep learning platform for complex plant phenotyping tasks. Front. Plant Sci. 8:1190. doi: 10.3389/fpls.2017.01190
Waeldchen, J., and Maeder, P. (2018). Machine learning for image based species identification. Methods Ecol. Evol. 9, 2216–2225. doi: 10.1111/2041-210x.13075
Wang, C., Li, X., Caragea, D., Bheemanahallia, R., and Jagadish, S. V. K. (2020). Root anatomy based on root cross-section image analysis with deep learning. Comp. Elect. Agricult. 175:5549. doi: 10.1016/j.compag.2020.105549
Wldchen, J., and Mder, P. (2018). Plant species identification using computer vision techniques: a systematic literature review. Arch. Comp. Methods Eng. 25, 507–543. doi: 10.1007/s11831-016-9206-z
Yu, D. (1963). Problems on the classification and nomination of garden plants. Acta Horticult. 2, 225–232. doi: 10.1515/9780824839154-014
Yue, J., Li, Z., Zuo, Z., Zhao, Y., Zhang, J., and Wang, Y. (2021). Study on the identification and evaluation of growth years for Paris polyphylla var. yunnanensis using deep learning combined with 2DCOS. Spectrochim. Acta Part A: Mol. Biomol. Spectroscop. 261:120033. doi: 10.1016/j.saa.2021.120033
Zhang, S., and Dai, S. (2013). Chinese chrysanthemum book. Beijing: China Forestry Publishing House.
Zhang, S., Huang, W., Huang, Y., and Zhang, C. (2020). Plant species recognition methods using leaf image: overview. Neurocomputing 408, 246–272. doi: 10.1016/j.neucom.2019.09.113
Zhang, Y., Dai, S., Hong, Y., and Song, X. (2014a). Application of Genomic SSR Locus polymorphisms on the identification and classification of chrysanthemum cultivars in china. Plos One 9:4856. doi: 10.1371/journal.pone.0104856
Zhang, Y., Luo, X., Zhu, J., Wang, C., Hong, Y., Lu, J., et al. (2014b). A classification study for chrysanthemum (Chrysanthemum x grandiflorum Tzvelv.) cultivars based on multivariate statistical analyses. J. Syst. Evol. 52, 612–628. doi: 10.1111/jse.12104
Keywords: large-flowered chrysanthemum, image classification, cultivar recognition, cultivar classification, deep learning
Citation: Wang J, Tian Y, Zhang R, Liu Z, Tian Y and Dai S (2022) Multi-Information Model for Large-Flowered Chrysanthemum Cultivar Recognition and Classification. Front. Plant Sci. 13:806711. doi: 10.3389/fpls.2022.806711
Received: 01 November 2021; Accepted: 16 March 2022;
Published: 06 June 2022.
Edited by:
Valerio Giuffrida, Edinburgh Napier University, United KingdomReviewed by:
Nguyen Quoc Khanh Le, Taipei Medical University, TaiwanDamiano Perri, University of Florence, Italy
Copyright © 2022 Wang, Tian, Zhang, Liu, Tian and Dai. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Ye Tian, dHl0b2VtYWlsQGJqZnUuZWR1LmNu; Silan Dai, c2lsYW5kYWlAc2luYS5jb20=
†These authors have contributed equally to this work and share first authorship