 Faten Dhawi
Faten Dhawi Abdul Ghafoor
Abdul Ghafoor Norah Almousa3
Norah Almousa3- 1Agricultural Biotechnology Department, College of Agricultural and Food Sciences, King Faisal University, Al Ahsa, Saudi Arabia
- 2Center for Water and Environmental Studies, King Faisal University, Al-Ahsa, Saudi Arabia
- 3Fab Lab, Abdulmonem Al Rashed Humanitarian Foundation, Al-Ahsa, Saudi Arabia
Digital tools and non-destructive monitoring techniques are crucial for real-time evaluations of crop output and health in sustainable agriculture, particularly for precise above-ground biomass (AGB) computation in pearl millet (Pennisetum glaucum). This study employed a transfer learning approach using pre-trained convolutional neural networks (CNNs) alongside shallow machine learning algorithms (Support Vector Regression, XGBoost, Random Forest Regression) to estimate AGB. Smartphone-based RGB imaging was used for data collection, and Shapley additive explanations (SHAP) methodology evaluated predictor importance. The SHAP analysis identified Normalized Green-Red Difference Index (NGRDI) and plant height as the most influential features for AGB estimation. XGBoost achieved the highest accuracy (R2 = 0.98, RMSE = 0.26) with a comprehensive feature set, while CNN-based models also showed strong predictive ability. Random Forest Regression performed best with the two most important features, whereas Support Vector Regression was the least effective. These findings demonstrate the effectiveness of CNNs and shallow machine learning for non-invasive AGB estimation using cost-effective RGB imagery, supporting automated biomass prediction and real-time plant growth monitoring. This approach can aid small-scale carbon inventories in smallholder agricultural systems, contributing to climate-resilient strategies.
1 Introduction
In sustainable agriculture, digital technologies and non-destructive monitoring methods are essential for real-time assessments оf crop health and productivity. Biomass serves as an indicator оf crop vigor, reflecting vital processes such as photosynthesis, energy transfer, and water exchange with the atmosphere (Yue et al., 2017; Liu et al., 2022; Zheng et al., 2023). Accurate biomass estimation іs critical for resource allocation, and yield prediction, all оf which contribute tо food security and agricultural production optimization (Niu et al., 2019; Jimenez-Sierra et al., 2021; Tang et al., 2022; Chiu and Wang, 2024). A biomass assessment offers valuable information about carbon sequestration mechanisms since biomass is directly related to the amount of carbon stored in vegetative matter (Lorenz and Lal, 2014; Ortiz-Ulloa et al., 2021; Funes et al., 2022; Chopra et al., 2023; Saleem et al., 2023). In the present study, we emphasized pearl millet (Pennisetum glaucum) which is an important grain crop known for its high nutritional value, climate resilience, and potential health advantages. Its gluten-free characteristics and high nutrient content have inspired the development of numerous food products, like as beverages and infant foods, which are increasingly popular in health-conscious markets around the globe (Deevi et al., 2024). The crop’s remarkable tolerance to hot and arid conditions makes it especially suited to regions facing climate variability, positioning it as a critical player in climate-resilient agriculture and food security (Taylor, 2015; Shrestha et al., 2023). Furthermore, pearl millet has a high potential for carbon sequestration via biomass and soil interactions (Terefe et al., 2020; Ali et al., 2021).
Conventional techniques of biomass measurement are manual, time-consuming, and destructive (Fry, 1990; Bazzo et al., 2023). In recent times, methods for monitoring without causing damage have gained significant attention in research. Thanks to advancements in computer vision, image-based methods are becoming popular for non-destructive monitoring of crop development. These methods specifically take low-level features from digital images and connect them to growth-related phenotypes like leaf area index and biomass (Fry, 1990; Radloff and Mucina, 2007; Tsaftaris et al., 2016; Bazzo et al., 2023). RGB imaging, which uses red, green, and blue wavelengths to record intricate morphological information, has become a potent tool for plant health monitoring (Kefauver et al., 2015; Alves et al., 2021). RGB imagery’s semantic segmentation allows for accurate vegetation categorization by differentiating plant components from backgrounds like soil or debris (Zhuang et al., 2018). Contemporary developments use deep and shallow machine learning to increase segmentation precision; for example, U-net designs identify vegetation from the background, and Support Vector Machines (SVM) categorize vegetation into green and senescent groups based on colour space analysis (Kolhar and Jagtap, 2021; Karthik et al., 2022; Madec et al., 2023).
The introduction of deep learning technologies has fundamentally changed the approaches used in plant development analysis, especially when it comes to the application of sophisticated methods like RGB image segmentation in conjunction with the evaluation of different vegetation indices (Khaki et al., 2020; Zheng et al., 2022). Convolutional neural networks (CNNs) are a cutting-edge deep learning technique that adeptly process images to learn complex features. When provided with a generous amount of data, CNNs are capable of reaching a level of precision that surpasses traditional methods. Consequently, Convolutional Neural Networks (CNNs), for instance, are particularly effective in agricultural applications to extract and interpret complex features related to plant morphology, texture, the diagnosis of plant diseases, detection and enumeration of plant organs, crop yield, and chromatic properties (Castro et al., 2020; Poley and McDermid, 2020; Khaki et al., 2020; Morbekar et al., 2020; Schreiber et al., 2022; Kaya and Gürsoy, 2023; Gonten et al., 2024; Issaoui et al., 2024). Convolutional Neural Networks (CNNs) permit scalable, non-intrusive biomass evaluation, crucial for ecological surveillance, forestry, and precision farming (LeCun et al., 2015; Nakajima et al., 2023; Gülmez, 2024).
Estimating plant biomass from photographs has been attempted in some published papers (Schreiber et al., 2022; Ma et al., 2023; Zheng et al., 2023). One approach involved using linear modelling, hyperspectral imagery, and other vegetation indexes to predict wheat biomass (Yue et al., 2017). Features related to grass growth were evaluated using digital image analysis., Researchers established correlation between observed values of dry matter content, oven-dried biomass, and aboveground fresh biomass with the image-derived attributes, such as the percentage of green pixels and projected area (PA) (Tackenberg, 2007). Additionally, the visual atmospherically resistant index (VARI) and excess green (ExG), two vegetation indices extracted from digital images, were used to evaluate biophysical characteristics of maize. The results showed that ExG effectively estimated overall LAI, while VARI corresponded with green LAI (Sakamoto et al., 2012). Convolutional neural networks (CNN) effectively monitored greenhouse lettuce growth and predicted metrics such as leaf fresh weight (LFW), leaf dry weight (LDW), and leaf area (LA) (Zhang et al., 2020; Gang et al., 2022). Han et al (Han et al., 2019). focused on estimating maize’s above-ground biomass (AGB). They extracted spectral and structural information from photographs using four machine-learning algorithms: artificial neural networks, random forests, support vector machines, and multiple linear regression. The best-performing model was the random forest model, which had low error rates and high explained variance.(Yang et al., 2023). employed the Photosynthetic Accumulation Model (PAM) in combination with a range of vegetative indices to measure the aboveground biomass (AGB) of rice. The results demonstrated that combining height data and VIs produced more accurate AGB projections, providing a reliable technique for evaluating rice growth variables, with R2 values above 0.8. (Wang et al., 2022b). addressed the challenge of predicting above-ground biomass (AGB) in winter wheat at field-scale, finding that random forest models outperforming partial least squares regression models in both training and validation datasets. (Carlier et al., 2023). investigated the application of convolutional neural networks (CNNs) for forecasting biophysical variables in wheat, identifying EfficientNetB4 and Resnet50 as particularly proficient in predicting biomass and nitrogen traits. Their findings indicated that while pseudo-labelling enhanced CNN efficacy, traditional methods like Partial Least Square regression (PLSr) were comparatively less effective, highlighting the need for further research to optimize CNN applications in crop phenotyping.
While artificial intelligence (AI) has been used in agriculture for tasks like disease classification (Kumari et al., 2022), there is still much to learn regarding the utilization of machine learning algorithms for regression analysis tasks. Most prior studies have focused on biomass estimation in major crops such as wheat, rice, maize, and lettuce (Niu et al., 2019; Zhang et al., 2020; Gang et al., 2022; Carlier et al., 2023; Chiu and Wang, 2024). This study targets pearl millet, an underrepresented and a climate-resilient crop critical for arid and semi-arid regions, where precise biomass estimation is essential for sustainable agriculture. This study aims to demonstrate the benefits of utilising machine learning (e.g., XGBoost) and deep learning (e.g., CNN) for measuring above-ground biomass (AGB) of pearl millet. We emphasize its distinct contributions, including a comprehensive evaluation of several vegetation indices (VIs) for AGB estimation and a comparison between the interpretability of XGBoost and CNN’s feature extraction. CNN’s superiority over conventional techniques in identifying intricate correlations in low-dimensional data serves as justification for its use. Furthermore, unlike traditional remote sensing platforms (e.g., UAVs or satellites) which are indeed suited for broader and large scales, our focus on smartphone imaging holds immense potential for democratizing data collection, particularly in scenarios where resources or infrastructure for advanced imaging technologies are limited. Its utility extends to applications such as precision monitoring in small-scale agricultural plots and localized environmental assessments. This approach would bridge the gap between advanced technologies and resource-limited farming communities as well as between small- and large-scale imaging systems by devising cost-efficient models utilizing visible imaging. Additionally, the significance of the study lies in how the integration of smartphone imaging with machine learning can contribute to sustainable agricultural practices by enabling real-time, on-site biomass estimation, which clearly establish the value and relevance of our research to both the scientific community and its practical applications for pearl millet cultivation and facilitating effective crop health monitoring.
2 Materials and methods
2.1 Experimental design and data collection
This study was structured using a completely randomized block design in a factorial format to evaluate the effects of different treatments on pearl millet growth. The experimental setup included three distinct treatment groups: control, Fertilizer 1, and Fertilizer 2, each with six replicates, totalling 18 experimental units per group. Pearl millet seeds were soaked at 28–30°C for four days to initiate germination. Following germination, 10 seeds were planted in each PVC pot, with pot dimensions of 150 × 100 × 125 mm. Each pot had four drainage holes at the base, and trays were placed underneath to collect drainage. The irrigation schedule, conducted every three days, was determined based on typical meteorological conditions in Saudi Arabia’s Eastern region. A 5-5-5 (N-P2O5-K2O) liquid fertilizer was applied at a concentration of 5 mL per liter of irrigation water. Throughout the experiment, plant height (from ground level to the shoot tip) and dry weight (obtained after drying at 105°C for 24 hours) were recorded at each growth stage (16, 34, 45, 65, and 90 days after sowing) for 10 randomly selected experimental units, providing heterogenous growth metrics throughout the experiment. As a result, 150 points were obtained from all of the readings and used in the data analysis. The following formula was used to convert AGB per pot to Mgha-1
To facilitate digital analysis, high-resolution RGB images of the plants were captured at each growth stage using an iPhone 14 Pro Max (Apple Inc.). The iPhone was set up one meter above the vegetation. Initially, the digital photographs had pixel resolutions of 900 x 1600. The iPhone’s back camera is 48 MP and has an aperture of 1.78. Every image was taken in a laboratory environment with 700–720 lux of lighting. Images were saved in JPG format with a resolution of 1000 × 800 pixels, forming the primary dataset for subsequent machine learning-based biomass estimation.
2.2 Data preprocessing
Data preprocessing was critical to ensure model robustness and enhance its generalization capability. Several pre-processing procedures are applied to the images to improve their quality and prepare them for deep learning model training. For instance, through normalization, the images’ pixel intensity values were scaled to a standard range, such as 0 to 1 or -1 to 1. The photos were resized to a consistent size of 800x800 pixels to guarantee consistency. Various data augmentation techniques including random horizontal and vertical flips, rotations, and modifications in brightness and contrast were applied as standard procedure to artificially increase the diversity of the dataset [44, 48]. Image processing tasks, such as image reading, cropping, and preparation for model training, were executed using Python 3.10.12, employing OpenCV, PIL, Numpy, and Scikit-Image libraries (Van Der Walt et al., 2014; Harris et al., 2020; Sharma et al., 2020). These preprocessing steps aimed to create a diverse and well-prepared dataset, enhancing the deep learning model’s ability to accurately predict biomass and adapt to variances in image quality and environmental conditions.
2.3 Semantic segmentation with deep learning
In image analysis, semantic segmentation classifies each pixel in an image using Convolutional Neural Networks (CNNs), which capture intricate spatial correlations. CNNs function by iteratively applying convolutional kernels, which operate through piece-wise multiplication with input data. By combining neighbouring pixel values into a full spatial representation, CNNs can grasp intricate spatial interactions because of their layered structure. Increasingly complex feature representations are created as data moves through these convolutional layers, leading to network topologies customized for particular uses (Kolhar and Jagtap, 2021; Madec et al., 2023). Fully convolutional segmentation workflows generally follow a two-stage approach. First, the model extracts high-level features from input images, encoding significant spatial and textural details. Subsequently, these features are used to predict each pixel’s class at the original resolution. A prominent model for this is the encoder-decoder architecture. In this architecture the encoder condenses the input into a compact, high-level feature representation, retaining essential spatial information. The decoder then reconstructs these features back to the original resolution, ensuring precise spatial alignment of segmented output with the input (Khaki et al., 2020; Kaya and Gürsoy, 2023).
In this study, we used weights from the VegAnn dataset to initialize the SegVeg model, an architecture created for plant image segmentation (Serouart et al., 2022), Figure 1. Masks were generated using the SegVeg model, which operates in two stages: the first stage uses a U-net architecture to predict binary masks separating vegetation from the background, while the second stage applies a Support Vector Machine (SVM) to classify vegetation pixels into green and senescent categories. This classification capability is vital for ecological and agricultural applications, as it facilitates comprehensive assessments of vegetation cover, plant vitality, and various agronomic factors. The SegVeg model builds on the U-net architecture, a robust encoder-decoder framework tailored for semantic segmentation tasks. U-Net’s structure captures both fine details and broader contextual information, making effective segmentation of complex vegetation patterns. A Support Vector Machine (SVM) layer is integrated, improving the segmentation of plant pixels into green and senescent categories (Serouart et al., 2022; Madec et al., 2023).
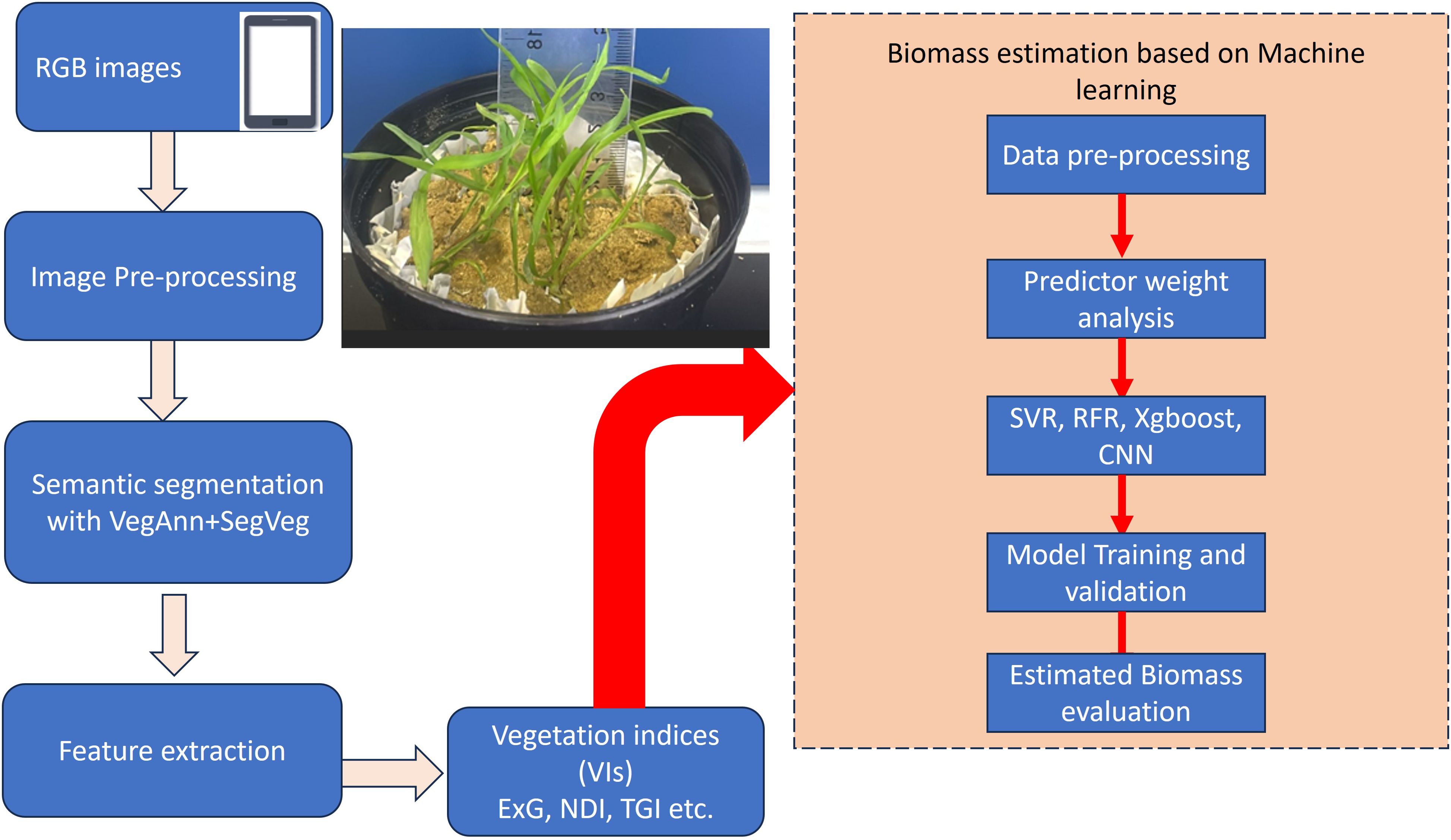
Figure 1. Schematic diagram of the methods employed in this investigation.
The proposed U-Net architecture was implemented, utilizing PyTorch version 2.4 (Facebook, Inc., CA, USA), within the dynamic environment of Google Colab (Google Colab website (last accessed 22 October 2024): https://colab.research.google.com/). An NVIDIA Tesla T4 GPU with 16 GB of dedicated memory was used for its high-performance computing capabilities. The two primary routes of the U-Net architecture are the encoder (down-sampling) and the decoder (up-sampling), which are joined by a bottleneck. There are two convolutional layers and a max-pooling layer for down-sampling in each of the four stages of the encoder pipeline (960 kernels). A 2x2 max-pooling layer cuts the feature maps’ spatial size in half after each step. The encoder and decoder paths are connected by the bottleneck (1024 kernels). Two convolutional layers are used to further process the features that have been extracted. Four up-sampling stages make up the decoder path (960 kernels). To improve spatial resolution, each stage starts with an up-convolution (transposed convolution), which is followed by two convolutional layers. A 2×2 up-convolution (transposed convolution) is used in each up-sampling step to double the spatial dimensions. The final layer uses a 1×1 convolutional layer with 3 kernels to map the output feature maps to the required number of classes (background, green vegetation, and senescent vegetation).
To ensure that each picture could be partitioned into manageable pieces complying to the essential specifications, the original images were selectively padded with zeros as needed, generating consistently dimensioned patches of 800 × 800 pixels that do not overlap. Bias in the training process was eliminated since the plant and background masks were evenly distributed among these patches. All CNN layers had identical feature representations since each mask was normalized to a scale of [0, 1]. To increase the model’s performance and convergence, pre-trained parameters from the ImageNet database were utilized followed by training with the Adam optimizer. Earlier research (Serouart et al., 2022; Madec et al., 2023) provides further detailed descriptions of the model and training procedures. The assessment of semantic segmentation employed a variety of techniques, prominently featuring the intersection-over-union (IoU), accuracy, and F1-score.
Where TP (true positives) is the proportion of pixels well predicted in green crop class; TN (true negative) is the proportion of pixels well predicted in the background class; FP (false positives) is the proportion of pixels wrongly predicted in green crop class; and FN (false negatives) is the proportion of pixels wrongly predicted in background (Figure 2).
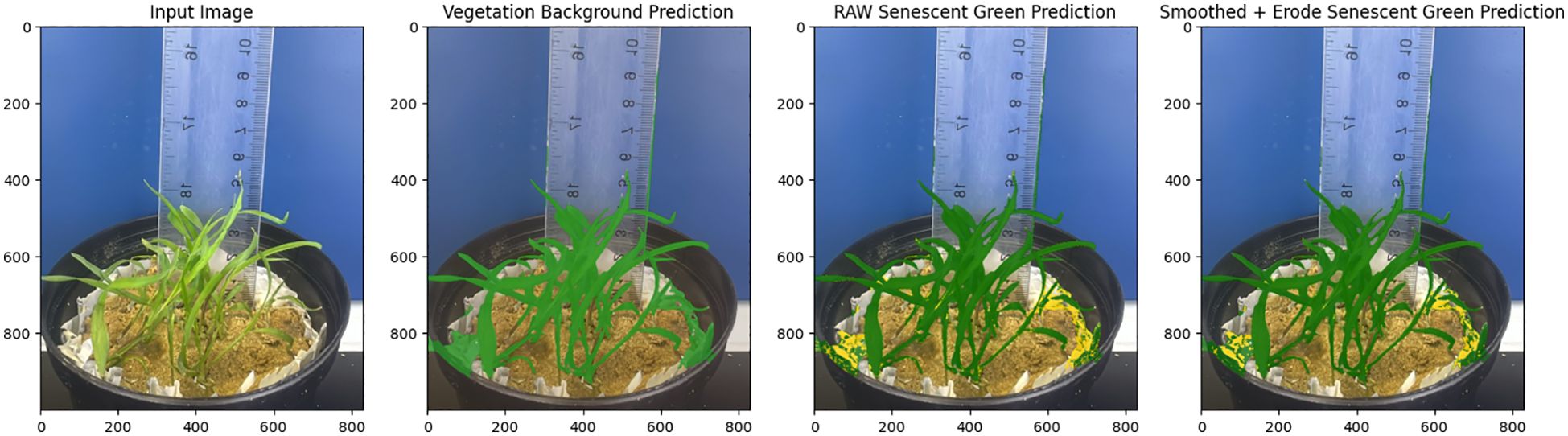
Figure 2. Visualization of image segmentation results of Pearl Millet using VegAnn and SegVeg.
2.4 Phenotypic feature extraction
RGB images inherently carry a rich spectrum of visual information that may be efficiently used for phenotypic feature extraction. This procedure is critical for extracting and characterizing different visual qualities from picture data. Each RGB picture consists of three spectral channels: red, green, and blue, each represented by a matrix of pixel values that capture different elements of plant shape and health. Based on prior studies demonstrating their significance and utility in estimating AGB (Hamuda et al., 2016; Gang et al., 2022; Gerardo and de Lima, 2023), these indices effectively capture key spectral characteristics of vegetation, such as biomass and chlorophyll concentration, which are intricately associated with AGB. Additionally, indices that minimize sensitivity to external factors, such as soil background and atmospheric interference, were prioritized to enhance model robustness and accuracy. Approximately 16 vegetation indices important to plant growth evaluation were examined (Table 1). In this investigation, RGB-based vegetation indices were carefully examined for their ability to evaluate crop biomass. These indices were thoroughly studied as model inputs, allowing for a comparison to determine which indices were the most advantageous. The study’s purpose is to increase the model’s accuracy in predicting phenotypic traits by establishing the optimal indices, providing a reliable framework for analysing plant health and growth dynamics using image-based analysis.
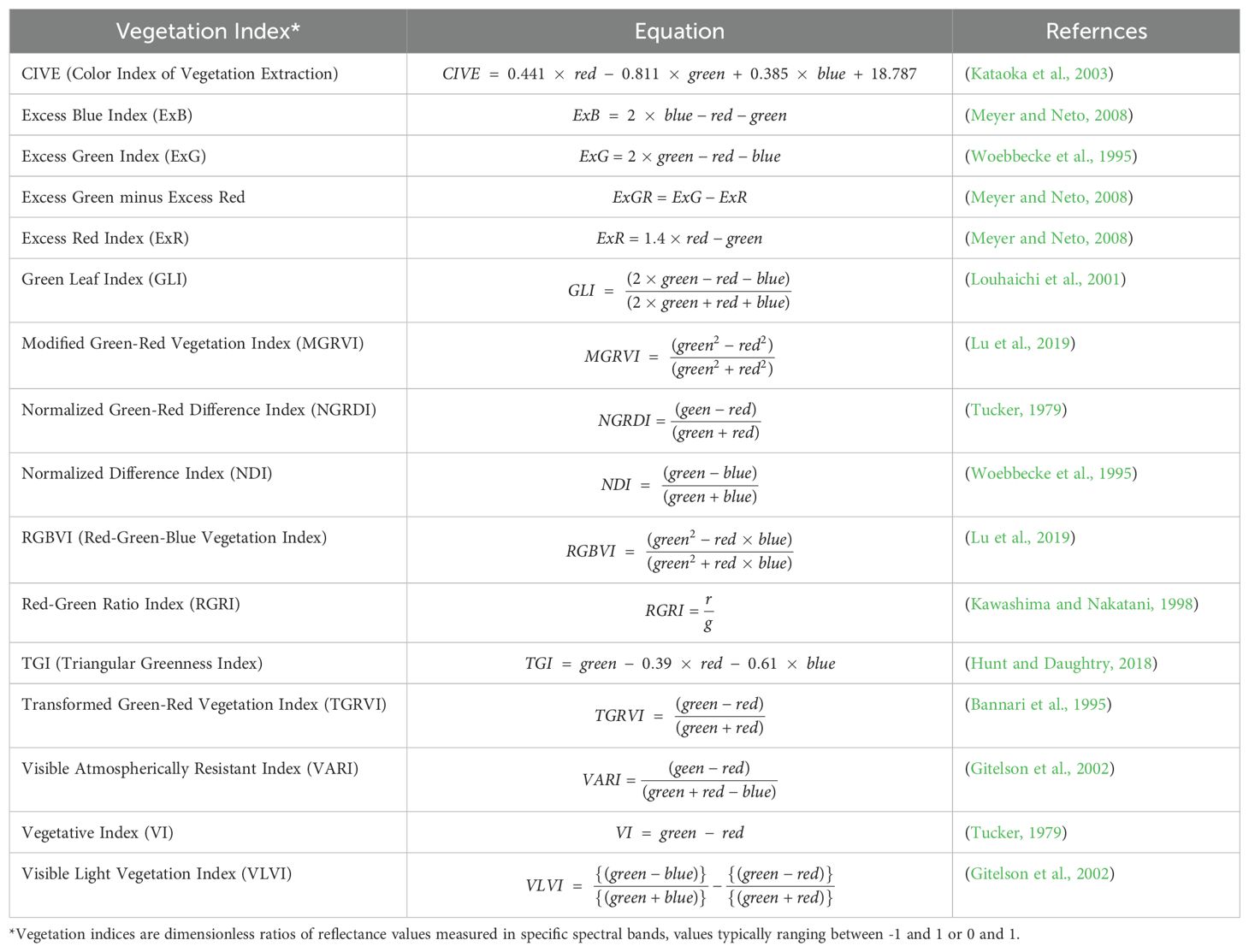
Table 1. Definitions of the vegetation index (Vis) extracted from the RGB images of pearl millet.
2.5 Machine learning regression algorithms
Machine learning regression techniques can effectively describe both linear and nonlinear relationships between predictor variables and crop growth parameters. These methods are especially useful for regression predictions with numerous input variables (Liyew and Melese, 2021; Fragassa et al., 2023; Purushotam et al., 2023; Sharma et al., 2023). We established models to predict the aboveground biomass (AGB) of pearl millet using three shallow machine learning algorithms: Random Forest Regression (RFR), XGBoost, and Support Vector Regression (SVR), as well as one deep learning technique, Convolutional Neural Networks. To assess model accuracy and optimize hyperparameters, we employed a statistical technique called five-fold cross-validation. The process involves randomly dividing a dataset into five subsets, each of which alternates as the test set and the others as the training set. This process is repeated five times to guarantee that all subsets are used completely, and the evaluation metrics from the five tests are then averaged to determine the model’s effectiveness.
A grid search algorithm was utilized to ascertain the optimal hyperparameters. This exploration encompassed a spectrum of parameter configurations, employing five-fold cross-validation and RMSE (Root Mean Square Error) as the principal performance metric. Out of 150 total data specimens, 80% (120 specimens) were designated for training and validation, while the remaining 20% (30 specimens) were reserved as a testing set for evaluating the model’s predictive accuracy on AGB. Python 3.10.12 was used for model creation, feature selection, and data analysis. For regression tasks, the Scikit-learn module (version 1.4) was used, which includes CNN and shallow learning algorithms.
2.6 Statistical analysis
The efficacy of each machine learning model was evaluated using a suite of statistical metrics:
Root Mean Square Error (RMSE): Measures the model’s prediction error magnitude, indicating accuracy in predicting AGB.
Coefficient of Determination (R²): Indicates the proportion of variance explained by the model, providing a measure of fit quality. These measurements were crucial for evaluating model performance, determining which model was best for estimating AGB, and confirming each machine learning algorithm’s capacity to improve the accuracy of biomass prediction for pearl millet.
where Ym, Yp, and Yav represent the measured value, predicted value, and average value, respectively, and n is the total number of data points.
3 Results and discussion
3.1 Evaluation metrics of transfer learning approach
Using transfer learning as a component of our methodology, we used a pre-trained model for predictions in this investigation. We specifically employed SegVeg, which was pre-trained on the VegAnn and ImageNet data sets. The basic feature representations were obtained using the pre-training process employed by the model’s original developers. Because the pre-training dataset includes a variety of classes and item categories, the model can pick up strong low-level and mid-level characteristics that apply to our vegetation segmentation problem, like edges, textures, and patterns. Even though our sample data and the pre-training data did not originate from the same source, the features that were acquired from the extensive pre-training dataset are very applicable to the segmentation of vegetation. This ability to generalize has been shown in several picture segmentation tasks, especially for related domains (Trivedi and Gupta, 2021; Karthik et al., 2022; Serouart et al., 2022; Zenkl et al., 2022; Madec et al., 2023). No new pre-training accuracy was produced in this study because our work focusses on employing pre-trained models without further training on the existing dataset. This investigation now demonstrates how well the pre-trained model segments vegetative sections with a high degree of precision. Our test dataset was used to compute quantitative indicators including Mean IoU, F1 score, and pixel accuracy (Table 2). A comparison that shows how the pre-trained model performed satisfactorily in segmentation without the need for further fine-tuning.
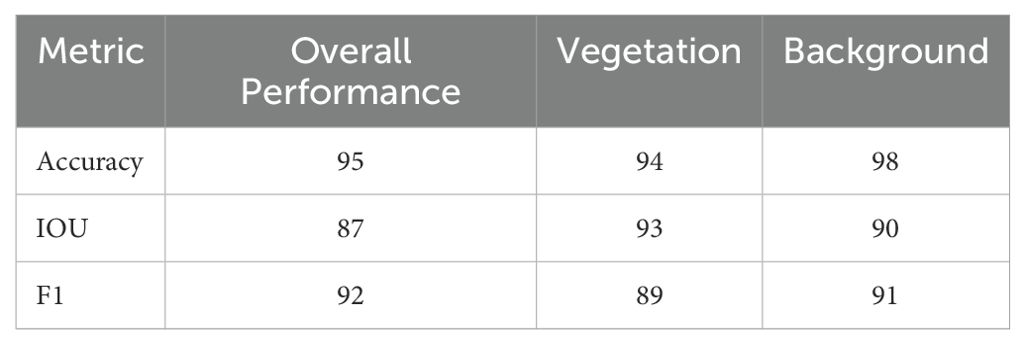
Table 2. Performance metrics for the semantic segmentation.
The model demonstrated strong overall performance in segmenting vegetation and background, achieving 95% overall accuracy, with 94% for vegetation and 98% for background. This suggests that the algorithm properly classifies most pixels, with the background marginally simpler to recognize. The high IoU values indicate a good overlap between predicted and ground truth regions, especially for vegetation, though there is room for improvement in precise boundary delineation. The F1-score shows the model balances precision and recall well but struggles slightly more with vegetation compared to the background. While background is classified with higher accuracy and F1 scores, likely due to its uniform nature and larger representation in the dataset, vegetation performs slightly lower, reflecting challenges in complex textures or overlapping boundaries. These results highlight the model’s reliability but suggest that targeted improvements could further enhance vegetation segmentation performance.
3.2 Summary statistics and correlation analysis between vegetation indices
Table 3 summarizes descriptive statistics for various vegetation indices (VI) used to quantify vegetation characteristics. A correlation matrix showing the correlations between several vegetation indices produced from RGB imagery is shown in Figure 3. This matrix offers a detailed perspective of the relationships between indices. The largest positive association (0.93) was found between AGB and plant height, followed by NGRDI and TGI (0.92), and VARI (0.87). This suggests that these indices are complimentary for vegetation study since they are sensitive to red and green spectral components. AGB and RGRI and ExG have a somewhat positive relationship, suggesting that their measurements may overlap, perhaps in terms of vegetation structure and greenness. AGB has some sensitivity to indices like MGRVI (0.37) that focus on variations in green reflectance but with less precision than other indices. The weak negative correlation of AGB to RGBVI (-0.29) indicates RGBVI may capture distinct traits, possibly related to background noise (e.g., soil or non-vegetative elements) rather than vegetation structure. There is no correlation between ExB and AGB, suggesting that ExB’s sensitivity to vegetative features does not overlap with that of AGB.
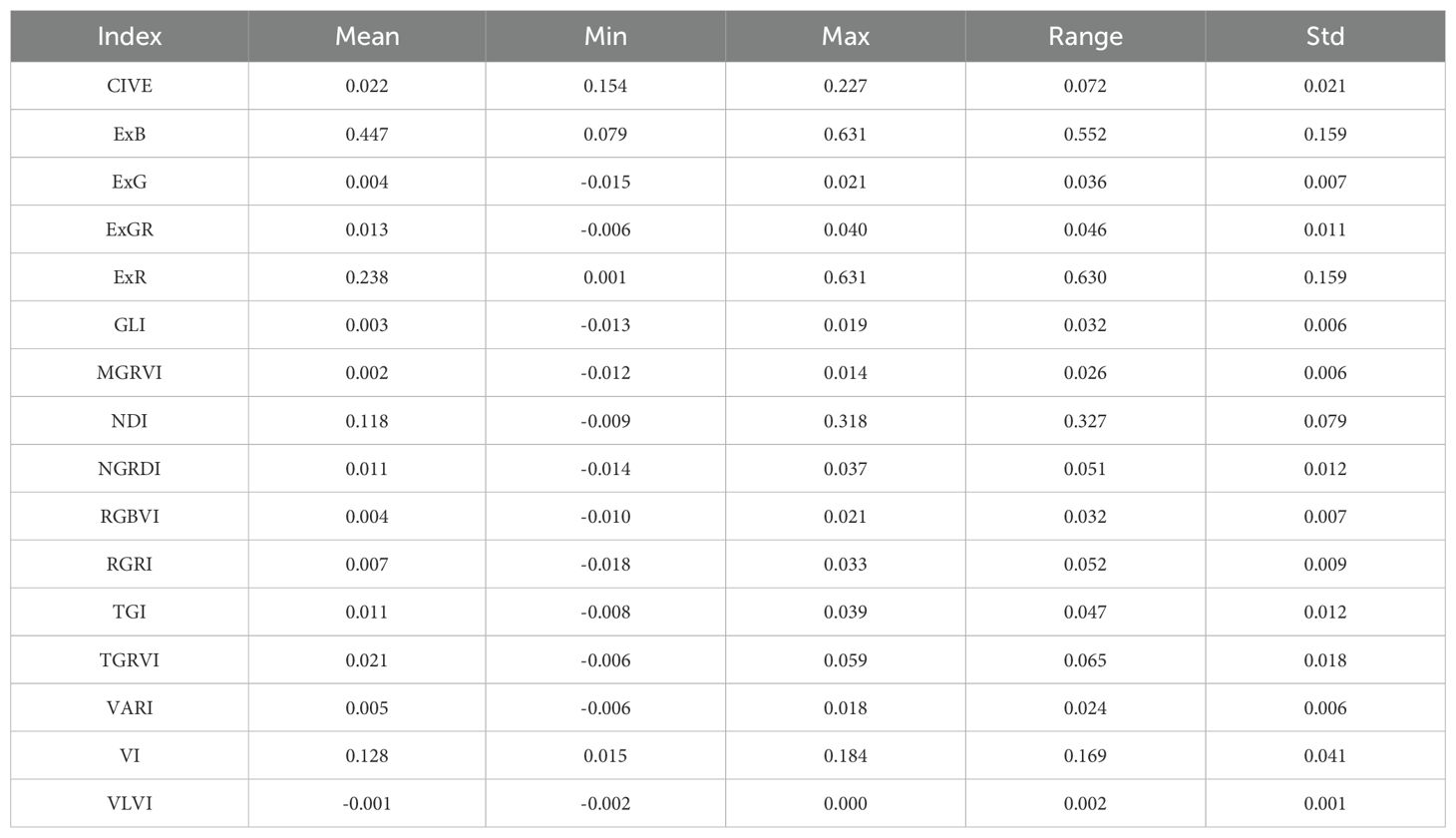
Table 3. Summary statistics for the vegetation indices.
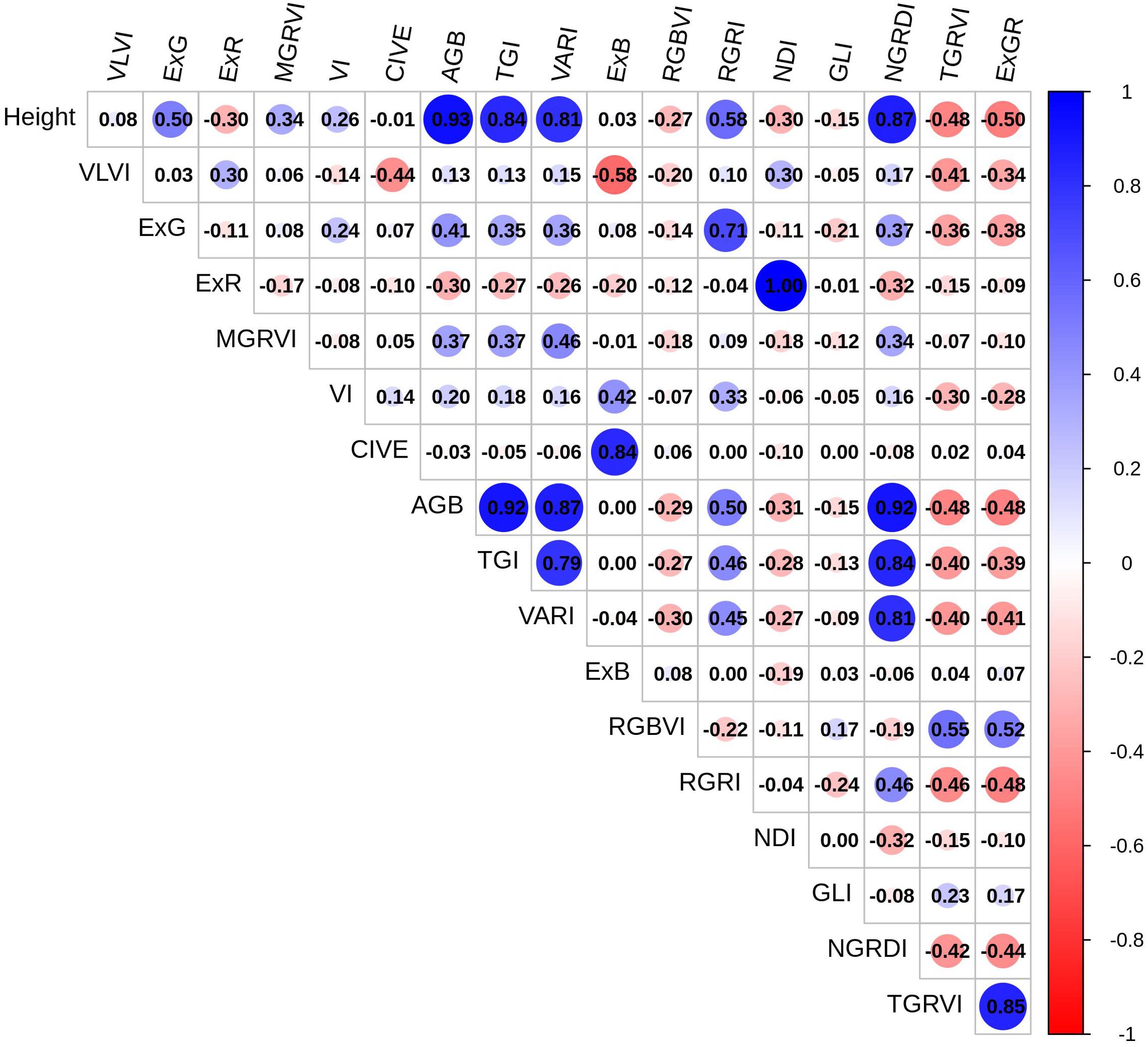
Figure 3. The visualization illustrates a correlation matrix between vegetation metrics and AGB. Red indicates positive correlation, blue indicates negative correlation, and color intensity indicates correlation strength.
Additionally, ABG and TGI are closely connected, exhibiting similar sensitivity to canopy health and chlorophyll. AGB’s high correlation with height (0.93) and other greenness-related indices (NGRDI, TGI, VARI) makes it a robust choice for monitoring biomass, vegetation health, and canopy coverage. Divergent indices, such as RGBVI, ExB, and ExR, on the other hand, do not match AGB and would be better suited for applications that concentrate on pigmentation or stress. According to these results, a mix of indicators with both high and low correlations may provide a more thorough understanding of vegetation health, structure, and stress response.
3.3 Selection of predictors for the AGB biomass estimation using SHAP methodology
In developing predictive models for above-ground biomass (AGB) estimation, the selection of the most relevant predictors is essential to maximize accuracy, reduce noise, and optimize computational efficiency. The Shapley additive explanations (SHAP) technique (Lundberg and Lee, 2017) was used in this investigation to systematically assess predictor significance. A robust interpretive method for machine learning, SHAP assigns significance scores that represent each predictor’s impact on the target variable, allowing for a thorough evaluation of each predictor’s contribution to model predictions (Lundberg and Lee, 2017; Wang et al., 2022a). The SHAP methodology enhances interpretability by highlighting how each feature influences predictions, thereby promoting informed predictor selection. SHAP’s application in this study represents an advancement in the selection process by balancing model interpretability with predictive accuracy. By identifying predictors with the most significant contributions, SHAP aids in isolating those features that most effectively drive AGB predictions, while minimizing the inclusion of uncorrelated or redundant variables. SHAP analysis was performed using the Python package shap. The base model chosen for SHAP analysis in this study was GradientBoostingRegressor from the Python package scikit-learn. All variables were normalized before the SHAP analysis was performed. This was an essential preprocessing step that standardized the scales of the variables to reduce the disproportionate impact of variables with larger magnitudes on the SHAP value calculations.
3.4 SHAP analysis results
Figure 4 provides two visual SHAP representations, offering insights into the significance and impact of each predictor on model outputs. Figure 4A illustrates the average SHAP values assigned to each feature, representing the mean effect of each feature on AGB predictions.
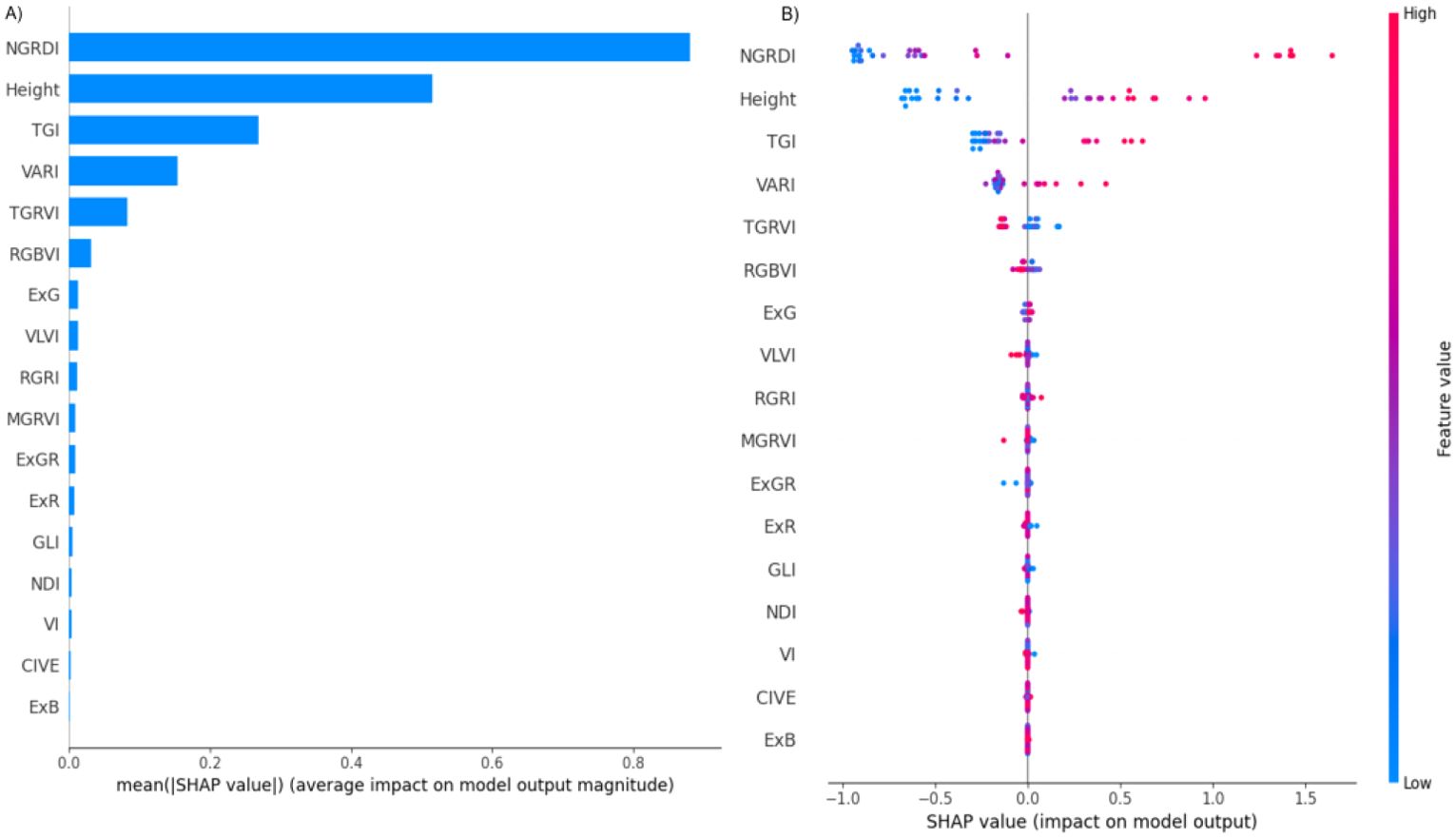
Figure 4. SHAP summary plots display the mean absolute SHAP values for each input feature, representing their average contribution to the model’s prediction of above-ground biomass (AGB). Panel (A) ranks the characteristics based on their overall influence, with higher values indicating greater impact on AGB projections. Panel (B) offers a more granular view, illustrating how individual feature values (represented by colored dots) influence the model output in both positive and negative directions. The color gradient in Panel (B) reflects the magnitude of the feature value (from low to high), enabling interpretation of whether high or low values of a characteristic tend to increase or decrease AGB predictions across all instances.
-NGRDI (Normalized Green-Red Difference Index): NGRDI exhibits the highest average SHAP value, indicating it as the most influential predictor. As a commonly used index in vegetation analysis, NGRDI likely has a strong correlation with AGB, underscoring its critical role in the model’s predictive framework.
Height: Height is ranked as the second most important predictor and has a strong correlation with AGB. This suggests that plant height is directly associated with biomass accumulation, and therefore contributes substantially to model predictions.
TGI (Triangular Greenness Index) and VARI (Visible Atmospherically Resistant Index): These indices follow NGRDI and height in importance. Although their impact is relatively smaller, TGI and VARI contribute valuable information on vegetation greenness, which is pertinent to biomass estimation.
TGRVI (Triangular Green-Red Vegetation Index) and RGBVI (Red-Green-Blue Vegetation Index): These indices demonstrate a moderate influence on model predictions but are less critical than the top-ranked features. They still provide additional insights that may enhance the model’s accuracy by offering different perspectives on plant vigor and color differentiation.
Less Significant Predictors (e.g., ExG, VLVI, RGRI): These features exhibit minimal average SHAP values, indicating a low contribution to AGB predictions. Their limited impact suggests that they may be less relevant or potentially redundant for this specific model, offering little additional predictive power.
The SHAP analysis confirms that the most influential features (such as NGRDI and height) substantially contribute to AGB estimation accuracy, whereas features with low SHAP values may be excluded from the final model to streamline computations without compromising predictive performance. This selective approach, informed by SHAP, enhances model efficiency by concentrating on high-impact predictors, which ultimately improves both the interpretability and accuracy of AGB predictions.
Figure 4B (also called Bee Swarm Plot) offers a more in-depth perspective on how the value of each feature affects the output of the model. Each point depicted in this visualization corresponds to a SHAP value for a specific feature within a single observation, and the points are color-coded based on the feature’s value, ranging from blue for low values to red for high values. The analysis indicates that high values (represented in red) tend to positively influence the model’s output, effectively pushing it to the right, while low values (shown in blue) appear to have a detrimental effect. This observation suggests that elevated NGRDI values are likely associated with higher predictions, which may indicate the presence or overall health of vegetation in the assessed area. Similar to the NGRDI trend, high values of height (represented by red points) generally result in higher model output, implying that taller plants might correlate with higher predictions, thus highlighting the importance of height in the predictive model. The influence of TGI on the model is somewhat more complex and nuanced. While elevated values (red) generally exert a positive impact, the consistency of this effect appears to be less reliable when compared to the clear trends associated with NGRDI or Height. VARI feature exhibits a varied spread of impact values, indicating that both high and low values of VARI can significantly affect the model’s output, although the overall influence seems to be comparatively smaller in magnitude. For those features that register very low SHAP values (for instance, ExG, VLVI, MGRVI), the points are densely clustered around zero. The fact that the points for many of the features that are considered less significant are closely clustered around zero emphasizes that they contribute very little to the model’s output and are typically unaffected by changes in high or low values.
3.5 Estimation of AGB based on machine learning algorithms
In this study, Machine Learning (ML) techniques were applied to estimate the above-ground biomass (AGB) of Pearl millet, utilizing both shallow and deep learning models. ML methodologies facilitate efficient and precise model development, enhancing predictive accuracy across diverse analytical frameworks. Both shallow algorithms, such as Random Forest Regression (RFR), Support Vector Regression (SVR), and XGBoost, as well as deep learning architectures like Convolutional Neural Networks (CNNs) were examined. Shallow algorithms, characterized by their computational efficiency and enhanced interpretability, provide significant benefits in contexts where resources are constrained. Conversely, CNNs are capable of extracting complex patterns from data, making them powerful but resource-intensive (Zhang et al., 2020; Kolhar and Jagtap, 2021). Metrics such as the Root Mean Square Error (RMSE) and coefficient of determination (R2) were employed to compare machine learning algorithms. Figures 5–7 illustrate scatter plots depicting the predictions of each model, comparing both comprehensive and selected feature sets. These scatter plots show the correlation between predicted and observed AGB values. The results indicate strong predictive performance across models, with R² values ranging from 0.82 to 0.98 and RMSE values from 0.20 to 0.70 Mg ha1, reflecting a strong alignment between predicted and actual AGB values.
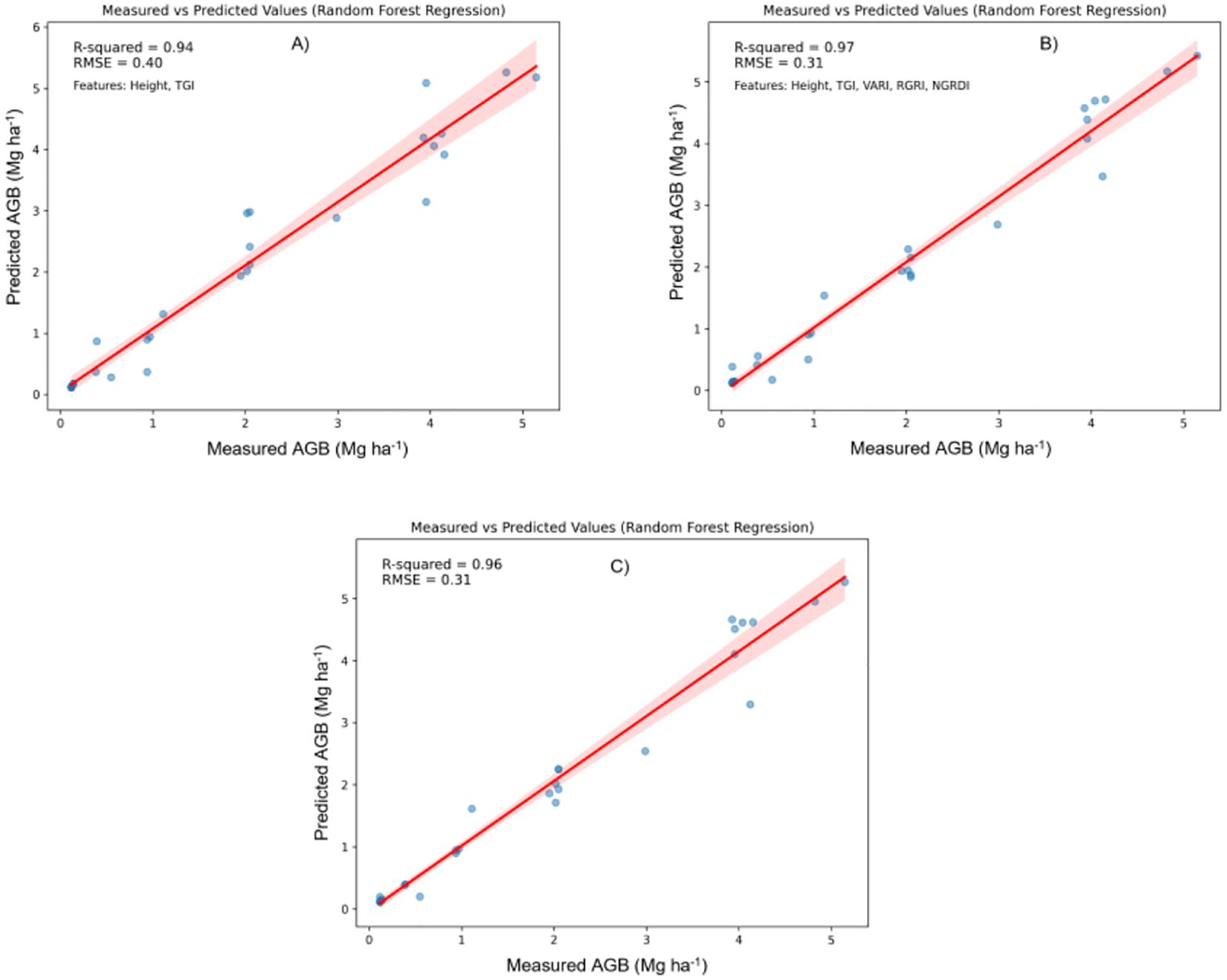
Figure 5. Relationship between measured AGB and predicted AGB using random forest regression (RFR). (A) Two best features; (B) Five best features; (C) all features.
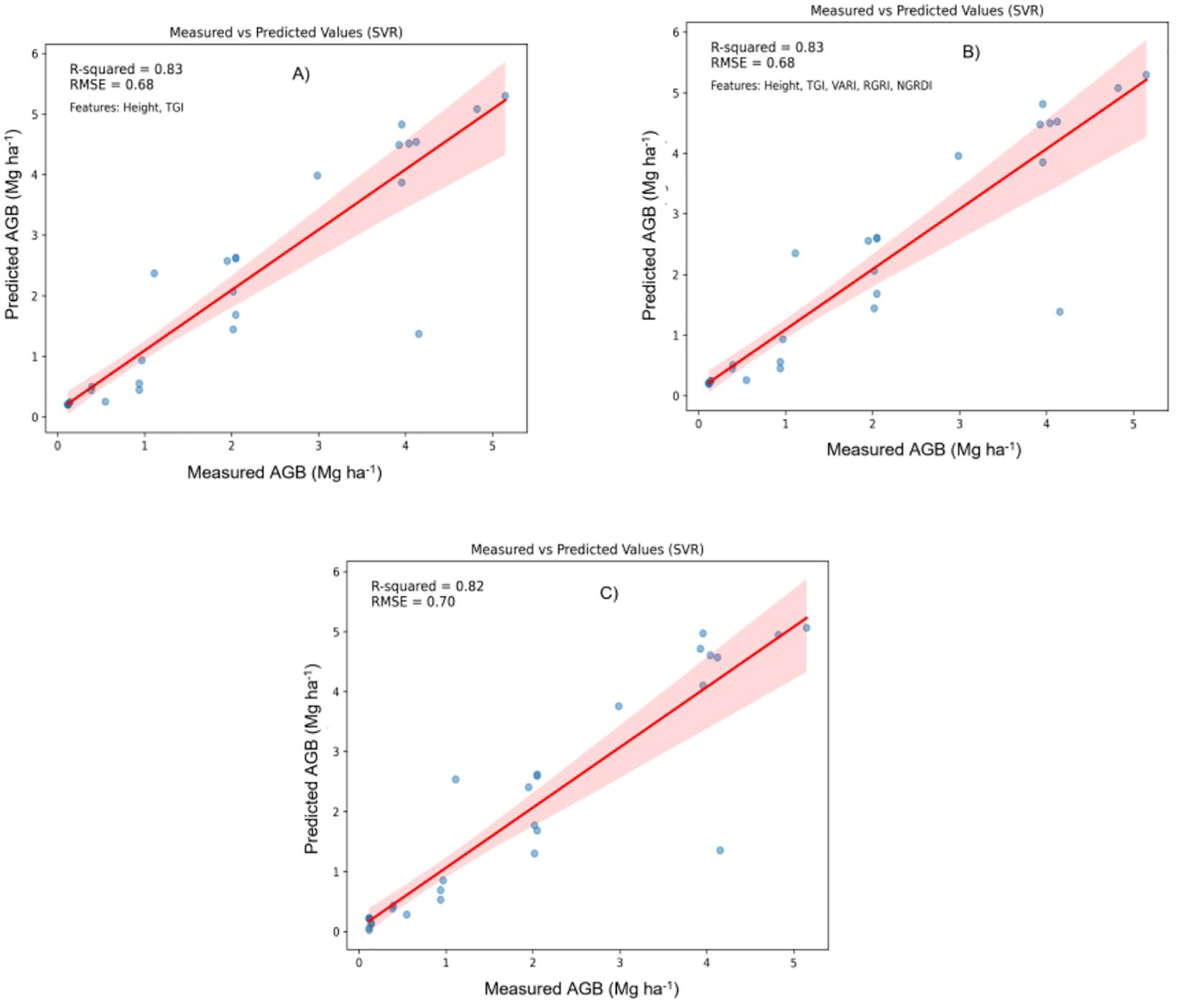
Figure 6. Relationship between measured AGB and predicted AGB using the Support Vector regression (SVR) model. (A) Two best features; (B) Five best features; (C) all features.
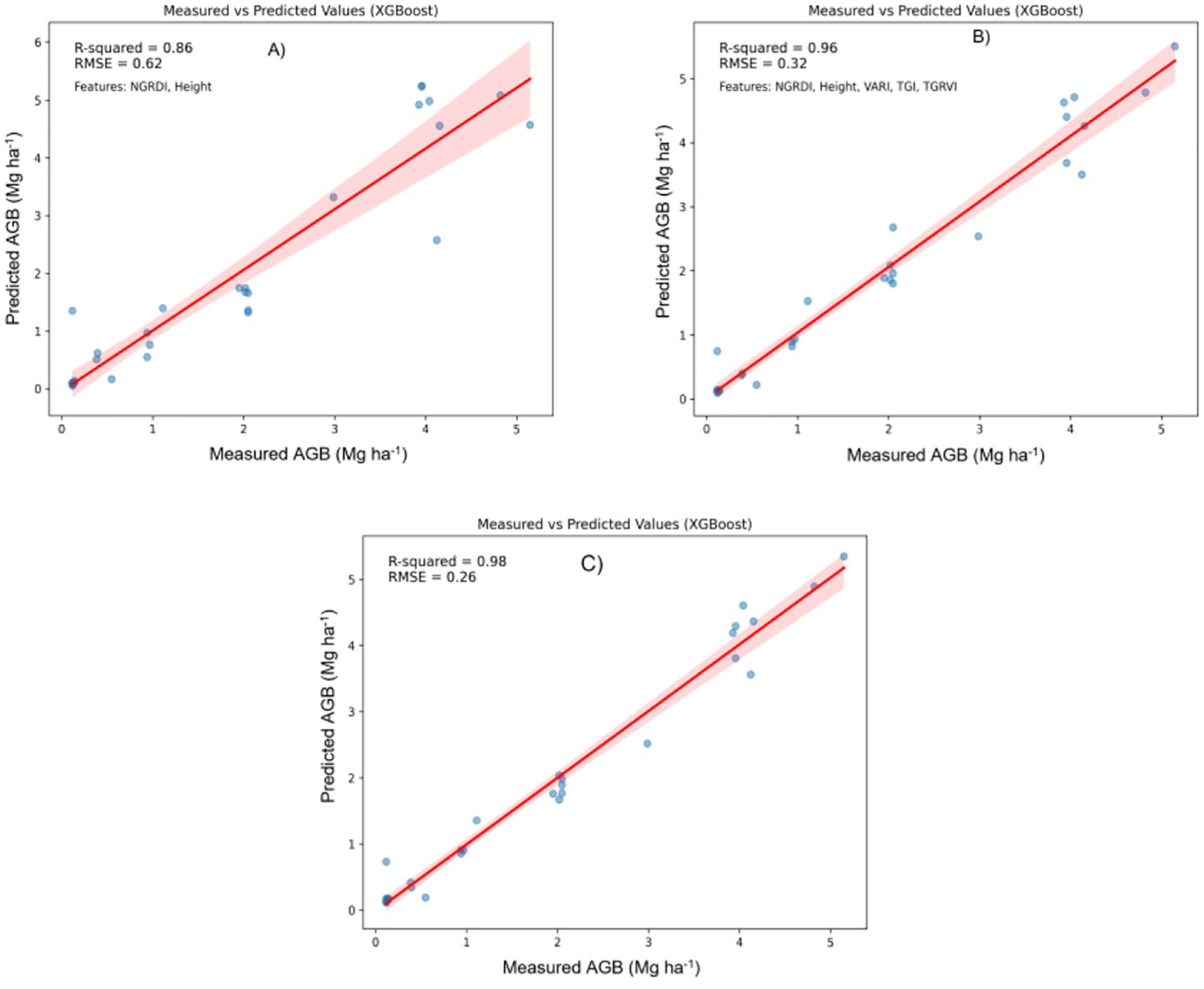
Figure 7. Relationship between measured AGB and predicted AGB using the Extreme Gradient Boosting (XGBoost) model. (A) Two best features; (B) Five best features; (C) all features.
Support Vector Regression (SVR): As shown in Figure 6, SVR demonstrated a broader scatter of sample points, indicating lower precision in AGB predictions. The widespread around the 1:1 regression line suggests that SVR may not capture the underlying relationships as effectively, leading to a relatively less accurate estimation.
Random Forest Regression (RFR) and XGBoost: In contrast, Figures 5 and 7 show that both RFR and XGBoost predictions are closely grouped around the 1:1 line, highlighting their superior performance in regression tasks. These models exhibit less deviation, indicating greater consistency and precision in predicting AGB. Notably, XGBoost demonstrated the highest accuracy, with R² reaching 0.98 and an RMSE of 0.26 Mg ha1, indicating minimal prediction error. The clustering of points around the regression line emphasizes XGBoost’s robust predictive power.
Figure 7 provides additional insights by comparing XGBoost model predictions using the full feature set and a selective subset of features (NGRDI, Height, VARI, TGI, and TGRVI):
Full Feature Set (Figure 7C): The XGBoost model, when utilizing all available features, achieved the highest performance with an R² of 0.98 and an RMSE of 0.26 Mg ha1. This configuration closely aligns with the observed values, as indicated by the tight clustering along the red line in the scatter plot.
Reduced Feature Set (Figures 7A, B): In these plots, the XGBoost model’s performance with a reduced subset of five selected features is also presented. This configuration yielded an R² of 0.96 and an RMSE of 0.32 Mg ha1, a slight reduction in accuracy compared to the full feature model. Nevertheless, this reduced model remains highly effective, maintaining strong alignment with actual AGB measurements. The minimal drop in accuracy suggests that a reduced set of well-chosen features can still provide reliable predictions, particularly in cases where simplicity is prioritized or data constraints exist.
The comparative analysis underscores that incorporating a broader set of features generally improves model accuracy. However, the XGBoost model, using a carefully selected subset of five features, still achieved commendable predictive accuracy. This finding highlights the potential for efficient AGB estimation with fewer predictors, offering a practical solution for scenarios where data availability or computational resources are limited. XGBoost emerged as the most effective model for AGB prediction, demonstrating a strong correlation between predicted and observed values, with minimal error. While incorporating all features maximizes accuracy, the model using the selected five features continues to provide reliable predictions, making it a viable alternative in simplified modelling applications.
3.6 Deep learning approach for biomass estimation using convolutional neural networks
CNNs are largely recognized for processing image data, however, recent research has shown that they can also handle low-dimensional and one-dimensional data effectively by using their capacity to extract hierarchical features and patterns. CNNs have been effectively utilized in tasks involving regression and time series analysis (Srivastava et al., 2022; Purushotam et al., 2023; Sharma et al., 2023). This study proposed a deep learning approach using Convolutional Neural Networks (CNNs) to estimate the aboveground biomass (AGB) of Pearl millet. Vegetative variables were processed through a CNN, leveraging 1-dimensional convolution operations to capture complex, nonlinear interactions among input features. Each input variable was processed independently within the same CNN model, and the resulting CNN outputs were concatenated to form a cohesive predictive representation.
The CNN architecture was implemented in Python (version 3.10.12) using the TensorFlow framework (version 2.17.0). Model weights were initialized with a uniform distribution, while biases were initialized to zero, following standard TensorFlow configuration practices. The Adam optimizer was used for training, with Mean Squared Error (MSE) serving as the loss function. The model was trained for a total of 100 and 200 epochs, with each epoch representing a complete pass through the training dataset, during which model weights were iteratively updated. After each epoch, the model’s validation Root Mean Square Error (RMSE) was computed using a reserved validation dataset to monitor performance independently of the training data. Optimal model parameters were identified based on the minimum validation loss achieved during training. Learning rate decay was applied throughout the training process to gradually reduce the learning rate every 20 epochs, helping the model converge to a minimum. The learning rate decay followed a schedule in which the initial learning rate was sequentially multiplied by 0.8, 0.6, 0.4, and 0.2 at each 20-epoch interval, enabling controlled adjustments to the rate of learning. Hyperparameters, including batch size and initial learning rate, were fine-tuned to optimize model performance. Batch size was varied across values of 8, 16, 32, and 64, while the initial learning rate was tested with values of 0.1, 0.01, 0.001, 0.0001, and 0.00001. The optimal combination of batch size and learning rate was determined based on the model’s predictive accuracy on the test dataset. This combination was then used to train the final CNN model, maximizing accuracy for AGB estimation.
The most accurate model, based on the optimal batch size and learning rate configuration, was selected to predict Pearl millet biomass. The evolution of training and validation losses over the epochs for this model is illustrated in Figure 8. This plot provides insights into the model’s convergence behaviour, showing a consistent reduction in training and validation losses, particularly as the model approaches its optimal configuration. The validation loss trend also demonstrates the model’s capacity to generalize, avoiding overfitting by maintaining stable performance across training iterations.
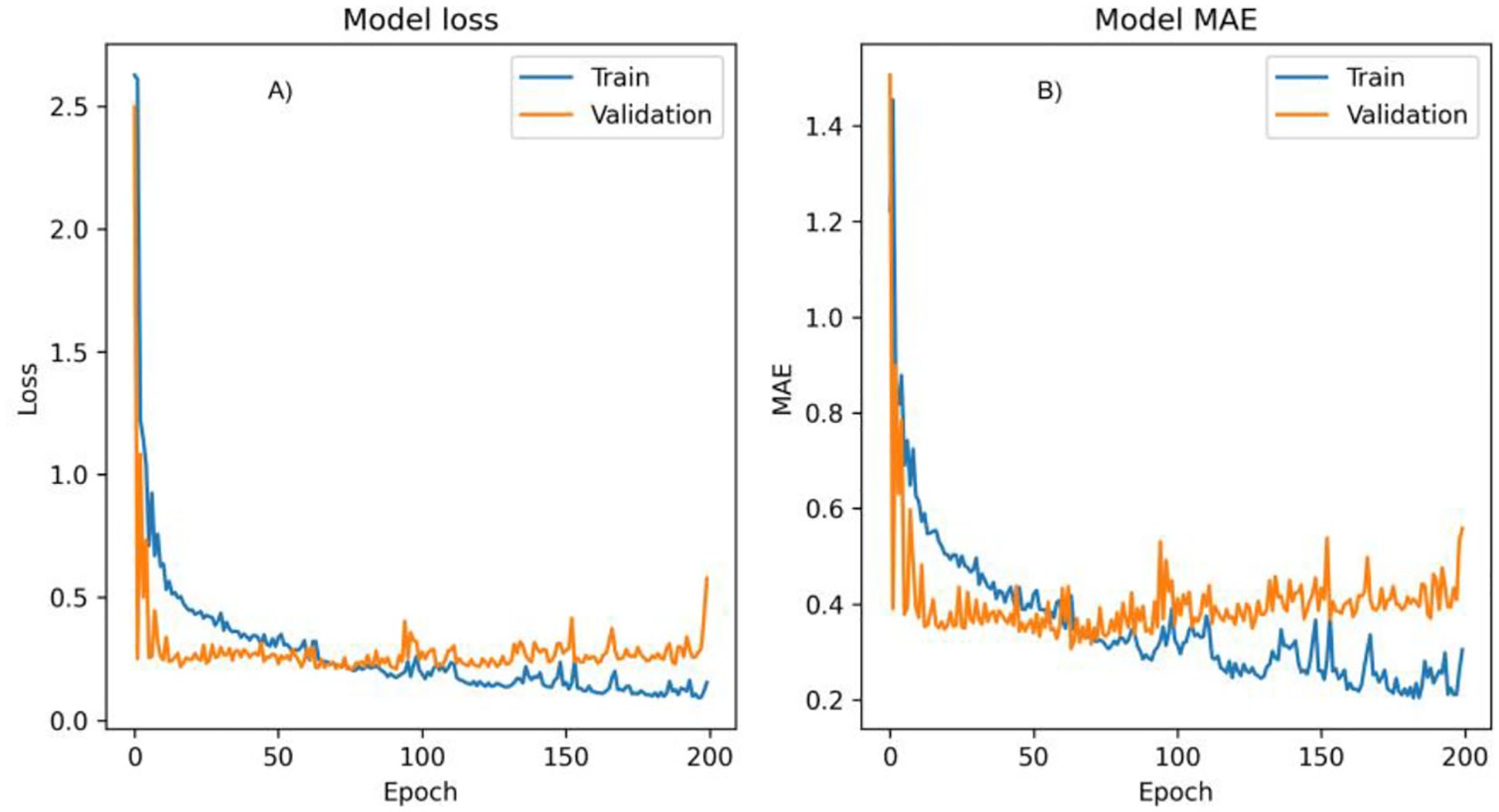
Figure 8. Graph showing the training and validation performance of a model over 200 epochs, showing both loss (A) and Mean Absolute Error (MAE) metrics (B).
3.7 Training and validation performance analysis
Figure 8 illustrates the training and validation performance of the model over 200 epochs, providing insights into the model’s behaviour across both loss and Mean Absolute Error (MAE) metrics.
3.7.1 Model loss plot
The loss plot tracks the model’s loss during training (blue line) and validation (orange line) phases. At the beginning of training, both training and validation losses show a sharp decrease, indicating rapid learning as the model adjusts its parameters to minimize prediction error. Following this initial drop, losses stabilize, fluctuating around lower values, with the training loss consistently remaining below the validation loss. This consistent difference suggests that the model fits well with the training data but may be capturing some patterns that don’t generalize perfectly to the validation set. Towards the end of training, a slight increase in validation loss is observed, possibly indicating the onset of overfitting, where the model becomes more tailored to the training data at the expense of generalization.
3.7.2 Model MAE plot
Similar to the loss plot, the MAE plot shows both training (blue line) and validation MAE (orange line). The MAE starts high for both phases but drops quickly in the initial epochs, suggesting that the model is quickly learning to minimize absolute prediction errors. Throughout training, the training MAE remains consistently lower than the validation MAE, which implies that the model is more accurate on the training data than on the validation data. Some variability is present in both training and validation MAE values across epochs, reflecting minor fluctuations as the model fine-tunes its weights. However, towards the end of training, the validation MAE begins to increase slightly, which may also indicate overfitting.
Both the loss and MAE metrics stabilize early in training, suggesting that the model effectively learns the main patterns in the data within the initial epochs. However, the upward trend in validation loss and MAE towards the end implies a slight overfitting tendency as training continues. This could potentially be mitigated by implementing early stopping or by tuning regularization parameters to prevent the model from overfitting. Figure 8 highlights that while the model rapidly learns and stabilizes, its slight overfitting towards the final epochs suggests a potential area for improvement in future training runs.
The predictive accuracy of the CNN model for estimating above-ground biomass (AGB) on the test dataset is presented in Figure 9. The model shows high effectiveness, evidenced by substantial correlations between measured and predicted AGB values, showcasing the model’s capacity to accurately predict biomass. In Figure 9A, the plot includes height and the Triangular Greenness Index (TGI) as predictors, yielding an R-squared value of 0.90 and a Root Mean Square Error (RMSE) of 0.53. This high R-squared indicates a strong linear relationship between measured and predicted AGB, while the moderate RMSE suggests some error, visualized by the red trendline and associated confidence interval. This configuration demonstrates that height and TGI alone provide a reliable foundation for AGB prediction, though with some degree of residual error.
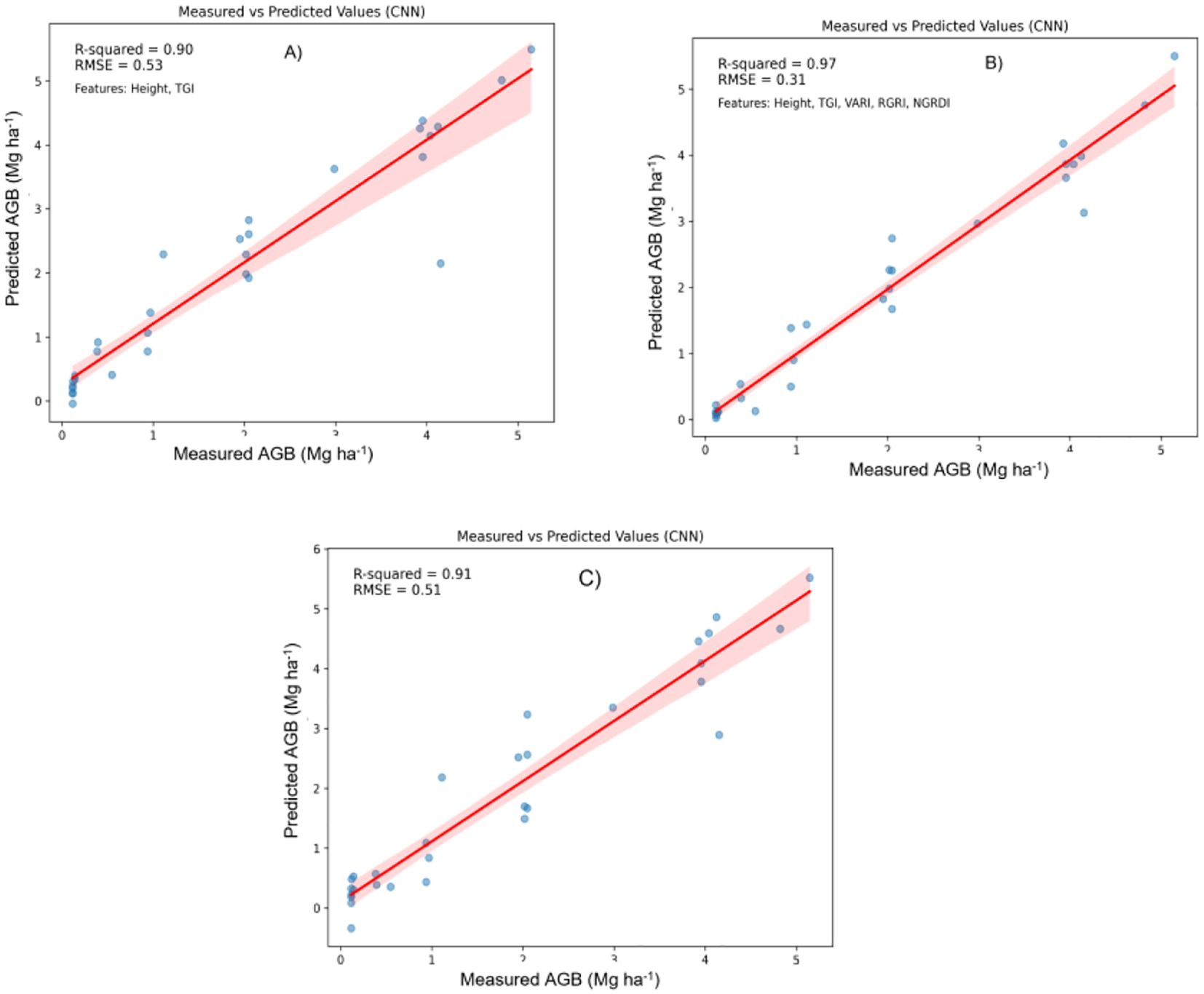
Figure 9. Relationship between measured AGB and predicted AGB using Convolutional neural networks (CNNs) model. (A) Two best features; (B) Five best features; (C) all features.
By incorporating height, TGI, Visible Atmospherically Resistant Index (VARI), Red-Green Ratio Index (RGRI), and Normalized Green-Red Difference Index (NGRDI), this configuration achieves superior predictive performance. The R-squared increases to 0.97, and the RMSE drops to 0.31, indicating a very close match between measured and predicted values. This improvement suggests that these five features capture a broader range of vegetation characteristics, enhancing model accuracy and reducing error. The increased R-squared and lower RMSE indicate that the model effectively leverages additional indices to improve AGB prediction.
In Figure 9C, the plot utilizes all available features, resulting in an R-squared of 0.91 and an RMSE of 0.51. While this setup slightly outperforms, Figure 9A shows lower performance compared to the configuration in Figure 9B. This suggests that adding more features beyond the five used in Figure 9B may introduce noise or redundancy, slightly reducing the model’s predictive efficiency.
The integration of five features (height, TGI, VARI, RGRI, and NGRDI) provides the highest predictive accuracy, as shown by the highest R-squared (0.97) and lowest RMSE (0.31) values. This configuration strikes an optimal balance, where the addition of indices beyond height and TGI significantly enhances the model’s predictive power, but including all features yields only a marginal improvement. Each plot demonstrates a positive relationship between measured and predicted AGB, with confidence intervals representing the inherent uncertainty in predictions. Overall, these findings suggest that a focused set of relevant indices can achieve high model performance, with the five-feature configuration proving the most effective for accurate AGB estimation.
3.8 Evaluation and comparison of machine learning models for estimating above-ground biomass
Table 4 provides a comparative analysis of four machine learning models—Random Forest Regression (RFR), Support Vector Regression (SVR), XGBoost, and Convolutional Neural Networks (CNNs)—in estimating AGB using different feature sets: all features, the five most significant features, and the two most salient features. Performance metrics are reported as R² (coefficient of determination) and RMSE (root mean square error).

Table 4. AGB estimation accuracy using different machine learning algorithms.
All Features: XGBoost achieved the highest accuracy (R² = 0.98, RMSE = 0.26), followed by RFR (R² = 0.96, RMSE = 0.31). CNNs exhibited moderate performance (R² = 0.91, RMSE = 0.51), and SVR was the least effective (R² = 0.82, RMSE = 0.70). These results indicate that XGBoost benefits from the complete feature set, leveraging its robust gradient-boosting framework to minimize errors effectively.
Five Most Significant Features: Both RFR and CNNs demonstrated high accuracy, with R² ≈ 0.97 and RMSE ≈ 0.31. XGBoost performed slightly lower (R² = 0.96, RMSE = 0.32), while SVR continued to lag (R² = 0.83, RMSE = 0.68). The comparable performance of RFR and CNNs with fewer features suggests that they are capable of effective prediction without requiring a full feature set, making them adaptable for resource-constrained scenarios.
Two Most Significant Features: RFR emerged as the top performer, achieving R² = 0.94 and RMSE = 0.20. XGBoost and CNNs showed declines in performance, with CNNs reaching an R² of 0.90 and RMSE of 0.53, while SVR maintained its relatively low performance (R² = 0.83, RMSE = 0.68). This result indicates that RFR retains accuracy even with a reduced feature set, highlighting its flexibility and robustness.
Multivariate features have more predictive power for AGB than single variable features, as shown in earlier investigations (Lu et al., 2019). Similarly, when evaluating biophysical crop parameters, (Han et al., 2019). stressed that vegetation indices of photographs might be taken into account simultaneously rather than separately. Consistent with earlier research, plant height has a major impact on biomass yield, making it a significant agricultural architecture that is strongly connected with biomass yield (Montes et al., 2011; Schirrmann et al., 2016; Naito et al., 2017; Lu et al., 2019; Yu et al., 2023). (Schirrmann et al., 2016). showed that the estimation accuracy could be effectively increased by incorporating plant height into the model designed to estimate AGB. Similar findings were made by (Naito et al., 2017). and (Yu et al., 2023).
3.9 Overall summary of model performance
Estimating AGB accurately is essential for understanding carbon sequestration and enhancing agricultural management (Ortiz-Ulloa et al., 2021; Funes et al., 2022; Chopra et al., 2023). XGBoost performs best with a comprehensive feature set, achieving superior predictive accuracy with an R² of 0.98 and RMSE of 0.26. This is attributed to its advanced gradient-boosting approach, which integrates multiple weak learners to minimize errors through sequential corrections (Wang et al., 2022a; Sharma et al., 2023). XGBoost uses a combination of a loss function and a regularization term to prevent overfitting, enhanced by features such as gradient descent optimization, column subsampling, and shrinkage for improved convergence and stability. Additionally, XGBoost’s ability to handle missing data and optimize tree structure through parallel processing adds to its effectiveness. RFR shows superior performance with a reduced feature set, indicating a high level of adaptability. With its ensemble-based structure, RFR combines predictions from multiple decision trees, effectively capturing nonlinear relationships in the data and reducing sensitivity to noise (Chiu and Wang, 2024). This adaptability makes RFR a suitable choice when computational resources are limited or when fewer predictor variables are available. SVR consistently underperforms in comparison to other models across all feature sets (R² = 0.82–0.83, RMSE = 0.68–0.70). As a linear regression model, SVR struggles with the complex nonlinear relationships inherent in the dataset, which limits its accuracy. Its susceptibility to outliers and reliance on linear transformations may explain its lower performance (Liu et al., 2021). CNNs perform moderately well across different feature sets, showing potential for improvement with further tuning (Carlier et al., 2023). CNNs excel at extracting complex features from data, which is beneficial for tasks involving unstructured data (such as images) but may be less suited for purely tabular data where tree-based models like XGBoost and RFR perform better. Overall, the observed differences in performance indicate that nonlinear regression models outperform linear alternatives like SVR, consistent with findings from prior studies (Lu et al., 2019; Nakajima et al., 2023). This is consistent with (Zhai et al., 2023)’s findings that the RFR approach performed better than alternative machine learning algorithms, resulting in increased AGB estimation accuracy.
3.10 Limitations and perspectives
Vegetation indices (VIs) are effective for estimating aboveground biomass (AGB) because they are designed to highlight specific spectral features of vegetation that correlate with biomass attributes. Studies have shown that the inclusion of red-edge and NIR bands further improves the sensitivity of indices to variations in biomass and reduces the influence of confounding factors such as soil background and atmospheric conditions (Woebbecke et al., 1995; Hamuda et al., 2016; Yue et al., 2017; Lu et al., 2019). The current study focuses on one-dimensional VI combinations, potentially overlooking spatial patterns available in raw spectral imagery. Future studies could explore integrating data from multiple sensors (e.g., hyperspectral and multispectral imagery) which could enhance the accuracy and robustness of AGB estimation. Investigating newer indices tailored for specific vegetation types or environmental conditions could address limitations in biomass estimation under extreme conditions.
XGBoost emerged as the best-performing model, with high R² and low RMSE values. Key features contributing to XGBoost’s success include its capability to aggregate weak learners, implement gradient boosting, and minimize an objective function that combines a loss function with regularization. However, XGBoost’s computational demands are significant, requiring substantial memory and processing power, particularly for large or high-dimensional datasets. The extensive hyperparameter tuning required for XGBoost further necessitates considerable expertise and computational resources. Moreover, XGBoost is less effective for unstructured data, such as images, where deep learning architectures like CNNs generally perform better. Moreover, this study primarily focuses on one-dimensional data regression analysis and does not explore two-dimensional data analysis methods for AGB prediction modelling. This limits the potential advantages of using CNN over XGBoost, as CNNs are specifically well-suited for extracting spatial features from two-dimensional data.
This study’s methodology highlights the potential for farmers to use accessible technologies, such as smartphone devices, and enter them into automated biomass prediction algorithms, which could serve as the foundation for carbon sequestration inventories. The integration of machine learning algorithms into agricultural practices could facilitate the creation of automated AGB estimation systems, providing accurate biomass predictions essential for precision agriculture (Lu et al., 2019; Fragassa et al., 2023; Purushotam et al., 2023; Sharma et al., 2023). Even with noise-prone image data, the models demonstrated satisfactory accuracy, supporting the feasibility of using smartphone-acquired images for AGB estimation in field setting. The current study focuses on a single crop variety under controlled growth conditions, which was a deliberate choice to ensure the feasibility of the study within the given scope and resources. Future research could also explore the application of this framework on a larger scale by incorporating data from diverse environmental conditions, multiple crop varieties, crop growth stages, and geographical regions to assess the model’s generalizability. Expanding the dataset to include multispectral or hyperspectral imagery could further improve model accuracy by capturing additional vegetation characteristics. Integrating real-time monitoring systems through IoT-enabled sensors with machine learning models could provide continuous, automated AGB estimations, aiding decision-making in dynamic agricultural environments. Lastly, implementing transfer learning with other advanced neural networks or refining hyperparameters may enhance the predictive performance of CNNs, particularly in estimating biomass in unstructured and complex agricultural settings.
4 Conclusions
In conclusion, this study proposes a non-destructive framework for forecasting above-ground biomass (AGB) in pearl millet by combining Convolutional Neural Networks (CNNs) with shallow machine-learning methods. The results show that sophisticated deep learning approaches like CNNs, when combined with machine learning, particularly tree-based algorithms like XGBoost, may provide reliable AGB predictions. XGBoost outperformed other models when a comprehensive feature set was utilized, achieving the highest R² and the lowest RMSE values. Random Forest Regression (RFR) demonstrated effectiveness with reduced feature sets, highlighting its versatility and efficacy under data-constrained scenarios.
In summary, this study emphasizes the potential of readily available digital technologies, such as smartphone-acquired photos, to support automated biomass prediction and real-time crop monitoring. The unique characteristics of small farming systems, such as diverse cropping patterns, agroforestry practices, and integrated livestock, play a crucial role in carbon dynamics. These tools could form the basis for small-scale carbon inventories to measure the carbon sequestered within vegetation biomass in smallholder agricultural systems. These inventories are crucial for understanding how agricultural practices contribute to carbon sequestration at the local level and for informing climate-resilient strategies.
Data availability statement
The original contributions presented in the study are included in the article/Supplementary Material. Further inquiries can be directed to the corresponding authors.
Author contributions
AG: Software, Funding acquisition, Formal Analysis, Writing – original draft, Resources, Project administration, Visualization, Supervision, Methodology, Investigation, Validation, Writing – review & editing, Conceptualization, Data curation. FD: Conceptualization, Validation, Funding acquisition, Resources, Supervision, Writing – review & editing, Software, Project administration. NA: Conceptualization, Investigation, Data curation, Software, Writing – original draft, Methodology. SAli: Formal Analysis, Writing – review & editing, Methodology, Conceptualization, Software, Investigation. SAlq: Data curation, Methodology, Software, Investigation, Writing – review & editing.
Funding
The author(s) declare that financial support was received for the research and/or publication of this article. This work was supported by the Deanship of Scientific Research, Vice Presidency for Graduate Studies and Scientific Research at King Faisal University, Saudi Arabia (Grant No. KFU242431). The authors extend their appreciation to Abdulmonem Alrashed Humanitarian Foundation (FSP-2-0023).
Acknowledgments
We would like to extend our heartfelt gratitude to Noor Alabdrabulridha, Munirah Alyousif, and Zainab Alabdulaziz for their invaluable assistance in setting up the experiment and gathering data as part of the Future Scientists Program, which was conducted at King Faisal University in partnership with the Abdulmonem Alrashed Humanitarian Foundation
Conflict of interest
The authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
Generative AI statement
The author(s) declare that no Generative AI was used in the creation of this manuscript.
Publisher’s note
All claims expressed in this article are solely those of the authors and do not necessarily represent those of their affiliated organizations, or those of the publisher, the editors and the reviewers. Any product that may be evaluated in this article, or claim that may be made by its manufacturer, is not guaranteed or endorsed by the publisher.
Supplementary material
The Supplementary Material for this article can be found online at: https://www.frontiersin.org/articles/10.3389/fpls.2025.1594728/full#supplementary-material
References
Ali, E. F., Al-Yasi, H. M., Kheir, A. M. S., Eissa, M. A. (2021). Effect of biochar on CO2 sequestration and productivity of pearl millet plants grown in saline sodic soils. J. Soil Sci. Plant Nutr. 21, 897–907. doi: 10.1007/s42729-021-00409-z
Alves, K. S., Guimarães, M., Ascari, J. P., Queiroz, M. F., Alfenas, R. F., Mizubuti, E. S. G., et al. (2021). RGB-based phenotyping of foliar disease severity under controlled conditions. Trop. Plant Pathol. 47, 105–117. doi: 10.1007/s40858-021-00448-y
Bannari, A., Morin, D., Bonn, F., Huete, A. R. (1995). A review of vegetation indices - Remote Sensing Reviews. Remote Sens. Rev. 13 (1-2), 95–120. doi: 10.1080/02757259509532298
Bazzo, C. O. G., Kamali, B., Hütt, C., Bareth, G., Gaiser, T. (2023). A review of estimation methods for aboveground biomass in grasslands using UAV. Remote Sens. 15 (3), 639. doi: 10.3390/rs15030639
Carlier, A., Dandrifosse, S., Dumont, B., Mercatoris, B. (2023). Comparing CNNs and PLSr for estimating wheat organs biophysical variables using proximal sensing. Front. Plant Sci. 14. doi: 10.3389/fpls.2023.1204791
Castro, W., Marcato Junior, J., Polidoro, C., Osco, L. P., Gonçalves, W., Rodrigues, L., et al. (2020). Deep learning applied to phenotyping of biomass in forages with UAV-based RGB imagery. Sensors 20, 4802. doi: 10.3390/s20174802
Chiu, M. S., Wang, J. (2024). Evaluation of machine learning regression techniques for estimating winter wheat biomass using biophysical, biochemical, and UAV multispectral data. Drones 8, 287. doi: 10.3390/drones8070287
Chopra, N., Tewari, L. M., Tewari, A., Wani, Z. A., Asgher, M., Pant, S., et al. (2023). Estimation of Biomass and Carbon Sequestration Potential of Dalbergia latifolia Roxb. and Melia composita Willd. Plantations in the Tarai Region (India). Forests 14. doi: 10.3390/f14030646
Deevi, K. C., Swamikannu, N., Pingali, P. R., Gumma, M. K. (2024). “Current Trends and Future Prospects in Global Production, Utilization, and Trade of Pearl Millet,” in Pearl Millet in the 21st Century (Singapore: Springer Nature Singapore), 1–33. doi: 10.1007/978-981-99-5890-0_1
Fragassa, C., Vitali, G., Emmi, L., Arru, M. (2023). A new procedure for combining UAV-based imagery and machine learning in precision agriculture. Sustain. 15 (2), 998. doi: 10.3390/su15020998
Fry, J. C. (1990). Direct methods and biomass estimation. Methods Microbiol. 22, 41–85. doi: 10.1016/S0580-9517(08)70239-3
Funes, I., Molowny-Horas, R., Savé, R., De Herralde, F., Aranda, X., Vayreda, J. (2022). Carbon stocks and changes in biomass of Mediterranean woody crops over a six-year period in NE Spain. Agron. Sustain. Dev. 42, 98. doi: 10.1007/s13593-022-00827-y
Gang, M. S., Kim, H. J., Kim, D. W. (2022). Estimation of greenhouse lettuce growth indices based on a two-stage CNN using RGB-D images. Sensors 22. doi: 10.3390/s22155499
Gerardo, R., de Lima, I. P. (2023). Applying RGB-based vegetation indices obtained from UAS imagery for monitoring the rice crop at the field scale: A case study in Portugal. Agric. 13 (10), 1916. doi: 10.3390/agriculture13101916
Gitelson, A. A., Kaufman, Y. J., Stark, R., Rundquist, D. (2002). Novel algorithms for remote estimation of vegetation fraction. Remote Sens. Environ. 80, 76–87. doi: 10.1016/s0034-4257(01)00289-9
Gonten, F., Nfwan, F., Ya’u Gital, A. (2024). Pre-review convolutional neural network for detecting object in image comprehensive survey and analysis. J. Inf. Syst. Technol. Res. 3, 45–64. doi: 10.55537/jistr.v3i2.799
Gülmez, B. (2024). Advancements in rice disease detection through convolutional neural networks: A comprehensive review. Heliyon 10, e33328. doi: 10.1016/j.heliyon.2024.e33328
Hamuda, E., Glavin, M., Jones, E. (2016). A survey of image processing techniques for plant extraction and segmentation in the field. Comput. Electron. Agric. 125, 184–199. doi: 10.1016/j.compag.2016.04.024
Han, L., Yang, G., Dai, H., Xu, B., Yang, H., Feng, H., et al. (2019). Modeling maize above-ground biomass based on machine learning approaches using UAV remote-sensing data. Plant Methods 15. doi: 10.1186/s13007-019-0394-z
Harris, C. R., Millman, K. J., van der Walt, S. J., Gommers, R., Virtanen, P., Cournapeau, D., et al. (2020). Array programming with numPy. Nature 585 (7825), 357–362. doi: 10.1038/s41586-020-2649-2
Hunt, E. R., Jr., Daughtry, C. S. T. (2018). What good are unmanned aircraft systems for agricultural remote sensing and precision agriculture? Int. J. Remote Sens. 39 (15-16), 5345–5376. doi: 10.1080/01431161.2017.1410300
Issaoui, H., ElAdel, A., Zaied, M. (2024). “Object detection using convolutional neural networks: A comprehensive review,” in 2024 IEEE 27th International Symposium on Real-Time Distributed Computing (ISORC). 1–6. (Piscataway, New Jersey, USA: IEEE). doi: 10.1109/isorc61049.2024.10551342
Jimenez-Sierra, D. A., Correa, E. S., Benítez-Restrepo, H. D., Calderon, F. C., Mondragon, I. F., Colorado, J. D. (2021). Novel feature-extraction methods for the estimation of above-ground biomass in rice crops. Sensors 21 (13), 4369. doi: 10.3390/s21134369
Karthik, P., Parashar, M., Reka, S. S., Rajamani, K. T., Heinrich, M. P. (2022). Semantic segmentation for plant phenotyping using advanced deep learning pipelines. Multimed. Tools Appl. 81. doi: 10.1007/s11042-021-11770-7
Kataoka, T., Kaneko, T., Okamoto, H., Hata, S. (2003). “Crop growth estimation system using machine vision,” in Proceedings 2003 IEEE/ASME international conference on advanced intelligent mechatronics (AIM 2003) 2, b1079–b1083. doi: 10.1109/AIM.2003.1225492
Kawashima, S., Nakatani, M. (1998). An algorithm for estimating chlorophyll content in leaves using a video camera. Ann. Bot. 81 (1), 49–54. doi: 10.1006/anbo.1997.0544
Kaya, Y., Gürsoy, E. (2023). A novel multi-head CNN design to identify plant diseases using the fusion of RGB images. Ecol. Inform. 75, 101998. doi: 10.1016/j.ecoinf.2023.101998
Kefauver, S. C., El-Haddad, G., Vergara-Diaz, O., Araus, J. L. (2015). “RGB picture vegetation indexes for High-Throughput Phenotyping Platforms (HTPPs),” in Remote sensing for agriculture, ecosystems, and hydrology XVII. Eds. Neale, C. M. U., Maltese, A. (SPIE). doi: 10.1117/12.2195235
Khaki, S., Wang, L., Archontoulis, S. V. (2020). A CNN-RNN framework for crop yield prediction. Front. Plant Sci. 10. doi: 10.3389/fpls.2019.01750
Kolhar, S., Jagtap, J. (2021). Convolutional neural network based encoder-decoder architectures for semantic segmentation of plants. Ecol. Inform. 64, 101–373. doi: 10.1016/j.ecoinf.2021.101373
Kumari, T., Kannan, M. J., Vinutha, N. (2022). A survey on plant leaf disease detection. Int. J. Comput. Appl. 184 (17). doi: 10.5120/ijca2022922170
LeCun, Y., Bengio, Y., Hinton, G. (2015). Deep learning. Nature 521, 436–444. doi: 10.1038/nature14539
Liu, S., Jin, X., Nie, C., Wang, S., Yu, X., Cheng, M., et al. (2021). Estimating leaf area index using unmanned aerial vehicle data: Shallow vs. Deep machine learning algorithms. Plant Physiol. 187 (3), 1551–1576. doi: 10.1093/plphys/kiab322
Liu, Y., Feng, H., Yue, J., Jin, X., Li, Z., Yang, G. (2022). Estimation of potato above-ground biomass based on unmanned aerial vehicle red-green-blue images with different texture features and crop height. Front. Plant Sci. 13, 938–216. doi: 10.3389/fpls.2022.938216
Liyew, C. M., Melese, H. A. (2021). Machine learning techniques to predict daily rainfall amount. J. Big Data 8, 1–11. doi: 10.1186/s40537-021-00545-4
Lorenz, K., Lal, R. (2014). Soil organic carbon sequestration in agroforestry systems. A review. Agron. Sustain. Dev. 34, 443–454. doi: 10.1007/s13593-014-0212-y
Louhaichi, M., Borman, M. M., Johnson, D. E. (2001). Spatially located platform and aerial photography for documentation of grazing impacts on wheat. Geocarto Int. 16, 65–70. doi: 10.1080/10106040108542184
Lu, N., Zhou, J., Han, Z., Li, D., Cao, Q., Yao, X., et al. (2019). Improved estimation of aboveground biomass in wheat from RGB imagery and point cloud data acquired with a low-cost unmanned aerial vehicle system. Plant Methods 15, 17. doi: 10.1186/s13007-019-0402-3
Lundberg, S. M., Lee, S. I. (2017). A unified approach to interpreting model predictions. Adv. Neural Inf. Process. Systems. doi: 10.48550/arXiv.1705.07874
Ma, Z., Cao, Y., Rayhana, R., Liu, Z., Xiao, G. G., Ruan, Y., et al. (2023). “Automated biomass estimation through depth measurement with an OAK-D camera,” in 2023 IEEE international symposium on robotic and sensors environments (ROSE) (IEEE), 1–6. doi: 10.1109/rose60297.2023.10410733
Madec, S., Irfan, K., Velumani, K., Baret, F., David, E., Daubige, G., et al. (2023). VegAnn, Vegetation Annotation of multi-crop RGB images acquired under diverse conditions for segmentation. Sci. Data 10. doi: 10.1038/s41597-023-02098-y
Meyer, G. E., Neto, J. C. (2008). Verification of color vegetation indices for automated crop imaging applications. Comput. Electron. Agric. 63, 282–293. doi: 10.1016/j.compag.2008.03.009
Montes, J. M., Technow, F., Dhillon, B. S., Mauch, F., Melchinger, A. E. (2011). High-throughput non-destructive biomass determination during early plant development in maize under field conditions. F. Crop Res. 121 (2), 268–273. doi: 10.1016/j.fcr.2010.12.017
Morbekar, A., Parihar, A., Jadhav, R. (2020). “Crop disease detection using YOLO,” in 2020 international conference for emerging technology (INCET) (IEEE), 1–5. doi: 10.1109/incet49848.2020.9153986
Naito, H., Ogawa, S., Valencia, M. O., Mohri, H., Urano, Y., Hosoi, F., et al. (2017). Estimating rice yield related traits and quantitative trait loci analysis under different nitrogen treatments using a simple tower-based field phenotyping system with modified single-lens reflex cameras. ISPRS J. Photogramm. Remote Sens. 125, 50–62. doi: 10.1016/j.isprsjprs.2017.01.010
Nakajima, K., Tanaka, Y., Katsura, K., Yamaguchi, T., Watanabe, T., Shiraiwa, T. (2023). Biomass estimation of World rice (Oryza sativa L.) core collection based on the convolutional neural network and digital images of canopy. Plant Prod. Sci. 26, 187–196. doi: 10.1080/1343943x.2023.2210767
Niu, Y., Zhang, L., Zhang, H., Han, W., Peng, X. (2019). Estimating above-ground biomass of maize using features derived from UAV-based RGB imagery. Remote Sens. 11 (11), 1261. doi: 10.3390/rs11111261
Ortiz-Ulloa, J. A., Abril-González, M. F., Pelaez-Samaniego, M. R., Zalamea-Piedra, T. S. (2021). Biomass yield and carbon abatement potential of banana crops (Musa spp.) in Ecuador. Environ. Sci. pollut. Res. 28, 18741–18753. doi: 10.1007/s11356-020-09755-4
Poley, G., McDermid, G. (2020). A systematic review of the factors influencing the estimation of vegetation aboveground biomass using unmanned aerial systems. Remote Sens. 12 (7), 1052. doi: 10.3390/rs12071052
Purushotam, N. K., Lakshmana Rao, V., Gunturu, C. S., Niharika, A., Anupama, C. R., Srivalli, G. (2023). Crop yield prediction using gradient boosting neural network regression model. Int. J. Recent Innov. Trends Comput. Commun. 11 (3), 206–214. doi: 10.17762/ijritcc.v11i3.6338
Radloff, F. G. T., Mucina, L. (2007). A quick and robust method for biomass estimation in structurally diverse vegetation. J. Veg. Sci. 18. doi: 10.1111/j.1654-1103.2007.tb02586.x
Sakamoto, T., Gitelson, A. A., Wardlow, B. D., Arkebauer, T. J., Verma, S. B., Suyker, A. E., et al. (2012). Application of day and night digital photographs for estimating maize biophysical characteristics. Precis. Agric. 13. doi: 10.1007/s11119-011-9246-1
Saleem, I., Mugloo, J. A., Pala, N. A., Bhat, G. M., Masoodi, T. H., Mughal, A. H., et al. (2023). Biomass production, carbon stock and sequestration potential of prominent agroforestry systems in north-western Himalaya, India. Front. For. Glob. Change 6, 1192382. doi: 10.3389/ffgc.2023.1192382
Schirrmann, M., Hamdorf, A., Garz, A., Ustyuzhanin, A., Dammer, K. H. (2016). Estimating wheat biomass by combining image clustering with crop height. Comput. Electron. Agric. 121, 374–384. doi: 10.1016/j.compag.2016.01.007
Schreiber, L. V., Atkinson Amorim, J. G., Guimarães, L., Motta Matos, D., da Costa, C., Parraga, A. (2022). Above-ground biomass wheat estimation: deep learning with UAV-based RGB images. Appl. Artif. Intell. 36 (1). doi: 10.1080/08839514.2022.2055392
Serouart, M., Madec, S., David, E., Velumani, K., Lopez Lozano, R., Weiss, M., et al. (2022). SegVeg: segmenting RGB images into green and senescent vegetation by combining deep and shallow methods. Plant Phenomics 2022. doi: 10.34133/2022/9803570
Sharma, P., Dadheech, P., Aneja, N., Aneja, S. (2023). Predicting agriculture yields based on machine learning using regression and deep learning. IEEE Access 11. doi: 10.1109/ACCESS.2023.3321861
Sharma, A., Khan, F., Sharma, D., Gupta, S. (2020). Python: the programming language of future. Int. J. Innov. Res. Technol. 6 (2), 115–118. Available online at: https://ijirt.org/Article?manuscript=149340.
Shrestha, N., Hu, H., Shrestha, K., Doust, A. N. (2023). Pearl millet response to drought: A review. Front. Plant Sci. 14. doi: 10.3389/fpls.2023.1059574
Srivastava, A. K., Safaei, N., Khaki, S., Lopez, G., Zeng, W., Ewert, F., et al. (2022). Winter wheat yield prediction using convolutional neural networks from environmental and phenological data. Sci. Rep. 12 (1), 3215. doi: 10.1038/s41598-022-06249-w
Tackenberg, O. (2007). A new method for non-destructive measurement of biomass, growth rates, vertical biomass distribution and dry matter content based on digital image analysis. Ann. Bot. 99 (4), 777–783. doi: 10.1093/aob/mcm009
Tang, Z., Guo, J., Xiang, Y., Lu, X., Wang, Q., Wang, H., et al. (2022). Estimation of leaf area index and above-ground biomass of winter wheat based on optimal spectral index. Agronomy 12 (7), 1729. doi: 10.3390/agronomy12071729
Taylor, J. R. N. (2015). “Millet Pearl: Overview,” in Encyclopedia of Food Grains: Second Edition. (Elsevier publication). doi: 10.1016/B978-0-12-394437-5.00011-5
Terefe, H., Argaw, M., Tamene, L., Mekonnen, K., Recha, J., Solomon, D. (2020). Sustainable land management interventions lead to carbon sequestration in plant biomass and soil in a mixed crop-livestock system: the case of Geda watershed, central highlands of Ethiopia. Ecol. Process. 9, 1–11. doi: 10.1186/s13717-020-00233-w
Trivedi, M., Gupta, A. (2021). Automatic monitoring of the growth of plants using deep learning-based leaf segmentation. Int. J. Appl. Sci. Eng. 18 (2), 1–9. doi: 10.6703/IJASE.202106_18(2).003
Tsaftaris, S. A., Minervini, M., Scharr, H. (2016). Machine learning for plant phenotyping needs image processing. Trends Plant Sci. 21 (12), 989–991. doi: 10.1016/j.tplants.2016.10.002
Tucker, C. J. (1979). Red and photographic infrared linear combinations for monitoring vegetation. Remote Sens. Environ. 8, 127–150. doi: 10.1016/0034-4257(79)90013-0
Van Der Walt, S., Schönberger, J. L., Nunez-Iglesias, J., Boulogne, F., Warner, J. D., Yager, N., et al. (2014). scikit-image: image processing in Python. PeerJ 2, e453. doi: 10.7717/peerj.453
Wang, D., Thunéll, S., Lindberg, U., Jiang, L., Trygg, J., Tysklind, M. (2022a). Towards better process management in wastewater treatment plants: Process analytics based on SHAP values for tree-based machine learning methods. J. Environ. Manage. 301. doi: 10.1016/j.jenvman.2021.113941
Wang, F., Yang, M., Ma, L., Zhang, T., Qin, W., Li, W., et al. (2022b). Estimation of above-ground biomass of winter wheat based on consumer-grade multi-spectral UAV. Remote Sens. 14 (5), 1251. doi: 10.3390/rs14051251
Woebbecke, D. M., Meyer, G. E., Bargen, K., Mortensen, D. A. (1995). Color indices for weed identification under various soil, residue, and lighting conditions. Trans. ASAE 38, 259–269. doi: 10.13031/2013.27838
Yang, K., Mo, J., Luo, S., Peng, Y., Fang, S., Wu, X., et al. (2023). Estimation of rice aboveground biomass by UAV imagery with photosynthetic accumulation models. Plant Phenomics 5. doi: 10.34133/plantphenomics.0056
Yu, D., Zha, Y., Sun, Z., Li, J., Jin, X., Zhu, W., et al. (2023). Deep convolutional neural networks for estimating maize above-ground biomass using multi-source UAV images: a comparison with traditional machine learning algorithms. Precis. Agric. 24 (1), 92–113. doi: 10.1007/s11119-022-09932-0
Yue, J., Yang, G., Li, C., Li, Z., Wang, Y., Feng, H., et al. (2017). Estimation of winter wheat above-ground biomass using unmanned aerial vehicle-based snapshot hyperspectral sensor and crop height improved models. Remote Sens. 9 (7), 708. doi: 10.3390/rs9070708
Zenkl, R., Timofte, R., Kirchgessner, N., Roth, L., Hund, A., Van Gool, L., et al. (2022). Outdoor plant segmentation with deep learning for high-throughput field phenotyping on a diverse wheat dataset. Front. Plant Sci. 12. doi: 10.3389/fpls.2021.774068
Zhai, W., Li, C., Cheng, Q., Mao, B., Li, Z., Li, Y., et al. (2023). Enhancing wheat above-ground biomass estimation using UAV RGB images and machine learning: multi-feature combinations, flight height, and algorithm implications. Remote Sens. 15 (14), 3653. doi: 10.3390/rs15143653
Zhang, L., Xu, Z., Xu, D., Ma, J., Chen, Y., Fu, Z. (2020). Growth monitoring of greenhouse lettuce based on a convolutional neural network. Hortic. Res. 7. doi: 10.1038/s41438-020-00345-6
Zheng, C., Abd-Elrahman, A., Whitaker, V. M., Dalid, C. (2022). Deep learning for strawberry canopy delineation and biomass prediction from high-resolution images. Plant Phenomics 2022, 9850486. doi: 10.34133/2022/9850486
Zheng, L., Chen, Q., Tao, J., Zhang, Y., Lei, Y., Zhao, J., et al. (2023). Estimation of aboveground biomass for winter wheat at the later growth stage by combining digital texture and spectral analysis. Agronomy 13 (3), 865. doi: 10.3390/agronomy13030865
Keywords: digital agriculture, deep learning, plant monitoring, carbon sequestration, CNN - convolutional neural network
Citation: Dhawi F, Ghafoor A, Almousa N, Ali S and Alqanbar S (2025) Predictive modelling employing machine learning, convolutional neural networks (CNNs), and smartphone RGB images for non-destructive biomass estimation of pearl millet (Pennisetum glaucum). Front. Plant Sci. 16:1594728. doi: 10.3389/fpls.2025.1594728
Received: 20 March 2025; Accepted: 11 April 2025;
Published: 06 May 2025.
Edited by:
Xing Yang, Anhui Science and Technology University, ChinaReviewed by:
Kavipriya J, SRM Institute of Science and Technology, IndiaBing Qian, Chinese Academy of Tropical Agricultural Sciences, China
Copyright © 2025 Dhawi, Ghafoor, Almousa, Ali and Alqanbar. This is an open-access article distributed under the terms of the Creative Commons Attribution License (CC BY). The use, distribution or reproduction in other forums is permitted, provided the original author(s) and the copyright owner(s) are credited and that the original publication in this journal is cited, in accordance with accepted academic practice. No use, distribution or reproduction is permitted which does not comply with these terms.
*Correspondence: Faten Dhawi, ZmFsbXVoYW5uYUBrZnUuZWR1LnNh; Abdul Ghafoor, YWdoYWZvb3JAa2Z1LmVkdS5zYQ==