 Jiqing Li
Jiqing Li Zhendong Yin*†
Zhendong Yin*† Dasen Li
Dasen Li- School of Electronics and Information Engineering, Harbin Institute of Technology, Harbin, China
The temporal and spatial irregularity of plant diseases results in insufficient image data for certain diseases, challenging traditional deep learning methods that rely on large amounts of manually annotated data for training. Few-shot learning has emerged as an effective solution to this problem. This paper proposes a method based on the Feature Adaptation Score (FAS) metric, which calculates the FAS for each feature layer in the Swin-TransformerV2 structure. By leveraging the strict positive correlation between FAS scores and test accuracy, we can identify the Swin-Transformer V2-F6 network structure suitable for few-shot plant disease classification without training the network. Furthermore, based on this network structure, we designed the Plant Disease Feature Calibration (PDFC) algorithm, which uses extracted features from the PlantVillage dataset to calibrate features from other datasets. Experiments demonstrate that the combination of the Swin-Transformer V2F6 network structure and the PDFC algorithm significantly improves the accuracy of few-shot plant disease classification, surpassing existing state-of-the-art models. Our research provides an efficient and accurate solution for few-shot plant disease classification, offering significant practical value.
1 Introduction
UNDER the rapid development of hardware and information technology, deep learning has gradually become the mainstream method in the field of image classification. In conventional deep learning image classification processes, a large number of images are required to train the model, allowing it to learn and remember the common features of the same category in the image classification task. This enables the model to exhibit remarkable performance during the testing phase. With the advancement of IoT technology, an increasing number of terminal devices in various fields are beginning to acquire massive amounts of images, prompting attempts to use deep learning for specific image classification tasks, such as plant disease classification (Khan et al., 2022a; Khan et al., 2022b; Bashir et al., 2023; Vishnoi et al., 2023). In this field, numerous studies (Afifi et al., 2020; Argüeso et al., 2020; Figueroa-Mata and Mata-Montero, 2020; Karami et al., 2020; Egusquiza et al., 2022) have confirmed the feasibility of using deep learning techniques for plant disease classification. However, in practical applications, due to the irregularities in time and space of crop disease occurrences, edge devices often struggle to obtain sufficient data on rare plant diseases. Researchers define this challenge as a few-shot classification task in the field of plant disease. The biggest challenge of this task is how to effectively extract crucial classification information from small sample sets of disease data.
Recent work has primarily focused on improving and innovating models for few-shot tasks through three main directions: similarity-based learning, data augmentation, and parameter optimization (de Andrade Porto et al., 2023). The improvements in similarity-based learning methods mainly rely on classifying by comparing the distance measures between the support set and the query set, which are generally obtained through feature extractors. Feature extractors can include commonly used networks such as ResNet (He et al., 2015), VGG (Simonyan and Zisserman, 2014), DenseNet (Huang et al., 2016), MobileNet (Howard et al., 2017), ViT (Dosovitskiy et al., 2020), Swin-TransformerV2 (Liu et al., 2021), etc. Egusquiza et al. (2022) used a ResNet network for feature extraction of disease images and then classified each extracted feature vector using a KNN classifier under the Siamese Network architecture (Chopra et al., 2005). Figueroa-Mata and Mata-Montero (2020) combined Siamese Network and CNN into a single network structure, proposing a Convolutional Siamese Network (CSN) that achieved 96% classification accuracy for crop species under few-shot conditions. Liang (2021) used DenseNet as a feature extractor and applied a Support Vector Machine (SVM) for metric classification, achieving 85.3% classification accuracy for 40 types of cotton diseases in a fewshot classification task. Nuthalapati and Tunga (2021) used Transformer to extract features and achieved an 89.4% classification accuracy for plant diseases in PlantVillage. Zhang et al. (2021) innovatively proposed the Simple Linear Image Clustering (SLIC) method, verified its performance on general datasets like Omniglot and mini-ImageNet, and demonstrated its superiority using aerial images of Pepper Plants. The data augmentation-based method primarily aims to expand the small sample data set. Scarce sample data can affect the construction of models with generalization capabilities. To address this deficiency, Riou et al. (2020) improved recognition performance on the cucumber dataset by changing the background, adjusting the lighting, and modifying the contrast of the images. Nesteruk et al. (2021) expanded the training set through basic image processing techniques such as noise addition, rotation, cropping, flipping, scaling, and image occlusion to achieve data augmentation. Another approach to image enhancement is using Generative Adversarial Networks (GANs) (Goodfellow et al., 2014) to generate large quantities of images. Khanzhina et al. (2021) used three of the most popular GAN networks to establish a pollen grain library, training and inferring according to the Siamese Network workflow. The main objective of parameter optimization-based methods is to prevent network overfitting. When the sample size per category is too small (usually less than 1000 per category), the learned parameters cannot guarantee strong generalization capabilities. Therefore, many scholars have proposed various parameter optimization techniques to ensure the learning ability of the network. Karami et al. (2020) used a modified CenterNet structure for automatic plant counting in aerial images and achieved certain performance improvements in the few-shot field. Wang et al. (2022) based on Model-Agnostic Meta-Learning (MAML) (Finn et al., 2017), determined the optimal values to use at the beginning of the training process to solve the problem of estimating vegetation density in ecological irrigation areas using aerial images.
Regarding the depth of the network, He et al. (2015) utilized a residual structure, achieving the design of a 152-layer network for the first time that could be successfully trained and inferred. The conclusions of the paper suggest that the greater the depth of the network, the higher the accuracy in image classification tasks. This also prompts us to consider whether this conclusion is universally valid for specific fewshot classification networks, and whether there is a clear metric that can quantitatively explore the impact of network depth on the performance of specific few-shot classification networks. Through extensive experiments across different datasets, we found that the last layer of features before the fully connected layer, commonly used for few-shot classification, does not enable subsequent plant disease few-shot classification tasks to achieve optimal performance. Based on this important discovery, we propose the Feature Adaptation Score (FAS) for plant disease few-shot tasks, an indicator that allows us to determine which layer of the network can perform best without testing, thus identifying outstanding network structures.
Inspired by Yang et al. (2021), we designed a plant disease feature calibration algorithm (PDFC) that can utilize features extracted from the PlantVillage dataset to calibrate features from other datasets. Unlike the method proposed by Yang, which requires simulating the distribution of meta-data and training a specialized network for classification, this paper adopts a non-parametric and training-free approach for calibration, significantly improving efficiency over the original method. Our innovations can be summarized in three points:
• We proposed a feature layer evaluation metric, Feature Adaptation Score (FAS), for plant disease few-shot tasks. Without network training, we identified the high-performance network structure Swin-Transformer V2 F6 from the backbone of Swin-Transformer V2, suitable for few-shot plant disease classification.
• Based on the new network structure mentioned above, we further proposed a few-shot plant disease feature calibration (PDFC) algorithm, suitable for the plant disease domain. This algorithm uses a small storage of feature vectors to calibrate the feature space of the target dataset, which can be combined with Swin-Transformer V2 F6 for further performance improvement.
• The effective combination of the network structure and the algorithm enables us to achieve high performance without compromising the accuracy of few-shot classification, even skipping the training phase. We validated our model and algorithm across various datasets, surpassing the performance of contemporary few-shot plant disease classification network models and achieving state-of-the-art (SOTA) results.
2 Materials and methods
2.1 Pipeline of few-shot learning
Few-shot learning (FSL) aims to classify new classes with only a few training examples per class. This capability is crucial for tasks such as plant disease classification, where obtaining large labeled datasets is challenging. In this section, we describe the pipeline for applying few-shot learning to plant disease few-shot classification. Each step is detailed below.
2.1.1 Data preparation
Given dataset , where xi represents an image and is the corresponding label, we split the dataset into base classes and novel classes . The base classes are used to train the feature extractor, while the novel classes are used for few-shot evaluation.
2.1.2 Metric learning
Metric learning is a key component in few-shot learning. The goal of metric learning is to learn an embedding space where samples from the same class are close to each other, and samples from different classes are far apart. This is typically achieved by training a feature extractor fθ and a distance metric d(·,·).
2.1.3 Embedding space
Given an input image x, the feature extractor fθ maps it to an embedding vector z = fθ(x), where and d is the dimensionality of the embedding space. The objective is to ensure that in this embedding space, the distance between embeddings of the same class is minimized, while the distance between embeddings of different classes is maximized.
2.1.4 Distance metric
A commonly used distance metric is the L2 norm, also known as the Euclidean distance, defined as shown in Equation 1:
where zi and zj are the embedding vectors of images xi and xj, respectively. Other distance metrics, such as cosine similarity, as shown in Equation 2: can also be used:
2.1.5 Prototypical networks
In the context of few-shot learning, Prototypical Networks (Snell et al., 2017) are a popular approach. For each class k, a prototype vector ck is computed as the mean of the support set embeddings for that class as shown in Equation 3:
where Sk is the set of support examples for class k. During inference, a query image xq is classified based on its distance to each class prototype, as shown in Equation 4:
2.1.6 Loss function
A commonly used loss in metric learning is the triplet loss. It aims to minimize the distance between an anchor xa and a positive sample xp (same class) and maximize the distance between the anchor and a negative sample xn (different class). The triplet loss is defined as shown in Equation 5:
where α is a margin parameter that ensures a minimum difference between positive and negative pairs. Contrastive loss is another commonly loss used in metric learning. It operates on pairs of samples and tries to minimize the distance between similar pairs and maximize the distance between dissimilar pairs. The loss is defined as shown in Equation 6:
where if xi and xj are from the same class, otherwise, and m is a margin parameter.
2.1.7 Training procedure
The training procedure for metric learning involves sampling batches of images and their corresponding labels, computing the embeddings using fθ, and then calculating the chosen loss function (e.g., triplet loss or contrastive loss). The model parameters θ are updated using gradient descent to minimize the loss, as shown in Equation 7:
where η is the learning rate.
2.1.8 Evaluation
The classic few-shot classification task follows the N-way-K-shot paradigm, where there are N classes, each with K samples. The dataset can also be represented as Equation 8
where denotes the j-th sample of the i-th class, and is the corresponding label.
For evaluation, we use standard few-shot learning metrics, such as 5-way-1-shot, 5-way-5-shot, and 5-way-10-shot classification accuracy. In an N-way-K-shot task, we randomly sample N classes from the novel classes and provide K examples per class for training. The model is then evaluated on query images from these N classes.
The classification accuracy Acc is calculated as Equation 9
where Q is the query images, is the predicted label, and yi is the true label.
2.2 Design of STV2F6 for plant disease few-shot classification
Assume a model can be divided into L layers according to its depth. When an input image xi,j is fed into the model, the feature vector output from the l-th layer is denoted as ϕl(xi,j), where .
We aim to design a versatile few-shot classification network that can effectively adapt to the characteristics of various plant disease datasets, thereby achieving efficient domain generalization capability. We ultimately chose the Swin-Transformer V2 network as our starting point for two reasons. First, this network architecture achieved the best performance on ImageNet (Krizhevsky et al., 2012) in 2022 and demonstrated remarkable capabilities across various datasets. Additionally, the network has been integrated into versions of Pytorch 1.13 and later, allowing for direct training and inference, which reduces the cost and potential for errors in reproduction. According to the design of general vision classification models, the last layer (the Lth layer) is usually a fully connected layer. In this part, we first investigate whether the features from the penultimate layer, often used in few-shot classification, i.e., the output of the (L − 1)-th layer , are suitable for few-shot classification in the domain of plant disease detection.
To evaluate the Feature Adaptation Score (FAS) FASl of the feature vector at the l-th layer in few-shot disease classification, we first define three parameters: the withinclass variance , the between-class variance , and the average between-class distance . To derive these three parameters, we first need to calculate the mean feature vector of the samples of class i at the l-th layer, µi,l, and the mean feature vector of all classes at the l-th layer, µl. The expressions are shown in Equations 10, 11.
Based on the above discussion, we derived the expressions for the three key parameters, which are defined in Equations 12-14.
Each dimension of the feature vector in each layer is a linear combination of the activations of many neurons, and the value of the neurons in the l-th layer, before activation, is a linear combination of the activations of multiple neurons from the (l − 1)-th layer. Therefore, if we assume that the value of each neuron in the first layer, before the RELU activation, follows a normal distribution, then after the RELU activation, the neuron’s value follows a right-truncated normal distribution. Moreover, assuming that the number of neurons in each layer of the Swin-Transformer V2 exceeds 30, according to the Central Limit Theorem, the feature vector (before activation) in each layer follows a multivariate normal distribution. Furthermore, based on the property of linear combinations of normal distributions, and according to Equations 10, 11, and also follow a multivariate normal distribution, thus we have Equation 15:
According to the definition of the chi-square distribution, we can directly conclude that and follow a non-central chi-square distribution, which can be expressed as Equation 16:
Consider the variable , where and are each multivariate normal variables. Specifically, and . The difference between any two feature vectors, and , is given by the difference vector . Since both and are multivariate normal, the difference vector z follows a multivariate normal distribution, which is shown in Equation 17:
The squared Euclidean distance between these vectors is the squared norm of z, given by Equation 18:
Since z follows a multivariate normal distribution, the squared distance follows a non-central chi-square distribution, which is shown in Equation 19:
where is the non-centrality parameter, given by Equation 20:
The Euclidean distance itself is the square root of this squared distance, so the Euclidean distance between and follows the square root of a non-central chi-square distribution, as shown in Equation 21:
Since the dimension directly affects the mean and variance of the non-central chi-square distribution, if a comparison is to be made, the feature vector in each layer needs to be scaled by its dimension so that the feature vectors of all layers are compared on the same scale. After performing the dimensional scaling, we can define FASl,
We will explain why FASl takes the form of Equation 22. First, we discuss why the scaling factors of the three parameters are not exactly the same. The first two variables, and , represent the variance of the means. According to the law of large numbers, the variance of the sample mean is the original variance divided by the sample size n, meaning the variance of the mean decreases as the sample size n increases. This is why the first two variables use ; they reflect the influence of sample size on the variance of the mean. The last variable, , represents the average Euclidean distance between sample pairs, which involves averaging the distances between multiple sample pairs. Since the standard error of the mean is the sample standard deviation σ divided by , we use for the last term to account for the influence of the standard error. As the sample size n increases, the estimation of the mean becomes more precise, which is why we adjust the variance using . In summary, the first two terms use , while the third term uses , allowing the three different variables to have values on the same scale, thereby making the calculation of FASl more stable.
Another aspect we need to further clarify is why the two terms in FASl are combined using addition rather than multiplication. This is primarily because these two terms measure different statistics and do not have a direct dependency or interaction. The first term, , reflects the relative dispersion between and within the feature distributions, measuring the ratio of differences between categories to differences within the same category, describing the spread of the data. The second term, , reflects the precision of the sample mean, specifically the average Euclidean distance between sample pairs divided by , meaning that as the sample size increases, the estimation of the mean becomes more precise. Since these two measures independently reflect different aspects of the data, there is no direct interaction between them, and addition is used to accumulate their effects instead of multiplication. Addition is more natural and appropriate because it effectively combines these two measures into a single composite score, while multiplication is typically used when there is an interaction or amplifying effect between the measures. Therefore, addition is the choice that aligns better with statistical intuition.
The ideal feature vector for calculating the distance to the prototype should have low within-class variance, high between-class variance, and a large between-class distance. This ensures that the model has good consistency for samples within the same class while maintaining high discriminability for samples of different classes. The more suitable the feature vector is for the Plant Disease Few-Shot task, the higher the corresponding FASl should be. Equation 15 meets this requirement. We refer to the new network structure discovered through FASl as Swin-Transformer V2 F6 (STV2F6).
2.3 Plant disease feature calibration
Plant disease few-shot classification inherently has sparse training samples. Therefore, if existing data can assist in the N-way-K-shot task, it can further improve the classification accuracy of this task. Inspired by the article (Yang et al., 2021), we attempted to use some data from PlantVillage to calibrate the feature vectors of the support set and query set in the N-way-Kshot task. However, unlike the method mentioned in (Yang et al., 2021), we did not train an additional classification network to learn the distribution of the feature space. Instead, we used an intuitive and convenient non-parametric calibration method. The algorithm framework is shown in Figure 1.
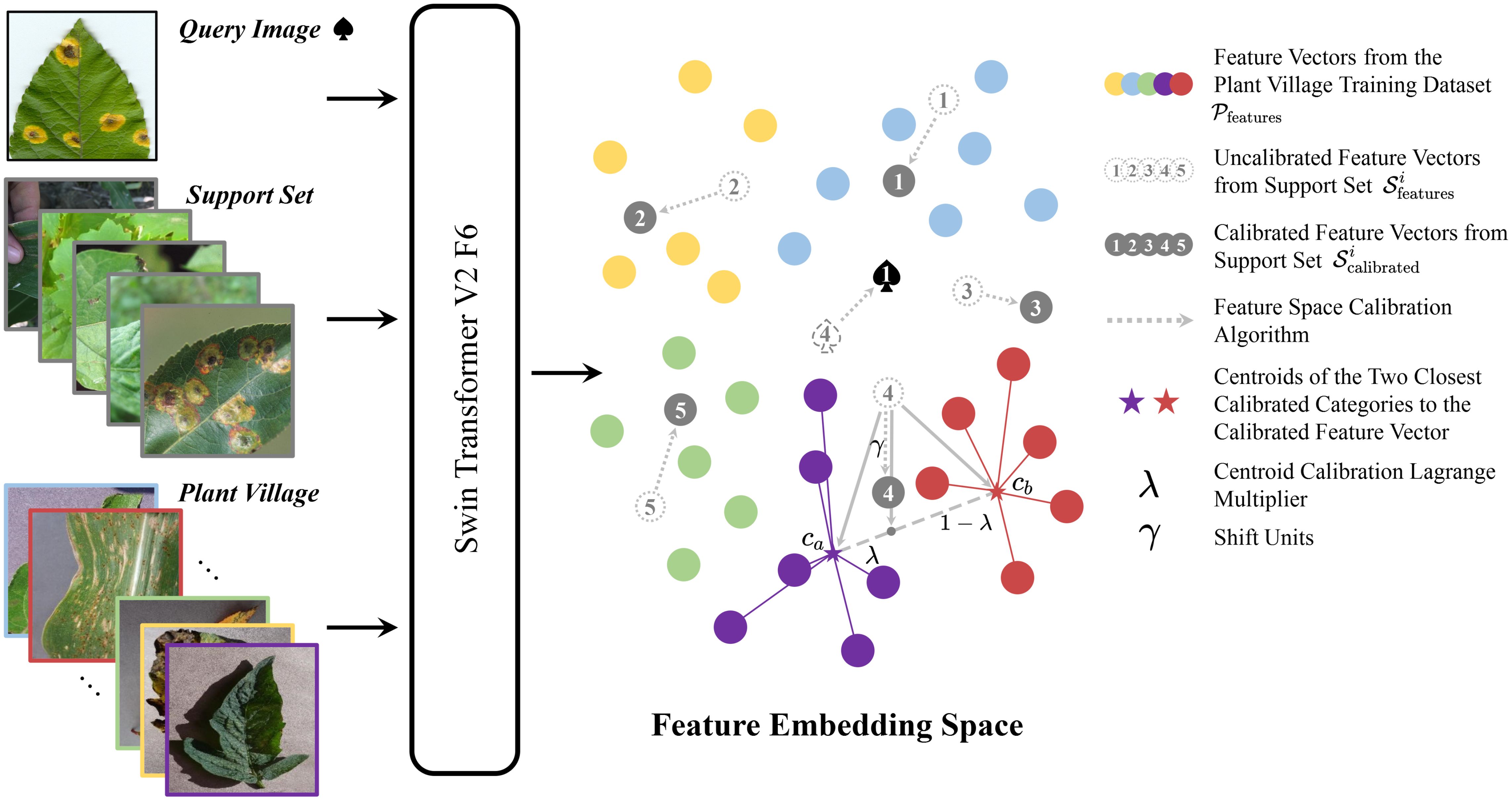
Figure 1. Schematic diagram of plant disease feature calibration algorithm.
From the figure, it can be seen that the query set and the support set both undergo Swin-Transformer V2 F6 to obtain feature vectors and , respectively. The entire PlantVillage training set also undergoes Swin-Transformer V2 F6 to obtain the feature vector set , which serves as a reference for calibrating the feature vectors s. The calibration steps are as follows: For each 5-way-1-shot task, each query image corresponds to a feature vector . For category i, the feature vector set of PlantVillage calculates the L2 distance di to the support set of that category. These distances are sorted in ascending order as , and the top m smallest distances are selected. The centroid of these m vectors is calculated as . We use the centroids of all categories obtained by this method to calibrate . For category i, we first calculate the L2 distances between the category centroid and and sort them in ascending order as . The two smallest distances and correspond to centroids and . A point T is selected on the line connecting these two centroids, with the position of T determined by the hyperparameter . The is then shifted units in the direction collinear with T, completing the calibration of the support set to obtain the calibrated support set . The above steps are repeated to calibrate all support sets. Finally, the distances between all calibrated support sets and the query feature vector are calculated, and the label for the query set q is obtained as . For the 5-way-5-shot and 5-way-10-shot tasks, it is sufficient to use the average of the support set features . The implementation process of the algorithm is presented in pseudocode form in Algorithm 1.

Algorithm 1. PDFC Algorithm.
3 Results
3.1 Environment platform
The hardware setup for the entire experiment is as follows: Processor: Intel(R) Core(TM) i7–10700 CPU @ 2.90GHz, 16GB RAM, NVIDIA GeForce RTX 3060 12GB GPU. Software environment: Python 3.9, Pytorch 1.13.1.
3.2 Implementation details
We first train Swin-Transformer V2-T on the ImageNet dataset using the stochastic gradient descent (SGD) optimizer (momentum of 0.9 and weight decay of 4 × 10−5). The initial learning rate is set to 0.05, and adjusted using step decay with a decay factor of 0.1 every 30 epochs. The model is trained for 300 epochs with a batch size of 128. Data augmentation includes random cropping, horizontal flipping, and color jittering, and the input image size is resized to 224×224. Dropout is set to 0.2, and L2 regularization is used to further enhance the model’s generalization ability. Under these settings, the feature extractor achieves a Top-1 accuracy of 73.18% on the ImageNet dataset. After pre-training, the last layer block, F7, is removed to obtain the feature extractor STV2F6, which is then used for comparative experiments on various datasets with STV2F6+PDFC.
Before the comparative experiments, due to the small number and narrow range of hyperparameters in the PDFC algorithm, we first use Bayesian optimization to find the best combination as the nearest hyperparameter combination for the current dataset, and then perform the final large-scale experiments. Finally, to ensure the stability of the experimental results, each set of N-way-K-shot data in the experiments is sampled 1,000 times, and the average of 20 experimental results is obtained after cross-validation.
3.3 Datasets
CUB (Wah et al., 2011) dataset contains 11,788 images of 200 bird species, and is a classic dataset in the field of fine-grained object classification. Each image is annotated with detailed information, such as the bird species, morphological features, and colors. It is widely used in bird classification and object detection research, especially in visual recognition applications.
mini-ImageNet (Vinyals et al., 2016) is a subset of ImageNet, designed to provide a standard evaluation platform for few-shot learning. It contains 100 categories, with 600 images per category, covering various everyday objects. mini-ImageNet is widely used in testing and research for few-shot learning algorithms, particularly in convolutional neural networks (CNNs) and meta-learning methods.
PlantVillage (Hughes and Salathé, 2015) is an epidemiological dataset used for evaluating automated plant disease recognition systems. All images were collected in a laboratory setting and include images of both healthy and diseased plant leaves. Additionally, the dataset includes augmented images obtained through operations such as flipping, gamma correction, noise injection, PCA color augmentation, rotation, and scaling, encompassing a total of 38 plant diseases and 61,486 images, making it one of the most crucial evaluation datasets in the field of plant disease research.
PlantDoc (Singh et al., 2019) is an open-source dataset for plant disease diagnosis, containing over 4,000 images, covering 13 crop species and 26 types of plant diseases. This dataset is particularly suitable for few-shot learning and transfer learning tasks, providing researchers with a rich resource for training and evaluating plant disease classification models.
Plant Real-World (Li et al., 2023) is a small-scale crop disease diagnosis dataset, containing samples of multiple diseases from four common crops: rice, wheat, maize, and soybean, with a total sample size exceeding 1,000. The dataset includes 12 types of diseases and all samples are captured from field images and disease maps. With a complex and diverse background, this dataset can be used for researching the cross-domain generalization issues in few-shot learning.
Plant&Pest (Li and Yang, 2021) is another small dataset used to validate the performance of few-shot classification models, which includes two parts: plants and pests. In this experiment, we used the plant part of the dataset for few-shot classification experiments.
The illustrations of the four crop datasets used in the experiment are listed in Figure 2.

Figure 2. Examples of images from four crop datasets.
3.4 Results
We use the lightweight version of Swin-Transformer V2, Swin-Transformer V2-T, and employ its pre-trained weights on ImageNet-1K (Krizhevsky et al., 2012) to extract features for the query set Q. According to the structure in the original paper, SwinTransformer V2-T consists of a total of 7 large blocks, each of which outputs a feature ϕl(x) as the input to subsequent components. The output of the 7th block, ϕ7(x), is directly connected to the fully connected layer. To verify whether the final feature ϕ7(x), similar to conventional few-shot tasks, is also suitable for the Plant Disease Few-Shot task, we input all images from six datasets into the backbone of SwinTransformer V2-T. This allows us to obtain 7 sets of features ϕ1∼7(x) generated in the backbone for the six datasets, as well as the corresponding Feature Adaptation Scores FAS1∼7, as shown in Table 1.
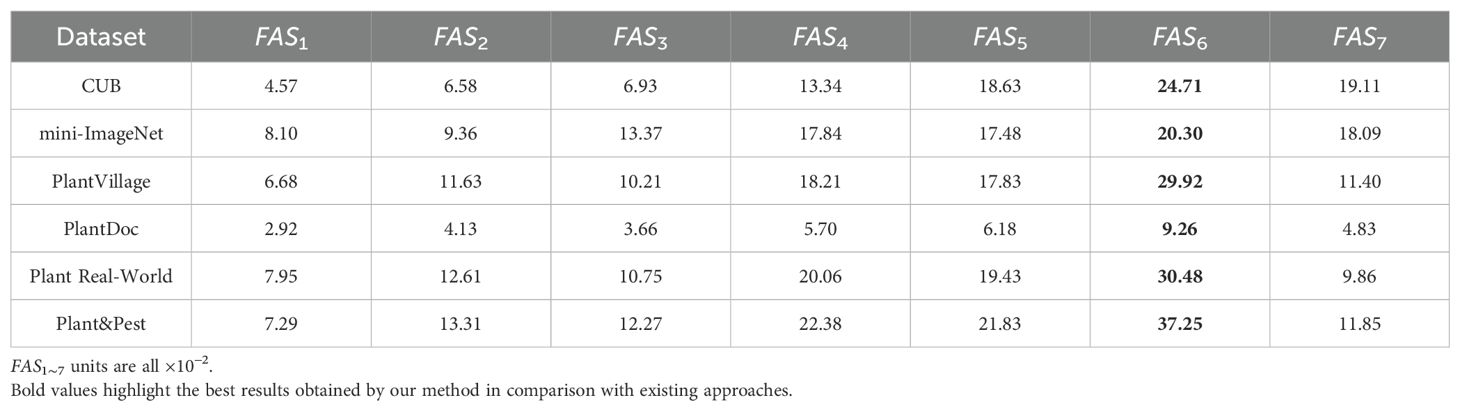
Table 1. Performance adaptation score table FAS1∼7.
As shown in Table 1, the score FAS6 corresponding to the sixth layer feature (Feature Six, F6) of Swin-Transformer V2-T far exceeds the scores of all other layers, indicating that the sixth layer feature F6 is more suitable for the Plant Disease Few-Shot task than the features from other layers. We then conducted comparative experiments using the sixth layer feature F6 and the most commonly used seventh layer feature F7 on different datasets to examine the accuracy of the Plant Disease Few-Shot task. The results are shown in Table 2. From the experimental results, it is evident that F6, with the highest score, achieved a significant improvement in accuracy for the Plant Disease Few-Shot task compared to the commonly used F7. Therefore, both the Performance Adaptation Score PAS and the accuracy comparison of the Plant Disease Few-Shot task’s test set confirm that F6 is more suitable for the Plant Disease Few-Shot task than F7. We consider this an important finding in the field of plant disease diagnosis. Based on the above experimental results, we propose that the most suitable feature extraction network structure for the Plant Disease FewShot task is Swin-Transformer V2 F6 (STV2F6), as shown in Figure 3.
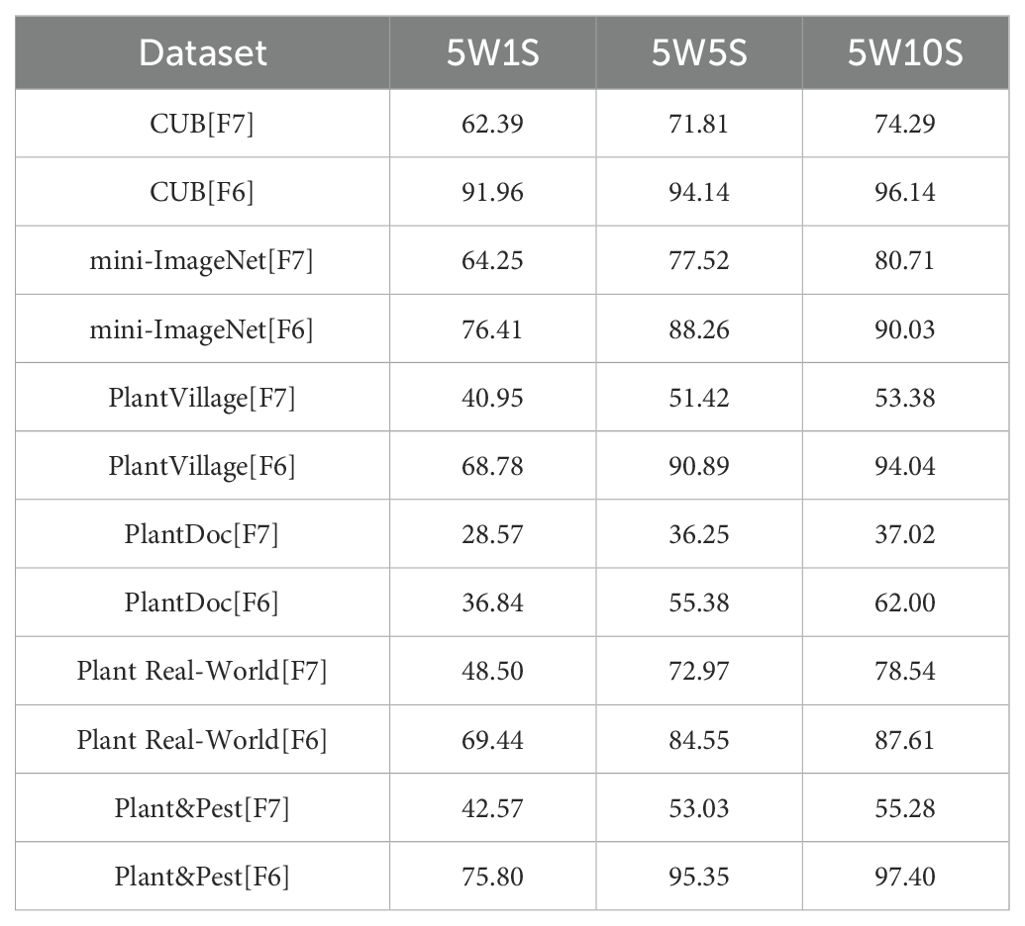
Table 2. Comparison of few shot task performance between F6 and F7 on different datasets.
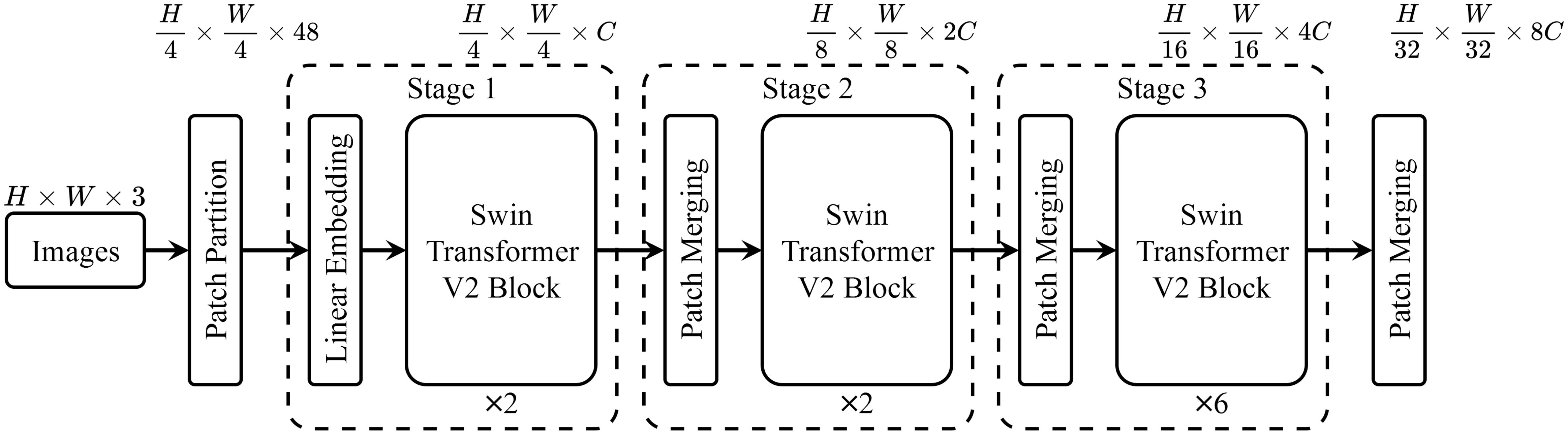
Figure 3. The architecture of Swin-Transformer V2-F6.
Further, we use STV2F6 as a fixed feature extractor and apply the PDFC algorithm to calibrate the feature space of the features extracted from this structure. At the same time, we compare the performance results of STV2F6 combined with the PDFC algorithm with various state-of-the-art methods in the field of few-shot learning. The evaluation metrics for the comparison are the standard few-shot learning metrics: 5-way-1-shot, 5-way-5-shot, and 5-way-10-shot classification accuracy. We first compare our method with several recent few-shot works on the two general datasets, CUB and miniImageNet. During the experiments, the feature vectors in the database are all computed from the samples in ImageNet. The results are shown in Table 3. It is evident from Table 3 that STV2F6+PDFC significantly outperforms the latest research results due to the calibration of the target domain using feature vectors from the ImageNet training set.
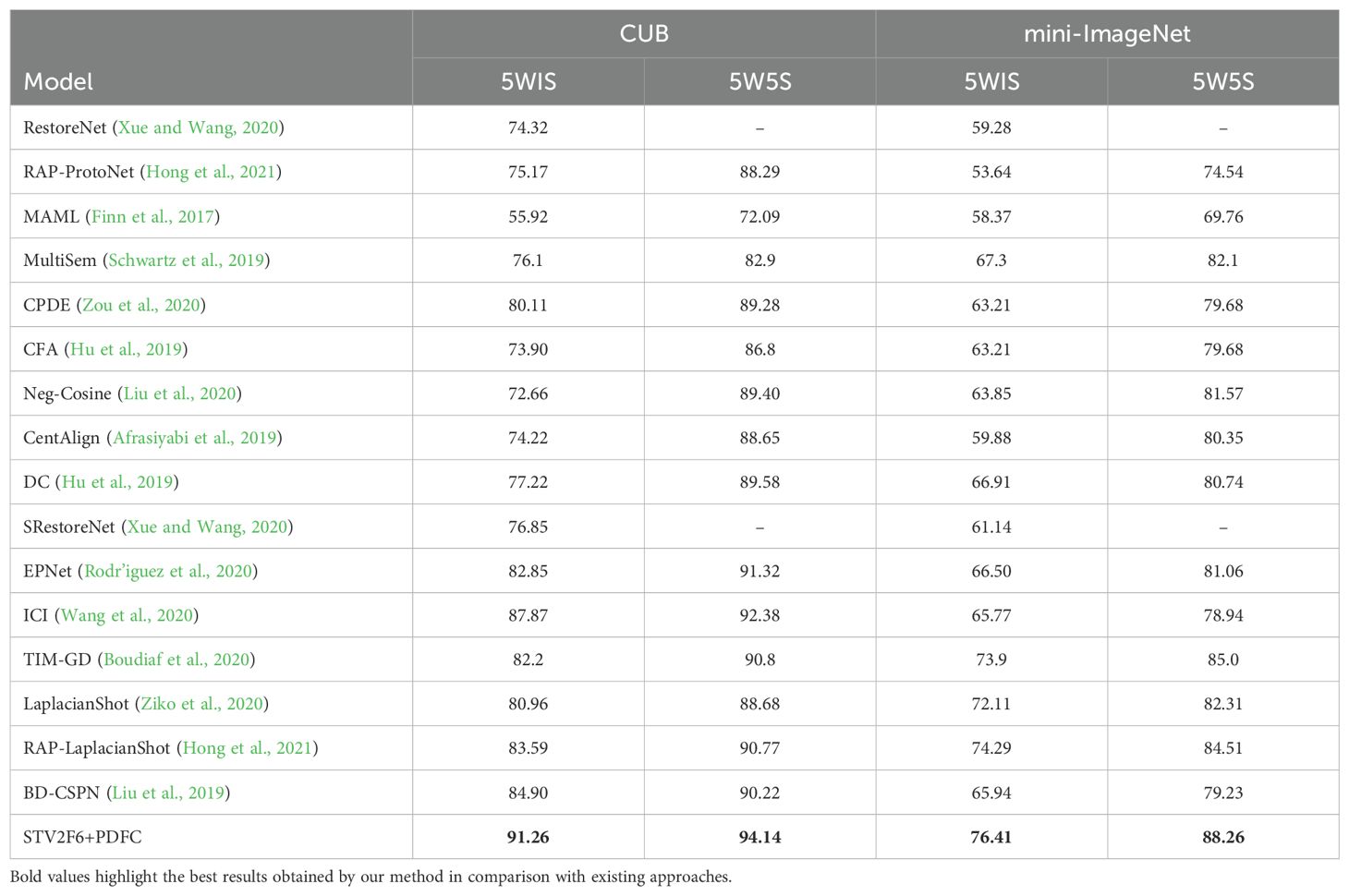
Table 3. Comparison results of few-shot task on cub and mini-ImageNet.
In addition, we compared our approach with various methods recently used in crop disease few-shot tasks, and the comparison results across four datasets are shown in Tables 4-7. From the results, it is clear that the STV2F6+PDFC structure outperforms recent methods in terms of classification accuracy, recall, and F1-score for crop disease few-shot tasks. The experimental results across multiple datasets also clearly demonstrate that the FAS metric can accurately identify the best network structure for fewshot tasks. Meanwhile, the PDFC algorithm can adjust the target domain’s sample feature vectors toward the source domain (ImageNet or PlantVillage), enabling STV2F6+PDFC to efficiently and accurately classify test samples, even when there are no large numbers of reference samples during the testing phase, by leveraging the features learned from previous training.
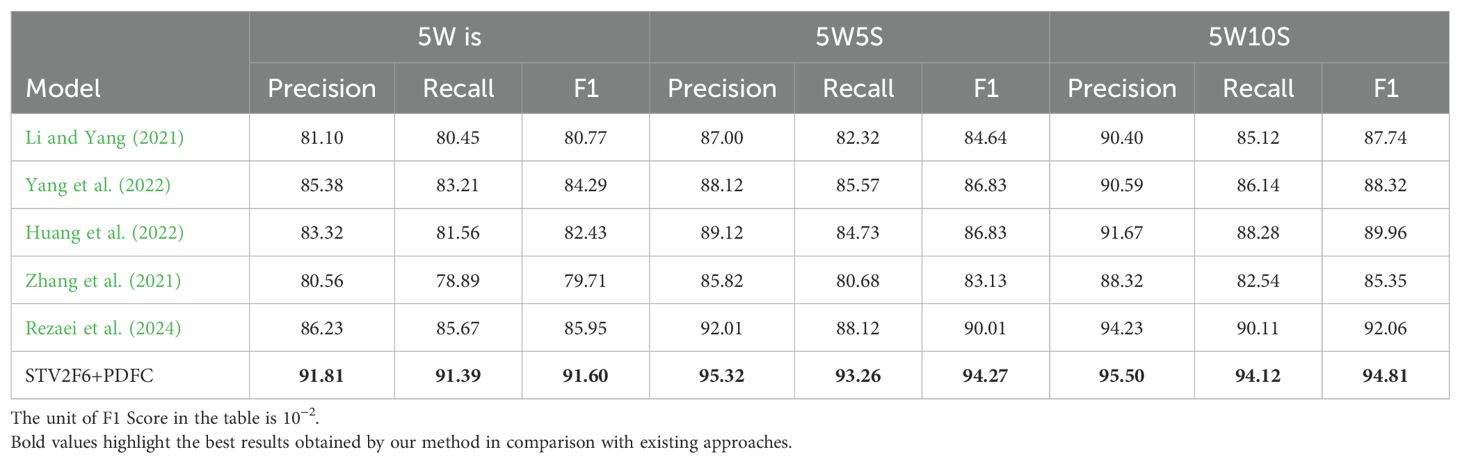
Table 4. Comparison results of plant disease few-shot task on PlantVillage.
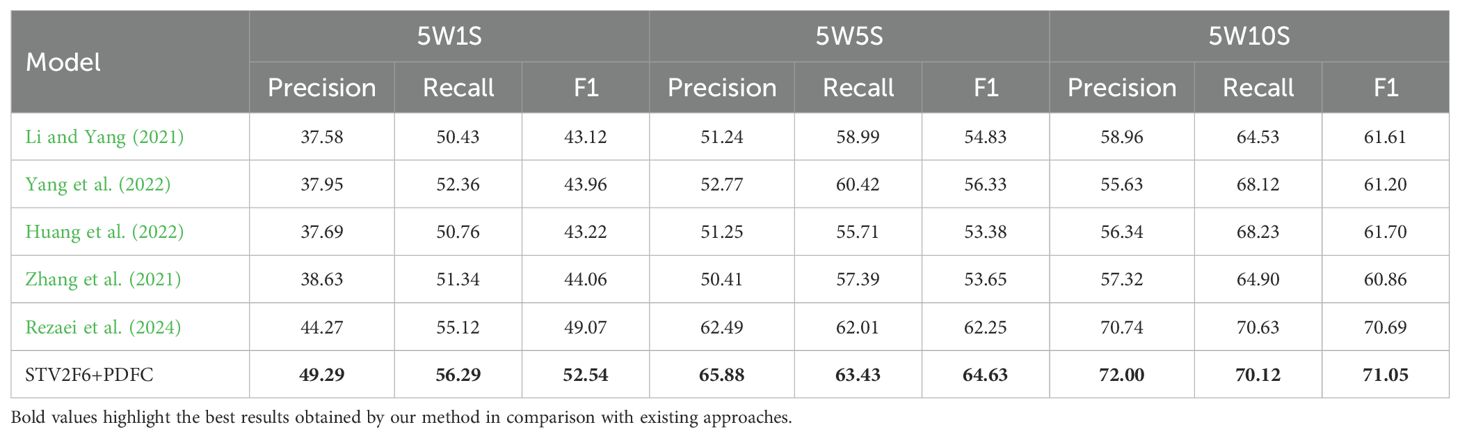
Table 5. Comparison results of plant disease few-shot task on PlantDoc.
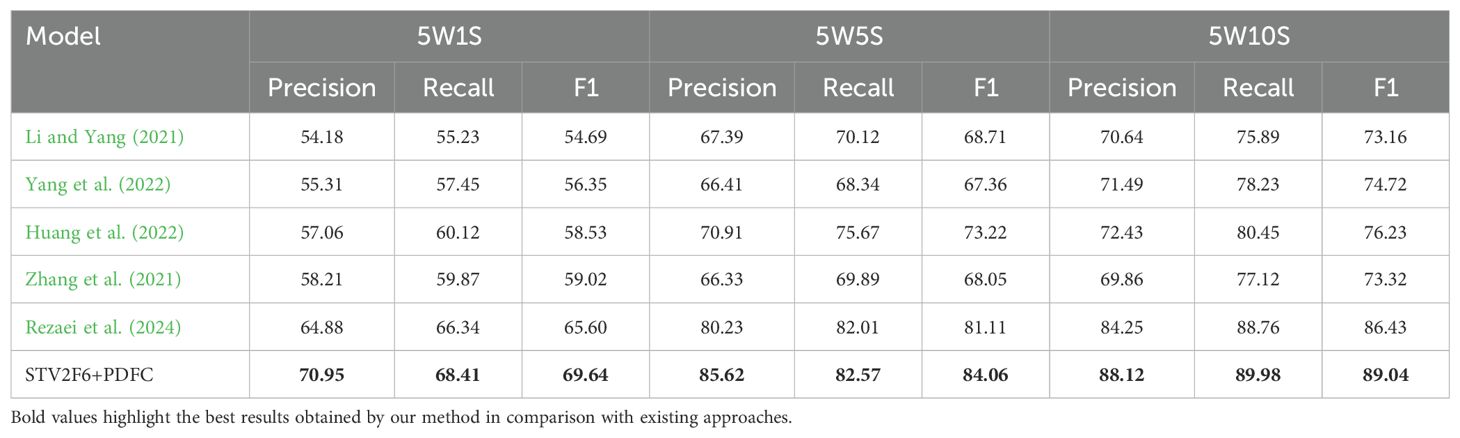
Table 6. Comparison results of plant disease few-shot task on plant real-world.
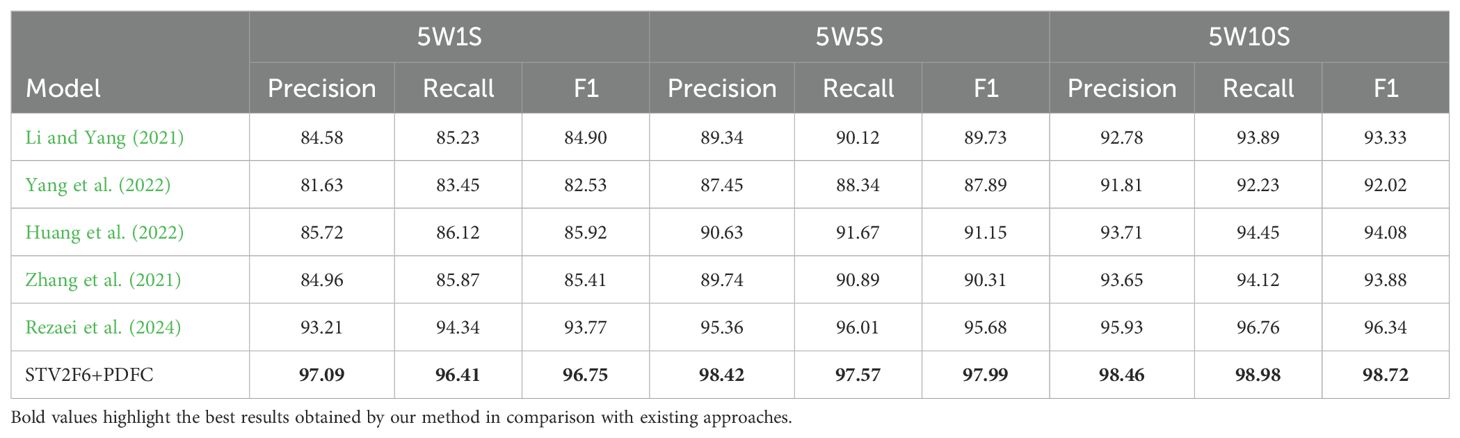
Table 7. Comparison results of plant disease few-shot task on plant & pest.
To further explore the direct impact of the PDFC algorithm on calibrating the embedding feature space, we visualized the feature distributions of STV2F6 before and after calibration using the t-SNE (van der Maaten and Hinton, 2008) tool. The visualization results on the PlantVillage test set are shown in Figure 4. As can be seen from the figure, the features calibrated using the PDFC algorithm are more compactly clustered within the same class, and different classes are further apart, with less overlapping distribution areas. This indicates that it is an effective feature calibration method.
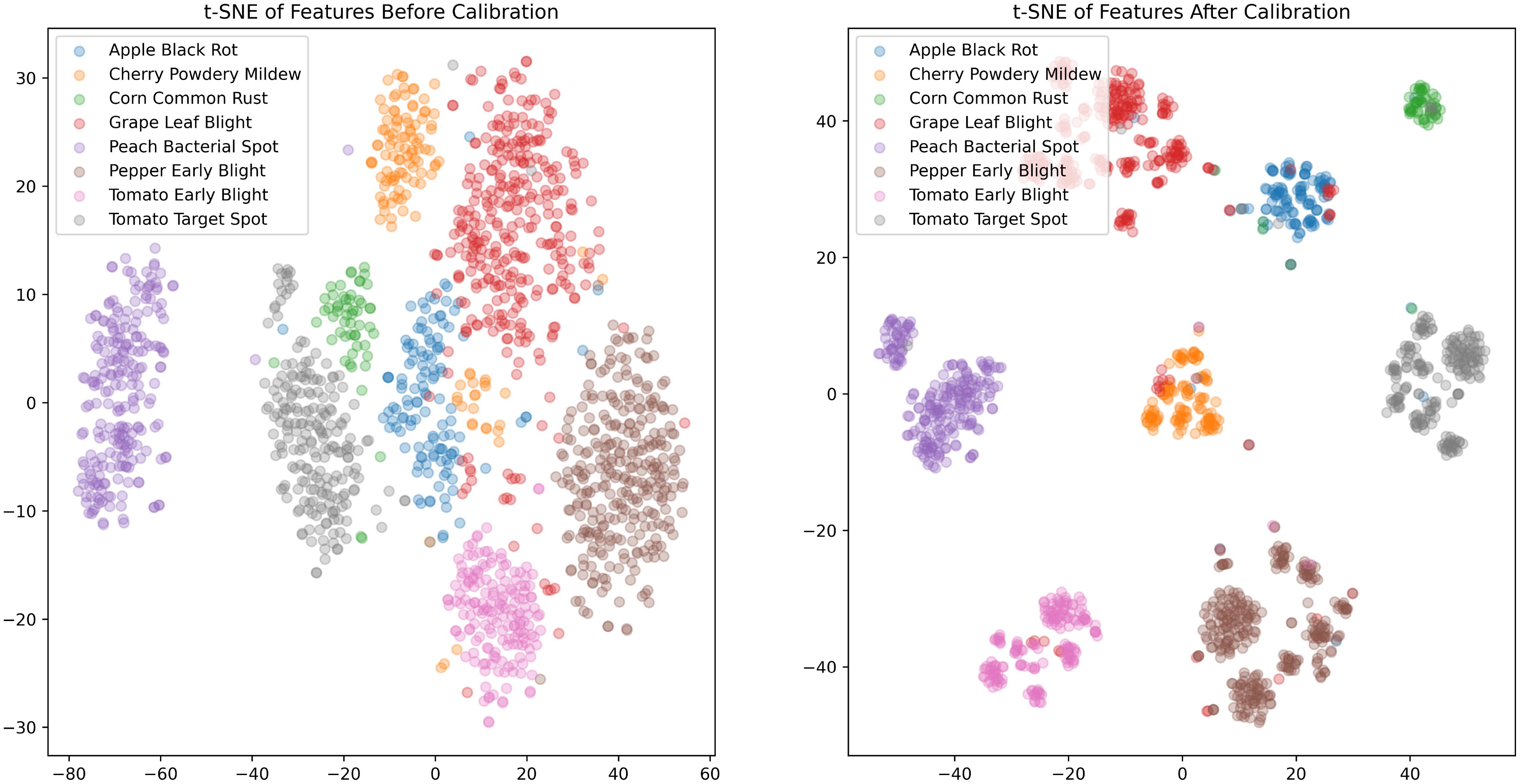
Figure 4. Feature distribution visualization before and after using the PDFC algorithm in STV2F6.
3.5 Sensitivity analysis of the experimental parameters
The parameters affecting the accuracy of the STV2F6+PDFC algorithm experiment results are numerous. In terms of training paradigms, the main aspects include whether to use a pre-trained model, whether to perform finetuning. The parameters mainly involve two hyperparameters, namely the Lagrange Multiplier λ and the Shift Units γ. Below, we discuss and experiment with the stability of the algorithm in terms of training paradigms and parameters.
In our previous experimental results, we directly used the pre-trained model of Swin-Transformer V2-T without any finetuning. We will now conduct separate experiments on whether or not to use a pre-trained model, whether or not to finetune, and whether or not to use the PDFC algorithm. Since the STV2F6 model must either be pre-trained or trained from scratch, a model that neither requires pre-training nor finetuning does not exist. Therefore, there are a total of six remaining scenarios. We conducted separate experiments for these six scenarios on PlantVillage, and the experimental results are shown in Table 8. In the table, the fine-tuning option refers to training the STV2F6 from scratch if no pre-trained model is used. As shown in the table, the model using the pre-trained model and fine-tuning, combined with the PDFC algorithm, exhibits a significant performance drop compared to the model without fine-tuning. This can be explained by the catastrophic forgetting phenomenon that occurs after fine-tuning the neural network. Since few-shot tasks impose higher requirements on the model’s generalization ability, fine-tuning focused on the dataset disrupts some of the already optimized weights of the pre-trained model. Additionally, the results of this experiment show that by directly using the pre-trained model with the PDFC algorithm, without any parameter training, not only does it skip the model training step, but it also achieves the best 5W1S task accuracy. This is an important first attempt in the field of plant disease classification, emphasizing to some extent that the model’s generalization ability should be the primary consideration in this field. Fine-tuning and further algorithm optimization should only be considered for models with poor generalization ability.

Table 8. Comparison results of plant disease few-shot task on PlantVillage.
In addition to training paradigms, the parameters mainly involve two hyperparameters, the Lagrange Multiplier λ and the Shift Units γ, which affect the enhancement effect of the PDFC algorithm on the model. We used grid search to test different Lagrange Multiplier λ and Shift Units γ on PlantVillage. The impact of different λ and γ on the performance of STV2F6 is shown in Figure 5. We searched λ and γ with step sizes of 0.1 and 0.2, respectively. The different parameter combinations have a crucial impact on the model’s performance. Since these two parameters have definite meanings mathematically, we can define their ranges as [0,1]. Thanks to the small number of parameters and the lack of need for training, even with grid search, all results can be obtained in a very short time.
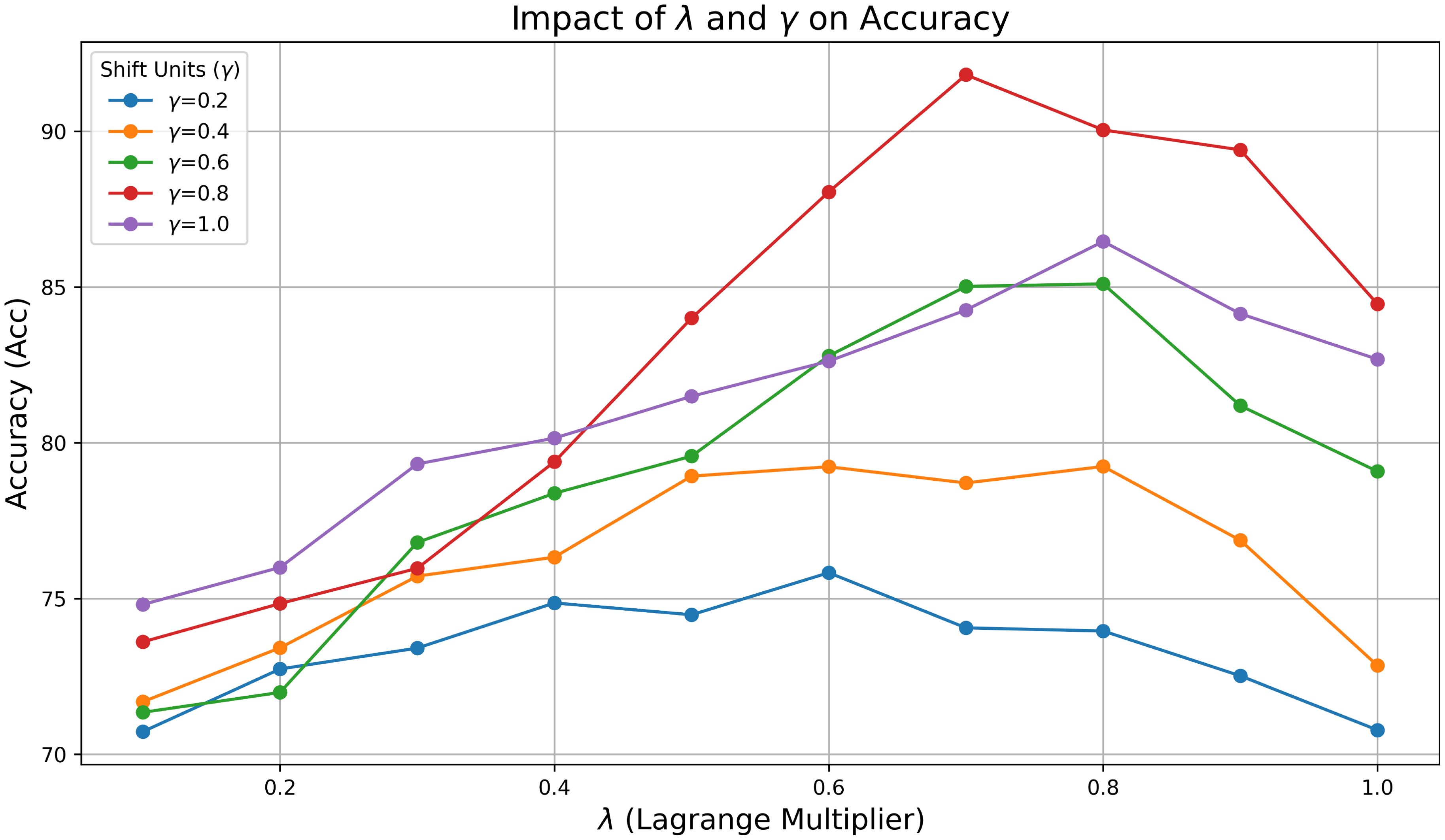
Figure 5. The impact of hyperparameters λ and γ on the performance of the PDFC algorithm.
In our experiments, we need to select different values for the Lagrange Multiplier λ and Shift Units γ based on the dataset. When dealing with large datasets, we can use Bayesian optimization to efficiently search for the best combination of λ and γ. First, we define the parameter space for λ ∈ [10−3,101] and for γ ∈ [10−3,101]. Bayesian optimization uses a Gaussian model to simulate the performance of different hyperparameter combinations. It then employs the Expected Improvement acquisition function to balance exploration and exploitation, guiding the search for the optimal hyperparameters. On the largest datasets, we evaluate through 100 iterations, with the algorithm selecting the best-performing combination of λ and γ based on the model’s performance on the validation set. This process allows for efficient hyperparameter search, especially in large-scale experiments where computational resources are limited. Finally, after the optimization process, the best combination of λ and γ is used for the final largescale experiments, ensuring the model’s optimal performance on the target dataset.
4 Discussion
In exploring the STV2F6 structure, we also tested whether the FAS parameter could identify the optimal depth range of various network structures on backbone networks of mainstream architectures, including ResNet, VGG, MobileNet, and ShuffleNet. The actual test results show that the size of FAS is still strictly positively correlated with the PDFS test accuracy using the pre-trained model directly. However, due to the insufficient accuracy of the above networks themselves and issues such as the inability to perform feature calibration with the PDFC algorithm or the lack of significant calibration effects, they cannot be compared on the same level with the latest models using pre-training, fine-tuning, and network structure adjustments. Therefore, we used Swin-Transformer V2-T as the backbone network to maximize the structural finding ability of FAS. It can be considered that the STV2F6 structure is a successful practice guided by theory.
As shown in the experimental results in Table 4, the performance of STV2F6+PDFC on the 5W10S task in PlantVillage has already approached the accuracy of the standard model (Afifi et al., 2020) trained with full supervision. On one hand, this demonstrates the excellent performance of our algorithm. On the other hand, it also raises the question of whether we need a more complex standard dataset to replace PlantVillage. It is well known that PlantVillage holds a similar position in plant disease recognition as ImageNet does in image classification. However, due to the rapid evolution of neural network structures, STV2F6 can achieve remarkable classification accuracy by using the pre-trained model directly without fine-tuning, even with only 10 images per class. Therefore, it might be more beneficial for the development of smart agriculture to supplement the PlantVillage benchmark, for example, by using PlantDoc as the benchmark instead of PlantVillage. This could encourage future researchers to focus more on datasets with more complex backgrounds, such as PlantDoc, thereby enhancing the practicality of the algorithms.
Seeing the performance results of STV2F6+PDFC, we also envision future work. In terms of the algorithm, we plan to apply the PDFC algorithm to a variety of frameworks, rather than being deeply tied to STV2F6. As can be seen from the implementation process of the PDFC algorithm, it does not depend on the configuration of the feature extraction network. With the advent of GPT-4 (Achiam et al., 2023), we are preparing to replace STV2F6 with a Transformer-based large language model framework to explore the potential of the model in the field of natural language processing. In terms of improving model performance and efficiency, we intend to further refine the feature vector database of the PDFC algorithm by using representative sample feature vectors for comparison, rather than using the feature vectors of the entire training set for retrieval. This approach can significantly reduce the forward inference and feature vector calibration time, especially when the dataset is large.
5 Conclusion
Through in-depth research on few-shot classification tasks for plant disease identification, this paper identifies a highp-erformance network structure, Swin-Transformer V2 F6, using the Feature Adaptation Score (FAS) metric without network training and fine-tuning. Based on this structure, we propose a Plant Disease Feature Calibration (PDFC) algorithm that complements it. Extensive experiments on different datasets show that the Swin-Transformer V2 F6 network structure, evaluated and selected using FAS, combined with the PDFC algorithm, significantly improves the accuracy of few-shot plant disease classification, surpassing existing models and achieving state-of-the-art performance. Our research provides an efficient and accurate method for addressing plant disease classification with few-shot data, offering both theoretical innovation and practical value. It provides robust support for the automatic identification of rare plant diseases and agricultural production management.
Data availability statement
The original contributions presented in the study are included in the article/supplementary material. Further inquiries can be directed to the corresponding author.
Author contributions
JL: Data curation, Formal analysis, Writing – original draft, Writing – review & editing. ZY: Conceptualization, Investigation, Writing – review & editing. DL: Project administration, Resources, Writing – review & editing. HZ: Software, Supervision, Writing – original draft. MX: Validation, Visualization, Writing – original draft.
Funding
The author(s) declare that no financial support was received for the research and/or publication of this article.
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
References
Achiam, O. J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., et al. (2023). Gpt-4 technical report.
Afifi, A., Alhumam, A., and Abdelwahab, A. (2020). Convolutional neural network for automatic identification of plant diseases with limited data. Plants 10. doi: 10.3390/plants10010028
Afrasiyabi, A., Lalonde, J.-F., and Gagn’e, C. (2019). “Associative alignment for few-shot image classification,” in European Conference on Computer Vision.
Argüeso, D., Picón, A., Irusta, U., Medela, A., San-Emeterio, M. G., Bereciartua, A., et al. (2020). Few-shot learning approach for plant disease classification using images taken in the field. Comput. Electron. Agric. 175, 105542. doi: 10.1016/j.compag.2020.105542
Bashir, R. N., Khan, F. A., Khan, A., Tausif, M., Abbas, M. Z., Shahid, M. M. A., et al. (2023). Intelligent optimization of reference evapotranspiration (eto) for precision irrigation. J. Comput. Sci. 69, 102025. doi: 10.1016/j.jocs.2023.102025
Boudiaf, M., Ziko, I. M., Rony, J., Dolz, J., Piantanida, P., and Ayed, I. B. (2020). Transductive information maximization for few-shot learning. ArXiv abs/2008.11297.
Chopra, S., Hadsell, R., and LeCun, Y. (2005). “Learning a similarity metric discriminatively, with application to face verification,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), Vol. 1. 539–546.
de Andrade Porto, J. V., Dorsa, A. C., de Moraes Weber, V. A., de Andrade Porto, K. R., and Pistori, H. (2023). Usage of few-shot learning and meta-learning in agriculture: A literature review. Smart Agric. Technol.
Dosovitskiy, A., Beyer, L., Kolesnikov, A., Weissenborn, D., Zhai, X., Unterthiner, T., et al. (2020). An image is worth 16x16 words: Transformers for image recognition at scale. ArXiv abs/2010.11929.
Egusquiza, I., Picon, A., Irusta, U., Bereciartua-Perez, A., Eggers, T., Klukas, C., et al. (2022). Analysis of few-shot techniques for fungal plant disease classification and evaluation of clustering capabilities over real datasets. Front. Plant Sci. 13. doi: 10.3389/fpls.2022.813237
Figueroa-Mata, G. and Mata-Montero, E. (2020). Using a convolutional siamese network for image-based plant species identification with small datasets. Biomimetics 5. doi: 10.3390/biomimetics5010008
Finn, C., Abbeel, P., and Levine, S. (2017). “Model-agnostic metalearning for fast adaptation of deep networks,” in International Conference on Machine Learning.
Goodfellow, I. J., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., et al. (2014). Generative adversarial networks. Commun. ACM 63, 139–144. doi: 10.1145/3422622
He, K., Zhang, X., Ren, S., and Sun, J. (2015). “Deep residual learning for image recognition,” in 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 770–778.
Hong, J., Fang, P., Li, W., Zhang, T., Simon, C., Harandi, M., et al. (2021). “Reinforced attention for few-shot learning and beyond,” in 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 913–923.
Howard, A. G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., et al. (2017). Mobilenets: Efficient convolutional neural networks for mobile vision applications. ArXiv abs/1704.04861.
Hu, P., Sun, X., Saenko, K., and Sclaroff, S. (2019). Weakly-supervised compositional featureaggregation for few-shot recognition. ArXiv abs/1906.04833.
Huang, Y., Chang, F., Tao, Y., Zhao, Y., Ma, L., and Su, H. (2022). Fewshot learning based on attn-cutmix and task-adaptive transformer for the recognition of cotton growth state. Comput. Electron. Agric. 202, 107406. doi: 10.1016/j.compag.2022.107406
Huang, G., Liu, Z., and Weinberger, K. Q. (2016). “Densely connected convolutional networks,” in 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR). 2261–2269.
Hughes, D. P. and Salathé, M. (2015). An open access repository of images on plant health to enable the development of mobile disease diagnostics through machine learning and crowdsourcing. ArXiv abs/1511.08060.
Karami, A., Crawford, M. M., and Delp, E. J. (2020). Automatic plant counting and location based on a few-shot learning technique. IEEE J. Sel. Topics Appl. Earth Obs. Remote Sens. 13, 5872–5886.
Khan, A. A., Faheem, M. R., Bashir, R. N., Wechtaisong, C., and Abbas, M. Z. (2022a). Internet of things (iot) assisted context aware fertilizer recommendation. IEEE Access 10, 129505–129519. doi: 10.1109/ACCESS.2022.3228160
Khan, A. A., Nauman, M. A., Bashir, R. N., Jahangir, R., Alroobaea, R., Binmahfoudh, A., et al. (2022b). Context aware evapotranspiration (ets) for saline soils reclamation. IEEE Access 10, 110050–110063. doi: 10.1109/ACCESS.2022.3206009
Khanzhina, N., Filchenkov, A., Minaeva, N., Novoselova, L., Petukhov, M. V., Kharisova, I., et al. (2021). Combating data incompetence in pollen images detection and classification for pollinosis prevention. Comput. Biol. Med. 140, 105064. doi: 10.1016/j.compbiomed.2021.105064
Krizhevsky, A., Sutskever, I., and Hinton, G. E. (2012). Imagenet classification with deep convolutional neural networks. Commun. ACM 60, 84–90. doi: 10.1145/3065386
Li, Y. and Yang, J. (2021). Meta-learning baselines and database for few-shot classification in agriculture. Comput. Electron. Agric. 182, 106055. doi: 10.1016/j.compag.2021.106055
Li, J., Yin, Z., Li, D., and Zhao, Y. (2023). Negative contrast: A simple and efficient image augmentation method in crop disease classification. Agriculture. doi: 10.3390/agriculture13071461
Liang, X. (2021). Few-shot cotton leaf spots disease classification based on metric learning. Plant Methods 17. doi: 10.1186/s13007-021-00813-7
Liu, B., Cao, Y., Lin, Y., Li, Q., Zhang, Z., Long, M., et al. (2020). Negative margin matters: Understanding margin in few-shot classification. ArXiv abs/2003.12060.
Liu, Z., Hu, H., Lin, Y., Yao, Z., Xie, Z., Wei, Y., et al. (2021). “Swin transformer v2: Scaling up capacity and resolution,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 11999–12009.
Liu, J., Song, L., and Qin, Y. (2019). Prototype rectification for few-shot learning. ArXiv abs/1911.10713.
Nesteruk, S., Shadrin, D. G., and Pukalchik, M. (2021). Image augmentation for multitask few-shot learning: Agricultural domain use-case. ArXiv abs/2102.12295.
Nuthalapati, S. V. and Tunga, A. (2021). “Multi-domain few-shot learning and dataset for agricultural applications,” in 2021 IEEE/CVF International Conference on Computer Vision Workshops (ICCVW). 1399–1408.
Rezaei, M., Diepeveen, D., Laga, H., Jones, M. G. K., and Sohel, F. (2024). Plant disease recognition in a low data scenario using few-shot learning. Comput. Electron. Agric. 219, 108812. doi: 10.1016/j.compag.2024.108812
Riou, K., Zhu, J., Ling, S., Piquet, M., Truffault, V., and Callet, P. L. (2020). “Few-shot object detection in real life: Case study on auto-harvest,” in 2020 IEEE 22nd International Workshop on Multimedia Signal Processing (MMSP). 1–6.
Rodr’iguez, P., Laradji, I. H., Drouin, A., and Lacoste, A. (2020). “Embedding propagation: Smoother manifold for few-shot classification,” in European Conference on Computer Vision.
Schwartz, E., Karlinsky, L., Feris, R. S., Giryes, R., and Bronstein, A. M. (2019). Baby steps towards few-shot learning with multiple semantics. Pattern Recognit. Lett. 160, 142–147. doi: 10.1016/j.patrec.2022.06.012
Simonyan, K. and Zisserman, A. (2014). Very deep convolutional networks for large-scale image recognition. CoRR abs/1409.1556.
Singh, D. P., Jain, N., Jain, P., Kayal, P., Kumawat, S., and Batra, N. (2019). “Plantdoc: A dataset for visual plant disease detection,” in Proceedings of the 7th ACM IKDD Cods and 25th COMAD.
Snell, J., Swersky, K., and Zemel, R. S. (2017). Prototypical networks for few-shot learning. Neural Inf. Process. Syst.
van der Maaten, L. and Hinton, G. E. (2008). Visualizing data using t-sne. J. Mach. Learn. Res. 9, 2579–2605.
Vinyals, O., Blundell, C., Lillicrap, T. P., Kavukcuoglu, K., and Wierstra, D. (2016). Matching networks for one shot learning. Neural Inf. Process. Syst.
Vishnoi, V. K., Kumar, K., Kumar, B., Mohan, S., and Khan, A. A. (2023). Detection of apple plant diseases using leaf images through convolutional neural network. IEEE Access 11, 6594–6609. doi: 10.1109/ACCESS.2022.3232917
Wah, C., Branson, S., Welinder, P., Perona, P., and Belongie, S. J. (2011). The caltech-ucsd birds-200–2011 dataset.
Wang, S., Han, Y., Chen, J., He, X., Zhang, Z., Liu, X., et al. (2022). Weed density extraction based on few-shot learning through uav remote sensing rgb and multispectral images in ecological irrigation area. Front. Plant Sci. 12. doi: 10.3389/fpls.2021.735230
Wang, Y., Xu, C., Liu, C., Zhang, L., and Fu, Y. (2020). “Instance credibility inference for few-shot learning,” in 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 12833–12842.
Xue, W. and Wang, W. (2020). One-shot image classification by learning to restore prototypes. ArXiv abs/2005.01234. doi: 10.1609/aaai.v34i04.6130
Yang, S., Liu, L., and Xu, M. (2021). Free lunch for few-shot learning: Distribution calibration. ArXiv abs/2101.06395.
Yang, J., Shuang Yang, Y., Li, Y., Xiao, S., and Ercis¸li, S. (2022). Image information contribution evaluation for plant diseases classification via inter-class similarity. Sustainability. doi: 10.3390/su141710938
Zhang, D., Pan, F., Diao, Q., Feng, X., Li, W., and Wang, J. (2021). Seeding crop detection framework using prototypical network method in uav images. Agriculture. doi: 10.3390/agriculture12010026
Ziko, I. M., Dolz, J., Granger, E., and Ayed, I. B. (2020). Laplacian regularized few-shot learning. ArXiv abs/2006.15486.
Keywords: deep learning, few-shot learning, plant disease classification, feature calibration, image classification
Citation: Li J, Yin Z, Li D, Zhang H and Xu M (2025) An efficient non-parametric feature calibration method for few-shot plant disease classification. Front. Plant Sci. 16:1541982. doi: 10.3389/fpls.2025.1541982
Received: 09 December 2024; Accepted: 21 April 2025;
Published: 19 May 2025.
Edited by:
Thomas Thomidis, International Hellenic University, GreeceReviewed by:
Arfat Ahmad Khan, Khon Kaen University, ThailandShankey Garg, National Institute of Technology Raipur, India
Copyright © 2025 Li, Yin, Li, Zhang and Xu. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Zhendong Yin, eWluemhlbmRvbmdAaGl0LmVkdS5jbg==
†ORCID: Zhendong Yin, orcid.org/0000-0002-7567-9084
Jiqing Li, orcid.org/0009-0009-4415-366X
Dasen Li, orcid.org/0000-0002-4747-0486
Mingdong Xu, orcid.org/0000-0002-9598-0114