 Mahmood Gholami1*
Mahmood Gholami1* Valentin Wimmer1
Valentin Wimmer1 Carolina Sansaloni2
Carolina Sansaloni2 Cesar Petroli2
Cesar Petroli2 Sarah J. Hearne2,3
Sarah J. Hearne2,3 Giovanny Covarrubias-Pazaran3
Giovanny Covarrubias-Pazaran3 Stefan Rensing4
Stefan Rensing4 Johannes Heise4
Johannes Heise4 Paulino Pérez-Rodríguez5
Paulino Pérez-Rodríguez5 Susanne Dreisigacker6
Susanne Dreisigacker6 José Crossa2,5
José Crossa2,5 Johannes W. R. Martini2*
Johannes W. R. Martini2*- 1KWS SAAT SE & Co. KGaA, Einbeck, Germany
- 2Genetic Resources Program, International Maize and Wheat Improvement Center, Texcoco, Mexico
- 3Excellence in Breeding Platform, Consultative Group for International Agricultural Research, Texcoco, Mexico
- 4IT Solutions for Animal Production (vit - Vereinigte Informationssysteme Tierhaltung w.V.), Verden, Germany
- 5Department of Statistics, Colegio de Postgraduados, Montecillos, Mexico
- 6Global Wheat Program, International Maize and Wheat Improvement Center, Texcoco, Mexico
Introduction
Within the last 20 years, after the landmark paper by Meuwissen et al. (2001), genomic selection (GS) has been widely incorporated in plant and animal breeding (Crossa et al., 2017; Hickey et al., 2017). However, adoption happened at different speeds and with distinct focus.
Here, we give a short description of the history and the current state of GS implementation in German dairy cattle breeding (as an example in animal breeding), at the private plant breeding company KWS SAAT SE & Co. KGaA, and at the public breeding programs of the International Maize and Wheat Improvement Center (CIMMYT) and the Consultative Group for International Agricultural Research (CGIAR) in general. We close by highlighting some differences in organizational structure and objectives of the considered breeding institutions, and comment on how these differences may have influenced the adoption of GS.
Genomic Selection in Dairy Cattle Breeding
Dairy cattle breeding provided good conditions for the introduction of GS. Selection decisions had been based for decades purely on additive genetic effects reflected in a sire's breeding value, and the use of pedigree-based estimated breeding values (PEBVs) had already been common practice. However, reliabilities of early estimated breeding values from information on parents only were low. Therefore, a testing scheme was used, in which bulls were mated to a more or less representative sample of cows in a first step. The resulting daughters were then raised until their performance could be measured, thus improving the reliabilities of their sires' breeding values. Only then, the best test bulls were selected and used broadly. This costly waiting period led to a generation interval of more than five years. Using genomically estimated breeding values (GEBVs) of young bulls, which are more reliable than PEBVs, permitted to reduce this waiting period, and thus to increase selection gain per time. Although the accuracy of the breeding value of a bull which has been extensively progeny tested over years is of higher accuracy than a young bull's GEBV, the costs in terms of waiting time do not pay off for the breeding program, when comparing a more accurate late selection to a less accurate early selection based on the GEBV instead of the PEBV.
With this setup, genomic breeding values for Holsteins and Jerseys were first published in the USA in 2009 (Wiggans et al., 2017), about a decade after the release of the first commercial SNP chip (Wang et al., 1998). In Europe, four breeding organizations (UNCEIA: France; VikingGenetics: Denmark, Finland, and Sweden; DHV-vit: Germany; CRV: The Netherlands, Flanders) joined forces and put a reference population together with 4,000 bulls each (Lund et al., 2011). After 1.5 years of development, from August 2010 onwards, genomic breeding values, based on the joint reference population, were published in these European countries. This rapid evolution was only possible due to a long-established international data infrastructure with Multiple Across Country Evaluations (MACE) being in place since the 1990s at the international evaluation center Interbull. MACE allows the expression and use of estimated breeding values on the scale of each participating country (Schaeffer, 1994). Since 2010, breeding progress has more than doubled for all traits in German Holsteins as seen from Figure 1, mostly due to the sharply decreased generation interval for bulls.
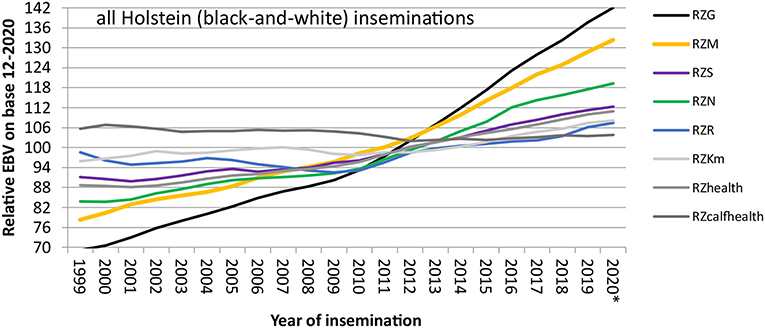
Figure 1. Breeding progress in important traits in German Holsteins, measured as yearly mean EBVs of bulls, weighted by the number of inseminations with their semen. The label “RZ” denotes that all breeding values are standardized to a genetic standard deviation of 12, and a mean of 100 in the female base population (year of birth 2014–2016), all breeding values are expressed such that more positive values are more desirable from the breeder's perspective. RZG, total merit index; RZM, milk production index; RZS, somatic cell score; RZN, longevity; RZR, fertility index; RZKm, index of maternal calving traits; RZhealth, health trait index; RZcalfhealth, calf survival. *Year 2020: incomplete data. Slightly modified from IT Solutions for Animal Production (vit - IT Solutions for Animal Production, 2021).
The initial 50k Illumina SNP set is still the reference SNP set for genomic evaluations at vit in Germany, although dozens of different SNP chips have been integrated since then, especially many low density chips. With dropping genotyping costs and low density 10k SNP chips, female animals came also into the focus. In 2019, cows were integrated in the German reference population. As of the routine genetic evaluation in April 2021, there were 43,699 bulls and 249,363 cows in the reference population for milk traits. Current efforts aim at implementing Single Step methodology (Aguilar et al., 2010) in the genetic evaluation systems of most countries, which is a computationally demanding task with big populations, requiring specialized algorithms (e.g., Liu et al., 2014).
Genomic Selection at KWS
Around 2008, KWS started own research activities in the field of GS and participated in several large collaborations (e.g., Albrecht et al., 2011; Hofheinz et al., 2012). Only a few years later, GS became an established part of the breeder's toolbox for all KWS field crops.
The reason for this rapid adoption of GS is its attractiveness for addressing several components of the breeder's equation simultaneously: Shorten the breeding cycle by replacing phenotypic evaluation steps through a genomic evaluation, increasing accuracy by integrating information from relatives and multiple environments, and increasing selection intensity in case that genotyping is cheaper than phenotyping.
Advances in genome analysis of major crops over the past 15 years led to the availability of a vast number of molecular markers, a pre-requisite for GS application. New genotyping technologies reduced costs of genotyping to a fraction of the costs of phenotyping an individual in field trials.
As a consequence of these developments, GS influenced the design of breeding schemes. With this tool at hand, predictive breeding is used to plan crosses, to reduce breeding cycle length, and to select for more stable performance using multi-year training sets. Genomic prediction is now practiced on many complex traits including yield, quality, biotic, and abiotic stress.
For instance in sugar beet breeding, GS has become an essential component to address the trait “sugar yield,” which is a composite of “sugar content” and “yield.” These two traits are addressed by both (i) within cycle prediction, which allows higher selection intensity and (ii) across cycle prediction, which allows early selection. Predictive ability in each breeding program is constantly monitored. Besides routine application, KWS does very active research to further enhance the efficiency of this tool. Two factors have been the focus of genomic prediction research: chip design and size and composition of training sets. For instance, for sugar beet, we saw that approximately 2,000 markers are sufficient for genomic prediction, potentially due to high linkage disequilibrium in the breeding material. The required training set size is highly dependent of the relationship between training set and prediction set as well as the heritability of the trait. We observe a diminishing return on prediction accuracy for the phenotype of sugar yield when having more than 300 individuals in the training set (which may also be a consequence of the high linkage disequilibrium in breeding populations).
Today, GS has become a routine application in breeding programs at KWS. Thousands of GS analyses are performed every year. Therefore, KWS has optimized genotyping processes and analysis pipelines. With GS being implemented widely in all breeding programs, KWS is extending prediction methods using artificial intelligence and genotype by environment (GxE) interactions.
Genomic Selection at the International Maize and Wheat Improvement Center (CIMMYT)
CIMMYT has started to explore GS more aggressively as a new breeding tool since 2010 (de los Campos et al., 2009; Crossa et al., 2010, 2019; Dreisigacker et al., 2021). The estimation of GEBVs for the germplasm is routinely implemented for the maize and the wheat program, but it is a decision of the respective breeder which weight is given to this information in the selection process. The initial focus of GS application has been on greater selection intensity in stage I yield trials by predicting the GEBVs of germplasm which had not been included in the trials. Recent projects aim to use GS for early selection and to shorten cycle time. Standardized workflows for data storage, processing, and subsequent analyses are currently advanced by the Excellence in Breeding (EiB) platform and various projects at CIMMYT and other CGIAR centers. CIMMYT has also worked on genomic prediction of traits of germplasm bank accessions (Crossa et al., 2016) to explore its potential for harnessing genetic resources (Martini et al., 2021). The center has built the basis for more informed screening of novel allelic diversity in the germplasm collection by genotyping a substantial part of the available accessions (Sansaloni et al., 2020).
The question which impact GS had on the annual genetic gain for yield across breeding pipelines is more difficult to answer than for the dairy cattle example presented above. Estimates of genetic gain vary and GS has been used to different extend across breeding pipelines. Since programs introduced GS gradually, it is difficult to separate a potential increase in genetic gain due to the use of GS, from other aspects which may have improved the breeding pipelines. A recent publication by Gerard et al. (2020) reports estimated yearly selection gains of 0.93% for low-rainfall environments and 3.8% for high-rainfall environments for the period of 2007–2016 for grain yield in wheat. However, we cannot clearly attribute the credit of this selection gain to GS, since this period is too short after GS has been implemented. However, several dedicated experiments in maize outlined the potential of GS. For instance, Beyene et al. (2015) used GS to select from bi-parental maize populations for yield under drought stress and reported a higher selection gain than for conventional breeding methods. Comparing to previous studies, the authors concluded that “the average gain observed under drought in our study using GS was two- to fourfolds higher than what has been reported from conventional phenotypic selection under drought stress.” Moreover, CIMMYT's Global Maize Program designed a rapid cycle genomic selection (RCGS) of multi-parental crosses (Zhang et al., 2017). Two cycles per year were performed, and the authors found that “the genetic gains from the RCGS […] are at the same or higher level than those observed in other studies under phenotypic selection […].” Also, Beyene et al. (2019) compared selection gain of phenotypic selection (PS) and GS for two different environments (well-watered and water stressed) and observed a higher selection gain for PS for well-watered conditions, and a higher selection gain for GS under water stress. The authors highlighted that GS provides “the potential to bypass stage I trial evaluation and move material directly into stage II” which “would reduce both the costs and cycle time but will require accurate predictions from training sets composed of historical data” (Beyene et al., 2019). This potential to reduce cycle time has not yet been included in the study.
Implementation of Genomic Selection CGIAR-Wide
The CGIAR has entered a phase of pushing the application of GS for all crops, from maize to bananas (Nyine et al., 2017; Wolfe et al., 2017; Ahmadi et al., 2020; Gemenet et al., 2020; Atanda et al., 2021). The EiB platform provides technical assistance and practical guidelines for the implementation of GS and the modernization of breeding programs (see for instance Covarrubias-Pazaran et al., 2021). Before EiB, several initiatives advanced the use of GS in specific crops. For example, the NextGen Cassava project took important steps toward the successful implementation of GS for root, tuber, and banana (RTB) crops (Wolfe et al., 2017; Maxmen, 2019). Those steps included the development of a robust database system, matching the genotyping logistics with the growing season, and automating analytical pipelines. Similar steps have been taken by initiatives at IRRI and CIMMYT (Crossa et al., 2017; Gao et al., 2020).
Crops currently using GS to reduce cycle time are cassava and maize (Atanda et al., 2021; Esuma et al., 2021). Genomic selection is being used to increase selection intensity in cassava, maize, rice, and wheat (Ahmadi et al., 2020; Dreisigacker et al., 2021). Finally, GS is used for increasing the selection accuracy of yield trials by all the aforementioned and yams (Agre et al., 2018). Other crops, including beans, pulses, forages, bananas, and potato are developing and validating the necessary logistics and tools to manage the data, genotyping, analytical pipelines, and costs. This picture is rapidly changing since the ambition of all breeding programs in the CGIAR is to use genome-assisted prediction methodologies to reduce the length of the breeding cycle to 2–3 years.
Conclusion
Dairy Cattle Breeding Compared to Plant Breeding
Genomic selection was adopted in dairy cattle breeding almost instantly after genotyping costs dropped below the anticipated break-even point, presumably because the routine use of pedigree-based predictions, and a culture of centrally processing data of fragmented production units, had already been established (Schaeffer, 1994; Wiggans et al., 2017).
In contrast, plant breeding programs are traditionally dedicated to more specific geographical regions aiming to adapt the germplasm to certain environmental conditions, and the data used for selection decisions have almost exclusively focused on the most recent trials of the respective program. An overarching approach for handling data across programs or selection cycles had not been necessary. Moreover, pedigree information had hardly been used for pedigree-based predictions, since the pedigree information has often been incomplete and “relatively wide” crosses of unrelated material have been used (Dreisigacker et al., 2021). Moreover, a PEBV may not provide additional information, since it cannot capture the segregation within a family generated by a certain cross.
Also, plant breeders traditionally tend to focus on product development that is on identifying varieties, rather than on population improvement, that is identifying parents for new crosses. In other words, breeders are more interested in the genotypic value comprising the complete genetic contribution to the phenotype than in the additive genetic value (the breeding value). A focus on the latter is natural in dairy breeding, where the sire's breeding value is defined indirectly by the performance of its offspring, not by its own phenotype (Mrode, 2014).
Only in recent years some concepts from animal breeding, such as the focus on the breeding value, have been transferred in more formal and more rigorous ways to plant breeding. An example is the separation of population improvement from product development (Gaynor et al., 2017) which allows to focus on the breeding value for the population improvement step. The impact of this paradigm shift on genetic gain is to be observed in coming decade(s).
Public Compared to Private Plant Breeding
In general, the timelines for the exploration of the potential of GS were relatively similar between the considered public and private plant breeding organizations. CIMMYT and the CGIAR are public research organizations that also pursue the publication of novel, creative approaches, and follow in parts a (research) project-based organization. In contrast, private institutions naturally tend to focus more on the standardization and optimization of routine processes for GS, which may have had a lower priority in the public sector. The EiB platform and associated projects are currently addressing a stronger standardization of data storage and related analysis pipelines. Moreover, the project-based organization in public institutions comes with a variance in funding which leads to challenges for mid to long-term planning on the use of GS.
Finally, CGIAR centers are plant improvement-breeding centers that focus on delivering germplasm to National Agricultural Research institutions (NARs), in particular in Africa and Asia. This implies other priorities for traits, different frameworks for the evaluation of material, and different cost structures compared to, for instance, a commercial program in North America. The economics of implementing GS may therefore differ from those at private companies.
Overall, we think that the advent of GS has provided a tipping point to catalyze the ongoing reform of plant breeding institutions to data processing focused organizations. This transformation will leverage both the historic data resources amassed and the data generated annually to more effectively drive breeding decisions. However, with the increasing number of phenotypic records, and genotypic and environmental information, we now face the challenge of how to use “big data” most efficiently.
Author Contributions
MG and VW wrote the section about GS at KWS SAAT SE & Co. KGaA. CS, CP, SJH, SD, PP-R, JC, and JM wrote the section on GS at CIMMYT. GC-P wrote the section about CGIAR-wide implementation of GS. Authors from vit (SR and JH) wrote the section about GS in dairy cattle breeding. All authors contributed to the conclusion. MG and JM organized the joint effort.
Conflict of Interest
MG and VW are employed by the company KWS SAAT SE & Co. KGaA. Moreover, JH and SR are employed by IT Solutions for Animal Production (vit).
The remaining authors declare that the research was conducted in the absence of any commercial or financial interest that could be construed as potentially conflicting with the research.
Publisher's Note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Acknowledgments
The authors affiliated to CIMMYT and EiB thank the Bill and Melinda Gates Foundation for financial support for increasing genetic gains [INV-003439 BMGF/FCDO Accelerating Genetic Gains in Maize and Wheat for Improved Livelihoods (AGG)] as well as USAID projects [Amend. No. 9 MTO 069033, USAID-CIMMYT Wheat/AGGMW, AGG-Maize Supplementary Project, AGG (Stress Tolerant Maize for Africa)]. We are also thankful for the financial support provided by the Foundations for Research Levy on Agricultural Products (F.F.L.) and the Agricultural Agreement Research Fund (J.A.) in Norway through NFR grant 267806, the CIMMYT CRP-WHEAT and the USDA National Institute of Food and Agriculture Grant Nos. 2020-67013-30904 and 2018-67015-27957 to DER and Hatch project 1010469.
References
Agre, A. P., Beauchet, G., Dekoyer, D., Yusuf, M., Gisel, A., Abberton, M., et al. (2018). “Designing SNP-array for guinea yams (Dioscorea spp.) for routine use in breeding program,” in Plant and Animal Genome XXVI Conference (San Diego, CA).
Aguilar, I., Misztal, I., Johnson, D. L., Legarra, A., Tsuruta, S., and Lawlor, T. J. (2010). Hot topic: a unified approach to utilize phenotypic, full pedigree, and genomic information for genetic evaluation of Holstein final score. J. Dairy Sci. 93, 743–752. doi: 10.3168/jds.2009-2730
Ahmadi, N., Bartholomé, J., Tuong-Vi, C., and Grenier, C. (2020). “Genomic selection in rice: empirical results and implications for breeding,” Quantitative Genetics, Genomics and Plant Breeding, 2nd Edn., ed M. Kang (Wallingford; Oxon: CABI Publishing), 243–258. doi: 10.1079/9781789240214.0243
Albrecht, T., Wimmer, V., Auinger, H. J., Erbe, M., Knaak, C., Ouzunova, M., et al. (2011). Genome-based prediction of testcross values in maize. Theor. Appl. Genet. 123, 339–350. doi: 10.1007/s00122-011-1587-7
Atanda, S. A., Olsen, M., Burgueño, J., Crossa, J., Dzidzienyo, D., Beyene, Y., et al. (2021). Maximizing efficiency of genomic selection in CIMMYT's tropical maize breeding program. Theor. Appl. Genet. 134, 279–294. doi: 10.1007/s00122-020-03696-9
Beyene, Y., Gowda, M., Olsen, M., Robbins, K. R., Pérez-Rodríguez, P., Alvarado, G., et al. (2019). Empirical comparison of tropical maize hybrids selected through genomic and phenotypic selections. Front. Plant Sci. 10:1502. doi: 10.3389/fpls.2019.01502
Beyene, Y., Semagn, K., Mugo, S., Tarekegne, A., Babu, R., Meisel, B., et al. (2015). Genetic gains in grain yield through genomic selection in eight bi-parental maize populations under drought stress. Crop Sci. 55, 154–163. doi: 10.2135/cropsci2014.07.0460
Covarrubias-Pazaran, G., Martini, J. W. R., Quinn, M., and Atlin, G. (2021). Strengthening public breeding pipelines by emphasizing quantitative genetics principles and open source data management. Front. Plant Sci. 12:681624. doi: 10.3389/fpls.2021.681624
Crossa, J., de los Campos, G., Pérez, P., Gianola, D., Burgueño, J., Araus, J. L., et al. (2010). Prediction of genetic values of quantitative traits in plant breeding using pedigree and molecular markers. Genetics 186, 713–724. doi: 10.1534/genetics.110.118521
Crossa, J., Jarquín, D., Franco, J., Pérez-Rodríguez, P., Burgueño, J., Saint-Pierre, C., et al. (2016). Genomic prediction of gene bank wheat landraces. G3 (Bethesda). 6, 1819–1834. doi: 10.1534/g3.116.029637
Crossa, J., Martini, J. W. R., Gianola, D., Pérez-Rodríguez, P., Jarquín, D., Juliana, P., et al. (2019). Deep kernel and deep learning for genome-based prediction of single traits in multienvironment breeding trials. Front. Genet. 10:1168. doi: 10.3389/fgene.2019.01168
Crossa, J., Pérez-Rodríguez, P., Cuevas, J., Montesinos-López, O., Jarquín, D., de los Campos, G., et al. (2017). Genomic selection in plant breeding: methods, models, and perspectives. Trends Plant Sci. 22, 961–975. doi: 10.1016/j.tplants.2017.08.011
de los Campos, G., Naya, H., Gianola, D., Crossa, J., Legarra, A., Manfredi, E., et al. (2009). Predicting quantitative traits with regression models for dense molecular markers and pedigree. Genetics 182, 375–385. doi: 10.1534/genetics.109.101501
Dreisigacker, S., Crossa, J., Pérez-Rodríguez, P., Montesinos-López, O. A., Rosyara, U., Juliana, P., et al. (2021). Implementation of genomic selection in the CIMMYT global wheat program, findings from the past 10 years. Crop Breed. Genet. Genom. 3:e210005. doi: 10.20900/cbgg20210005
Esuma, W., Ozimati, A., Kulakow, P., Gore, M. A., Wolfe, M. D., Nuwamanya, E., et al. (2021). Effectiveness of genomic selection for improving provitamin A carotenoid content and associated traits in cassava. G3 (Bethesda). 11:jkab160. doi: 10.1093/g3journal/jkab160
Gao, S. Y., Hagen, T. J., Robbins, K., Jones, E., Karkkainen, M., Dreher, K. A., et al. (2020). “Transforming breeding through enterprise breeding system and analytics,” in Plant and Animal Genome XXVIII Conference (San Diego, CA).
Gaynor, R. C., Gorjanc, G., Bentley, A. R., Ober, E. S., Howell, P., Jackson, R., et al. (2017). A two-part strategy for using genomic selection to develop inbred lines. Crop Sci. 57, 2372–2386. doi: 10.2135/cropsci2016.09.0742
Gemenet, D. C., da Silva Pereira, G., De Boeck, B., Wood, J. C., Mollinari, M., Olukolu, B. A., et al. (2020). Quantitative trait loci and differential gene expression analyses reveal the genetic basis for negatively associated β-carotene and starch content in hexaploid sweetpotato [Ipomoea batatas (L.) Lam.]. Theor. Appl. Genet. 133, 23–36. doi: 10.1007/s00122-019-03437-7
Gerard, G. S., Crespo-Herrera, L. A., Crossa, J., Mondal, S., Velu, G., Juliana, P., et al. (2020). Grain yield genetic gains and changes in physiological related traits for CIMMYT's high rainfall wheat screening nursery tested across international environments. Field Crops Res. 249:107742. doi: 10.1016/j.fcr.2020.107742
Hickey, J. M., Chiurugwi, T., Mackay, I., Powell, W., Eggen, A., Kilian, A., et al. (2017). Genomic prediction unifies animal and plant breeding programs to form platforms for biological discovery. Nat. Genet. 49:1297. doi: 10.1038/ng.3920
Hofheinz, N., Borchardt, D., Weissleder, K., and Frisch, M. (2012). Genome-based prediction of test cross performance in two subsequent breeding cycles. Theor. Appl. Genet. 125, 1639–1645. doi: 10.1007/s00122-012-1940-5
Liu, Z., Goddard, M. E., Reinhardt, F., and Reents, R. (2014). A single-step genomic model with direct estimation of marker effects. J. Dairy Sci. 97, 5833–5850. doi: 10.3168/jds.2014-7924
Lund, M. S., Roos, A. P., Vries, A. G., Druet, T., Ducrocq, V., Fritz, S., et al. (2011). A common reference population from four European Holstein populations increases reliability of genomic predictions. Genet. Sel. Evol. 43:43. doi: 10.1186/1297-9686-43-43
Martini, J. W. R., Molnar, T. L., Hearne, S., Crossa, J., and Pixley, K. V. (2021). Opportunities and challenges of predictive approaches for harnessing the potential of genetic resources. Front. Plant Sci. 12:674036. doi: 10.3389/fpls.2021.674036
Maxmen, A. (2019). How African scientists are improving cassava to help feed the world. Nature 565, 144–147. doi: 10.1038/d41586-019-00014-2
Meuwissen, T. H. E., Hayes, B. J., and Goddard, M. E. (2001). Prediction of total genetic value using genome-wide dense marker maps. Genetics 157, 1819–1829. doi: 10.1093/genetics/157.4.1819
Mrode, R. A. (2014). Linear Models for the Prediction of Animal Breeding Values. Oxfordshire: CABI. doi: 10.1079/9781780643915.0000
Nyine, M., Uwimana, B., Swennen, R., Batte, M., Brown, A., Christelová, P., et al. (2017). Trait variation and genetic diversity in a banana genomic selection training population. PLoS ONE 12:e0178734. doi: 10.1371/journal.pone.0178734
Sansaloni, C., Franco, J., Santos, B., Percival-Alwyn, L., Singh, S., Petroli, C., et al. (2020). Diversity analysis of 80,000 wheat accessions reveals consequences and opportunities of selection footprints. Nat. Commun. 11, 1–12. doi: 10.1038/s41467-020-18404-w
Schaeffer, L. (1994). Multiple-country comparison of dairy sires. J. Dairy Sci. 77, 2671–2678. doi: 10.3168/jds.S0022-0302(94)77209-X
vit - IT Solutions for Animal Production (2021). Geschäftsbericht 2020/21. Available online at: https://www.vit.de/fileadmin/Wir-sind-vit/Geschaeftsberichte/vit_GB_2020_2021.pdf (accessed October 13, 2021).
Wang, D. G., Fan, J. B., Siao, C. J., Berno, A., Young, P., Sapolsky, R., et al. (1998). Large-scale identification. mapping, and genotyping of single-nucleotide polymorphisms in the human genome. Science 280, 1077–1082. doi: 10.1126/science.280.5366.1077
Wiggans, G. R., Cole, J. B., Hubbard, S. M., and Sonstegard, T. S. (2017). Genomic selection in dairy cattle: the USDA experience. Annu. Rev. Anim. Biosci. 5, 309–327. doi: 10.1146/annurev-animal-021815-111422
Wolfe, M. D., Del Carpio, D. P., Alabi, O., Ezenwaka, L. C., Ikeogu, U. N., Kayondo, I. S., et al. (2017). Prospects for genomic selection in cassava breeding. Plant Genome 10. doi: 10.3835/plantgenome2017.03.0015
Keywords: genomic selection, breeding, plant breeding, animal breeding, dairy breeding, selection gain
Citation: Gholami M, Wimmer V, Sansaloni C, Petroli C, Hearne SJ, Covarrubias-Pazaran G, Rensing S, Heise J, Pérez-Rodríguez P, Dreisigacker S, Crossa J and Martini JWR (2021) A Comparison of the Adoption of Genomic Selection Across Different Breeding Institutions. Front. Plant Sci. 12:728567. doi: 10.3389/fpls.2021.728567
Received: 21 June 2021; Accepted: 30 September 2021;
Published: 19 November 2021.
Edited by:
Lee Hickey, The University of Queensland, AustraliaReviewed by:
Owen Powell, University of Queensland, AustraliaGregor Gorjanc, University of Edinburgh, United Kingdom
Copyright © 2021 Gholami, Wimmer, Sansaloni, Petroli, Hearne, Covarrubias-Pazaran, Rensing, Heise, Pérez-Rodríguez, Dreisigacker, Crossa and Martini. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Mahmood Gholami, Z2hvbGFtaS5tYWhtb3VkQGdtYWlsLmNvbQ==; Johannes W. R. Martini, andybWFydGluaUBnbWFpbC5jb20=